

K-均值聚类算法
1. 什么是K均值聚类算法
K均值聚类(k-means)是基于样本集合划分的聚类算法。K均值聚类将样本集合划分为k个子集,构成k个类,将n个样本分到k个类中,每个样本到其所属类的中心距离最小,每个样本仅属于一个类,这就是k均值聚类,同时根据一个样本仅属于一个类,也表示了k均值聚类是一种硬聚类算法。
2:K均值聚类算法的过程
2.1 k均值聚类的算法过程
输入:n个样本的集合
输出:样本集合的聚类
过程:
(1)初始化。随机选择k的样本作为初始聚类的中心。
(2)对样本进行聚类。针对初始化时选择的聚类中心,计算所有样本到每个中心的距离,默认欧式距离,将每个样本聚集到与其最近的中心的类中,构成聚类结果。
(3)计算聚类后的类中心,计算每个类的质心,即每个类中样本的均值,作为新的类中心。
(4)然后重新执行步骤(2)(3),直到聚类结果不再发生改变。
K均值聚类算法的时间复杂度是O(nmk),n表示样本个数,m表示样本维数,k表示类别个数。


; 3:K均值聚类算法的习题
3.1 例题
五个样本的集合,使用K均值聚类算法,将五个样本聚于两类,五个样本分别是(0,2)(0,0)(1,0)(5,0)(5,2)。
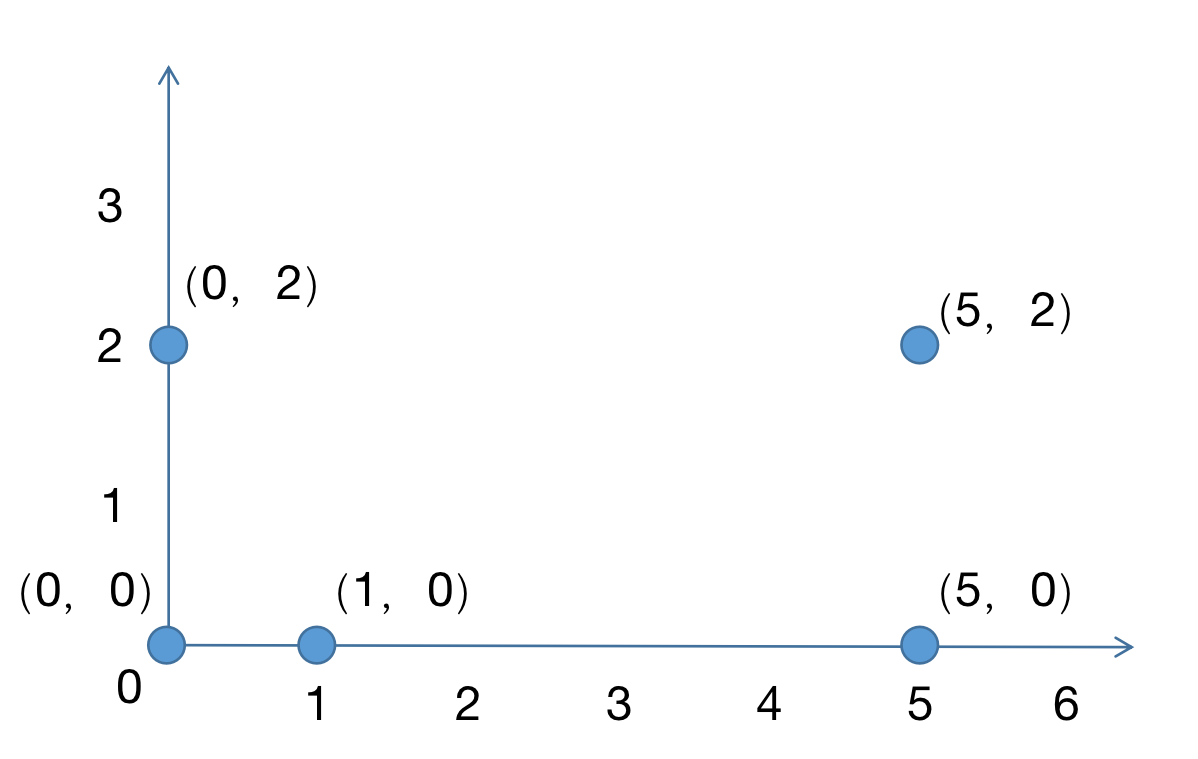
; 3.2 初始化
初始化。随机选择2个样本作为初始聚类的中心。
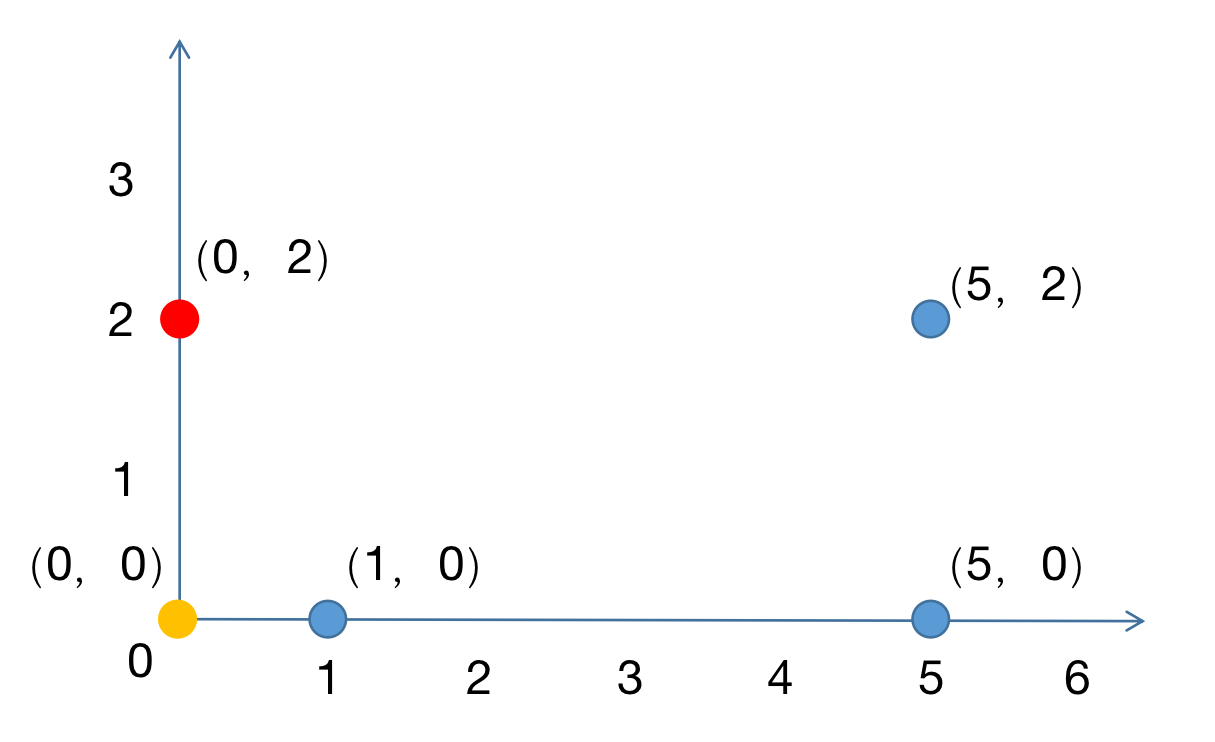
3.3 聚类
对样本进行聚类。计算每个样本距离每个中心的距离,将每个样本聚集到与其最近的中心的类中,构成两类。
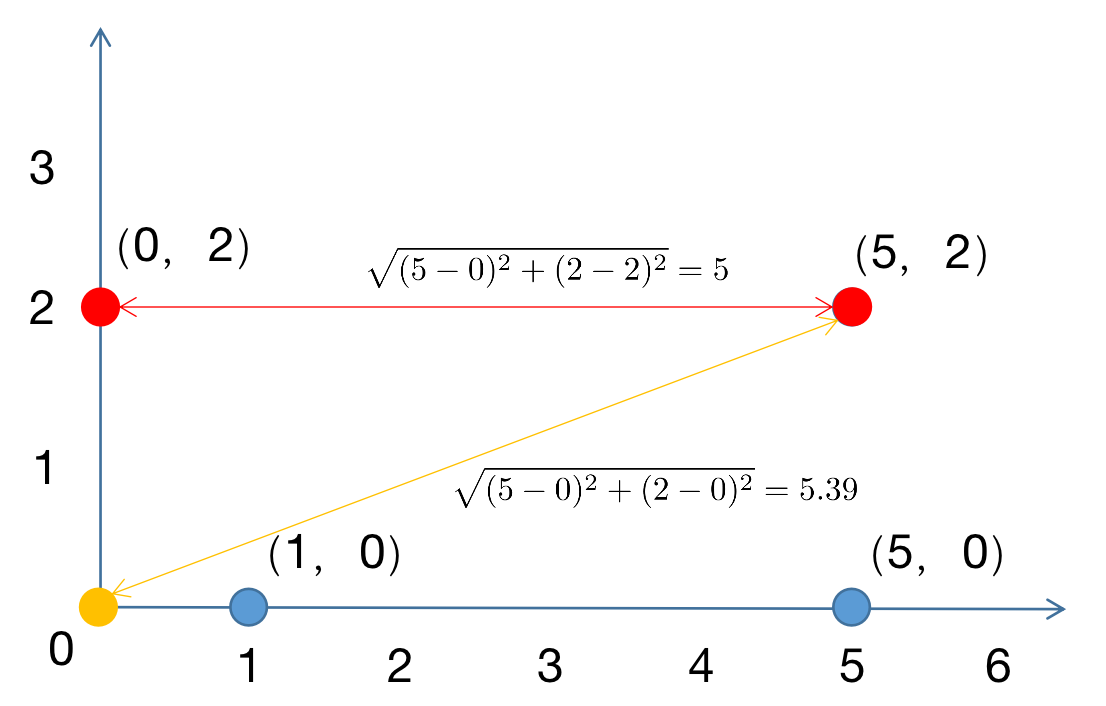
相同的方法对剩余两个点进行聚类,结果如下:
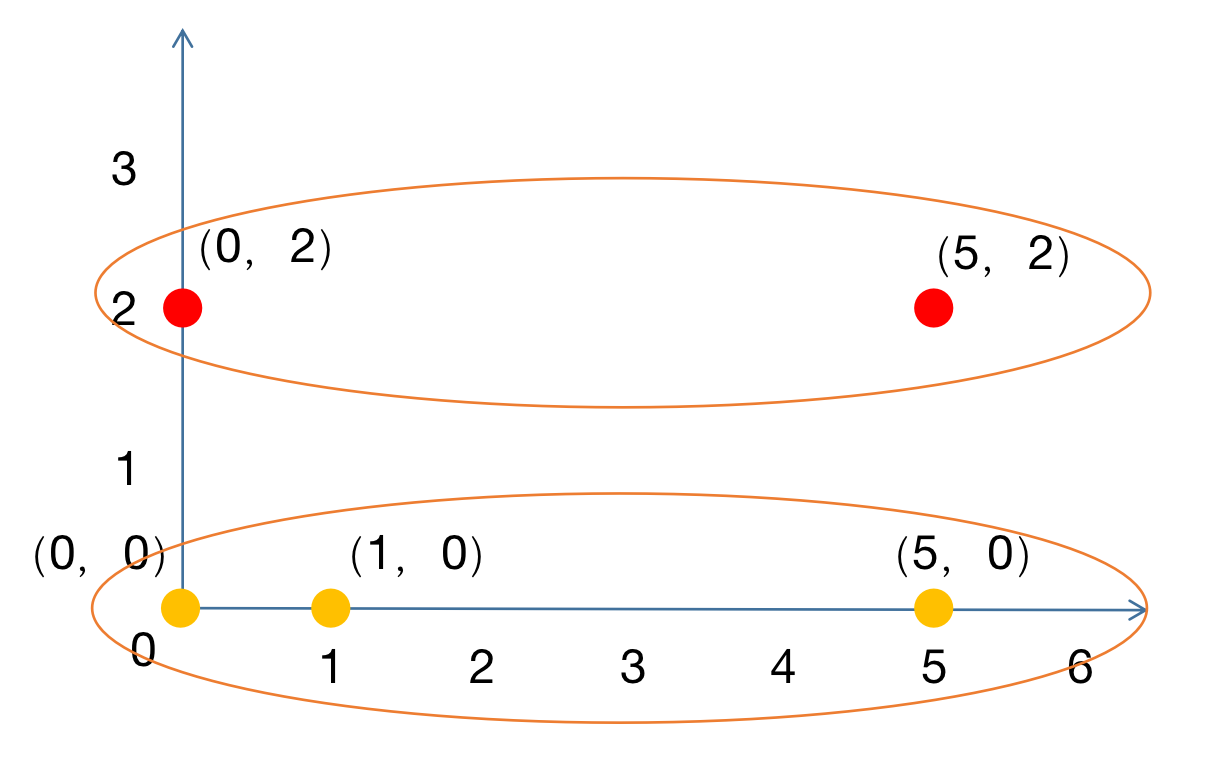
; 3.4 寻找新的类中心
计算新的类中心。对新的类计算样本的均值,作为新的类中心。
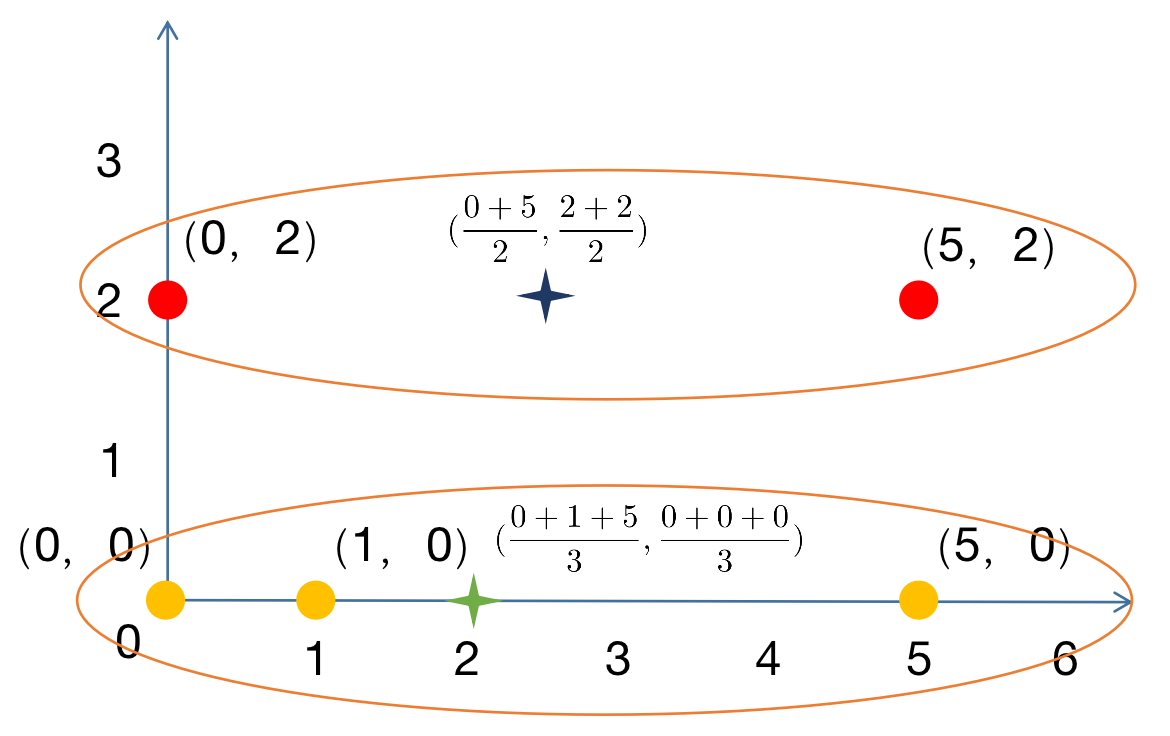
3.5 再次聚类
对样本进行聚类。计算每个样本距离每个中心的距离,将每个样本聚集到与其最近的中心的类中,构成新的类。
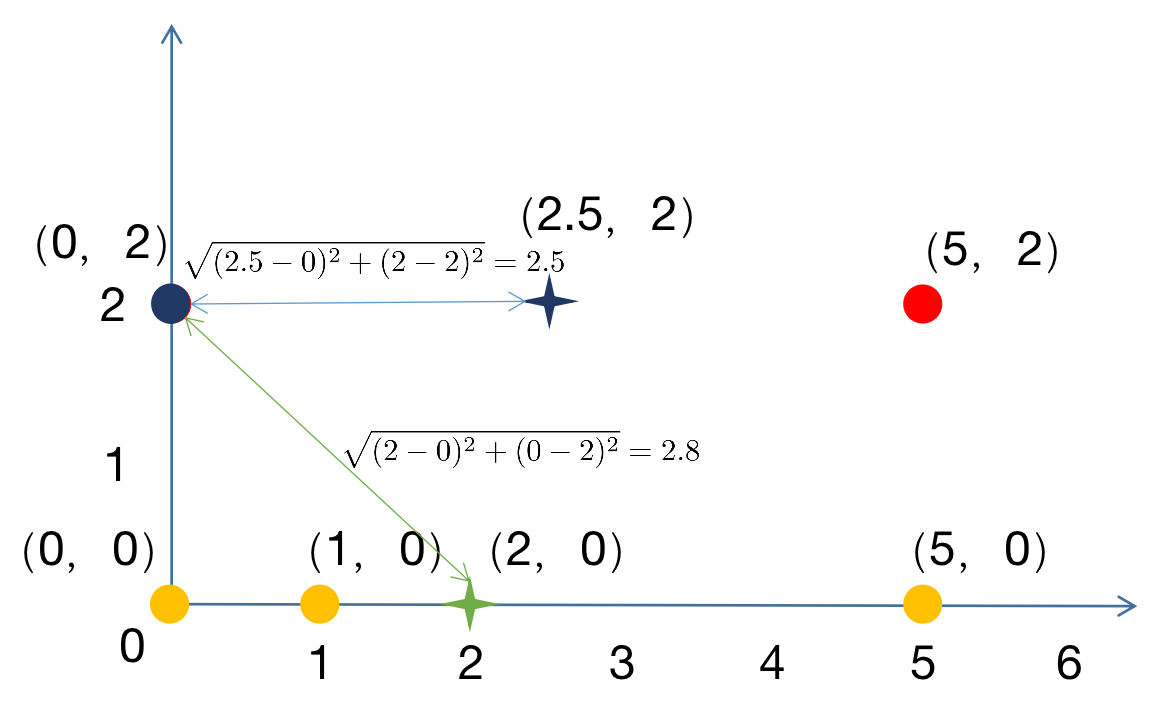
使用相同的方法对其余四个点进行聚类,结果如下:
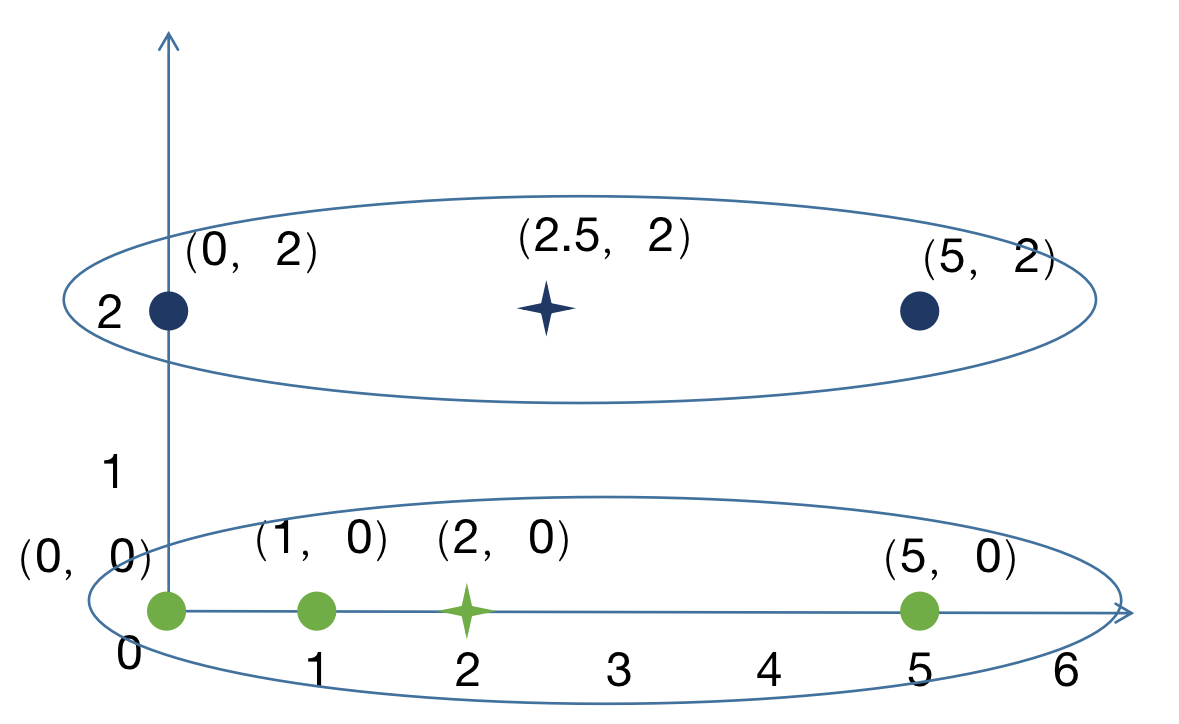
; 3.6 结果
第二次聚类结果与第一次聚类结果相同,则聚类停止。得到最终的结果。
3.7 例题

选择不同的初始中心,会得到不同的聚类结果。
4:K均值聚类算法的实现
4.1 K均值聚类算法
导入聚类库:
from sklearn.cluster import KMeans
聚类语法:
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='deprecated', verbose=0, random_state=None, copy_x=True, n_jobs='deprecated', algorithm='auto')
参数解释:
- n_clusters:簇的个数,即你想聚成几类
- init: 初始簇中心的获取方法
- n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最好的结果。
- max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
- tol: 容忍度,即kmeans运行准则收敛的条件
- precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的
- verbose: 冗长模式
- random_state: 随机生成簇中心的状态条件。
- copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。
- n_jobs: 并行设置
- algorithm: kmeans的实现算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式实现
属性:
- cluster_centers_:聚类中心点
- labels_:每个样本所属的聚类标签
- inertia_:样本到其最近的聚类中心的平方距离的总和
- n_iter_:运行的迭代次数
方法:
- fit(X[,y]):训练样本
- fit_predict(X[,y]):计算聚类中心并预测每个样本的聚类索引
- fit_transform(X[,y]):计算聚类并将X转换为聚类距离空间
- predict(X):预测X中每个样本所属的最近簇。
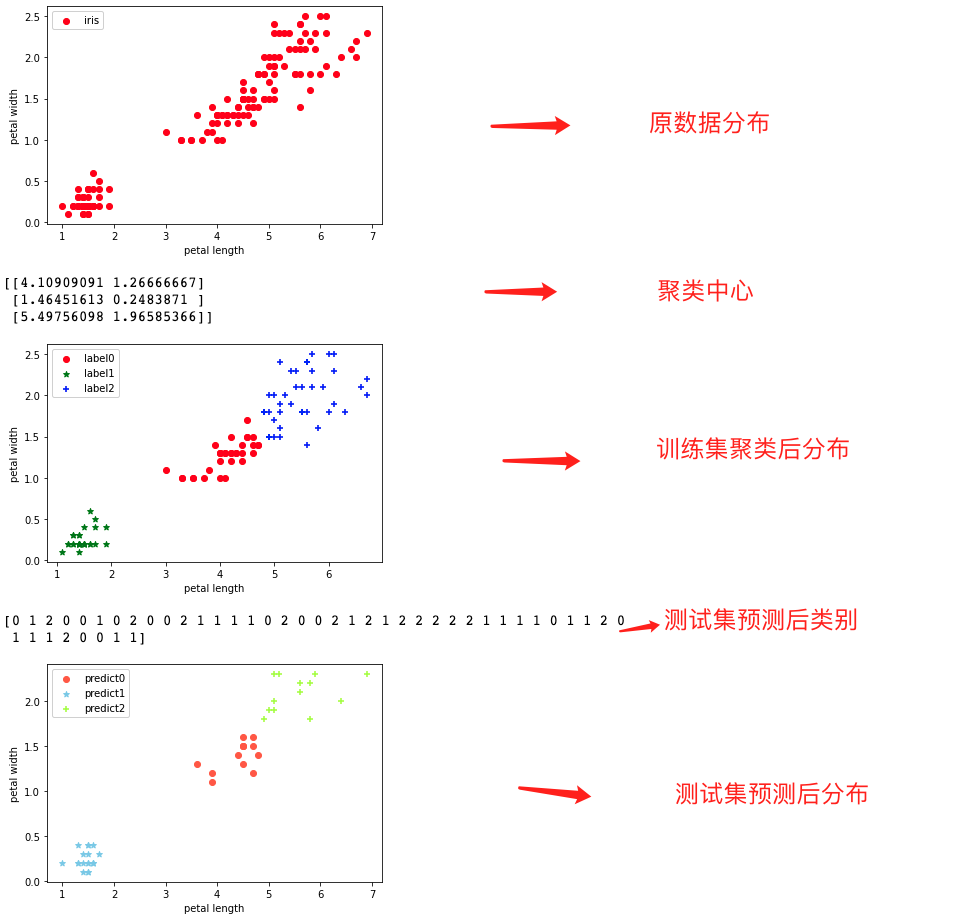
4.2 对鸢尾花数据进行聚类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris=load_iris()
X = iris.data[:, 2:4]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
plt.scatter(X[:, 0], X[:, 1], c = "red", marker='o', label='iris')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
estimator = KMeans(n_clusters=3)
estimator.fit(X_train)
label_pred = estimator.labels_
print(estimator.cluster_centers_)
x0 = X_train[label_pred == 0]
x1 = X_train[label_pred == 1]
x2 = X_train[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker='+', label='label2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
print(estimator.predict(X_test))
predict_0=X_test[estimator.predict(X_test) == 0]
predict_1=X_test[estimator.predict(X_test) == 1]
predict_2=X_test[estimator.predict(X_test) == 2]
plt.scatter(predict_0[:, 0], predict_0[:, 1], c = "tomato", marker='o', label='predict0')
plt.scatter(predict_1[:, 0], predict_1[:, 1], c = "skyblue", marker='*', label='predict1')
plt.scatter(predict_2[:, 0], predict_2[:, 1], c = "greenyellow", marker='+', label='predict2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
Original: https://blog.csdn.net/weixin_41418263/article/details/113313507
Author: Chloe-Hao
Title: K均值聚类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549442/
转载文章受原作者版权保护。转载请注明原作者出处!