

Linux定时器分为低精度定时器和高精度定时器两种类型,内核对其均有实现。本文讨论的是我们在应用程序开发中比较常见的低精度定时器。作为常用的基础组件,定时器常用的几种实现方法包括:基于排序链表实现、基于小根堆实现、基于红黑树实现、基于时间轮实现。本文讲解的是时间复杂度最优,也是linux内核采用的基于时间轮的实现方式。
-
有序队列
-
添加/删除任务: 遍历每一个节点, 找到相应的位置插入, 因此时间复杂度为O(n)
-
处理到期任务: 取出最小定时任务为首节点, 因此时间复杂度为O(1)
-
红黑树
有序队列的性能瓶颈在于插入任务和删除任务(查找排序), 而树形结构能对其进行优化。 -
添加/删除/查找任务: 红黑树能将排序的的时间复杂度降到O(log2N)
-
处理到期任务: 红黑树查找到最后过期的任务节点为最左侧节点, 因此时间复杂度为O(log2N)
-
最小堆
-
添加/查找任务: 时间复杂度为O(log2N)
- 删除任务: 时间复杂度为O(n), 可通过辅助数据结构(map)来加快删除操作
-
处理到期任务: 最小节点为根节点, 时间复杂度为O(1)
-
跳表
-
添加/删除/查找任务: 时间复杂度为O(log2N)
- 处理到期任务: 最小节点为最左侧节点, 时间复杂度为O(1), 但空间复杂度比较高, 为O(1.5n)
之所以没法做到O(1)的复杂度,究其原因是所有定时器节点挂在一条链表(或一棵树)上。 时间轮算法的核心思路是将定时器散列到多条链上(定时器就是指定时任务,链上的节点),是典型的空间换时间的策略。下文从单个时间轮出发讲解,逐步扩展至 linux实现定时器所采用的多级时间轮算法。
简单的单时间轮
单时间轮只有一个由bucket串起来的轮子,下图所示的时间轮有8个bucket,每个bucket下链接着未来对应时刻到期的节点。假设图中相邻bucket到期时间的间隔为slot=1s,从当前时刻0s开始计时,1s时到期的定时器节点挂在bucket[1]下,2s时到期的定时器节点挂在bucket[2]下……当tick检查到时间过去了1s时,bucket[1]下所有节点执行超时动作,当时间到了2s时,bucket[2]下所有节点执行超时动作…….


由于bucket是一个数组,能直接根据下标定位到具体定时器节点链,因此添加删除节点、定时器到期执行的时间复杂度均为O(1)。(有Hash内味了)
但使用这个定时器所受的限制也显而易见:待添加的timer到期时间必须在8s以内。这显然不能满足实际需求。当然要扩展也很容易,直接增加bucket的个数就可以了。在 Linux 系统中,我们可以设置slot为1个jiffy(1/HZ)的定时器,假设最大的到期时间范围要达到 2^32个 jiffies,如果采用上面这样的单时间轮,我们就需要2^32个 bucket,这会带来巨大的内存消耗,显然是需要优化改进的。
改进的单时间轮
改进的单时间轮其实是一个对时间和空间折中的思路,即不会像单时间轮那样有O(1)的时间复杂度,但也不会像单时间轮那样对bucket个数有巨大的需求。其原理也很简单,就是每个bucket不单可以挂接到期时间expire=slot的定时器,还可挂接expire%N=slot的定时器(N为bucket个数)。这也正好顺应时间轮的轮回作用。如图2所示,定时器中expire表示到期时间, rotation表示节点在时间轮转了几圈后才到期。当当前时间指针指向某个bucket时,不能像简单时间轮那样直接对bucket下的所有节点执行超时动作,而是需要对链表中节点遍历一遍,判断轮子转动的次数是否等于节点中的rotation值,当两者相等时,方可执行超时操作。
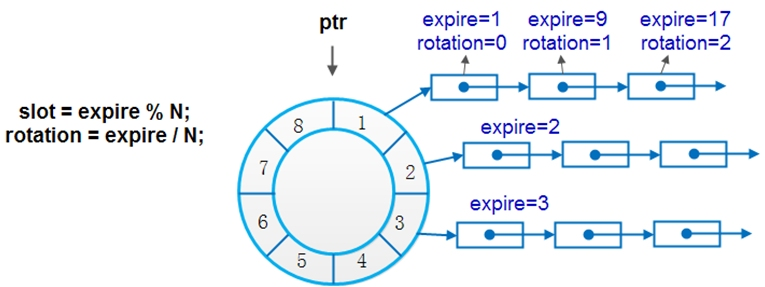
我们的uthread项目就是这种改进型的单时间轮,效果也很好,不过我们使用的单链表,但在一些开源实现里使用的双向链表,是因为有其他场景(reset,惰性删除等)
多时间轮
上面所述的时间轮都是单枪匹马战斗的,因此很难在时间和空间上都达到理想效果。Linux所实现的多时间轮算法,借鉴了日常生活中水表的度量方法,通过低刻度走得快的轮子带动高一级刻度轮子走动的方法,达到了仅使用较少刻度即可表示很大范围度量值的效果。
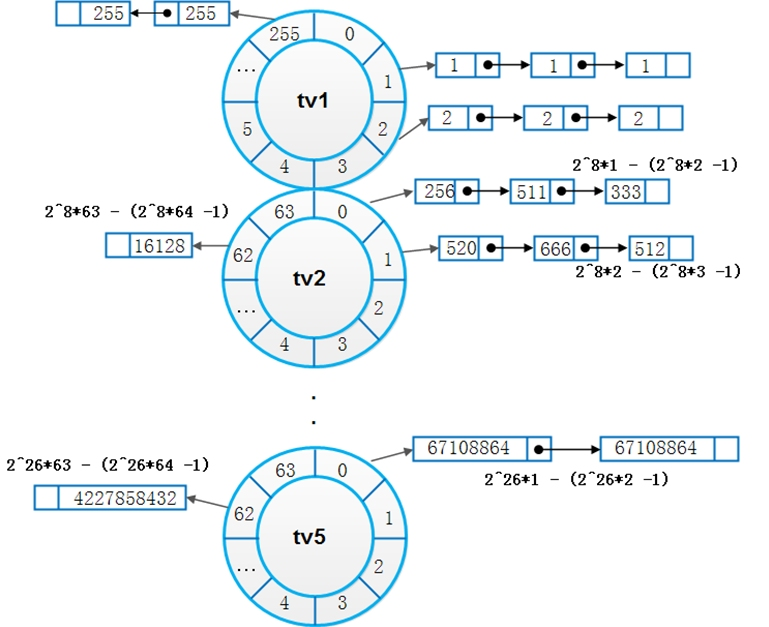
Linux定时器时间轮分为5个级别的轮子(tv1 ~ tv5),如图3所示。每个级别的轮子的刻度值(slot)不同,规律是次级轮子的slot等于上级轮子的slot之和。Linux定时器slot单位为1jiffy,tv1轮子分256个刻度,每个刻度大小为1jiffy。tv2轮子分64个刻度,每个刻度大小为256个jiffy,即tv1整个轮子所能表达的范围。相邻轮子也只有满足这个规律,才能达到”低刻度轮子转一圈,高刻度轮子走一格”的效果。tv3,tv4,tv5也都是分为64个刻度,因此容易算出,最高一级轮子tv5所能表达的slot范围达到了25664646464 = 2^32 jiffies。
Linux时间轮定时器算法的关键在于添加定时器操作和时间轮进位迁移链表操作。先来说添加定时器。添加定时器的关键又在于知道每个时间轮每一个刻度所能表示的到期时间的范围。图4列出了每一级时间轮能度量的jiffies的大小。假设有一个定时器在1000个jiffies后到期,根据图4容易看出其应该挂在tv2轮上。tv2轮每个刻度表示的大小为256个jiffies,则其应该挂在(1000/256)=3即第三个bucket上。因此可以O(1)的添加定时器。
Linux在定时器到期检查上的操作也实现得很巧妙。假设curr_time=0x12345678,那么下一个检查的时刻为0x12345679。如果tv1.bucket[0x79]上链表非空,则下一个检查时刻tv1.bucket[0x79]上的定时器节点超时。如果curr_time到了0x12345700,低8位为空,说明有进位产生,这时移出8~13位对应的定时器链表(即正好对应着tv2轮),重新加入定时器系统(放到tv1轮),这就完成了一次进位迁移操作。同样地,当curr_time的第8-13位为0时,这表明tv2轮对tv3轮有进位发生,将curr_time第14-19位的值作为下标,移出tv3中对应的定时器链表,然后将它们重新加入到定时器系统中来(放到tv2或tv1)。tv4,tv5依次类推。遍历 tv1中该 tick 的双向循环链表,执行这些到期定时器的回调函数。之所以能够根据curr_time来检查超时链,是因为tv1~tv5轮的度量范围正好依次覆盖了整型的32位:tv1(1-8位),tv2(9-14位),tv3(15-20位),tv4(21-26位),tv5(27-32位);而curr_time计数的递增中,低位向高位的进位正是低级时间轮转圈带动高级时间轮走动的过程。
这里有一个实现细节,我们用一个int就能表示这5级时间轮:
| 6bit | 6bit | 6bit | 6bit | 8bit |
111111 111111 111111 111111 11111111
这样的话有一个优点,每次只需要将这个int整数+1,每一级时间轮都会自动进位。
对比
最后比较一下多级时间轮和单个简单时间轮的时间复杂度及空间复杂度:linux使用了总计256+64+64+64+64=512个bucket,即可实现[0,2^32) jiffies的超时范围。相比简单的单时间轮,时间上仅仅多了1/256次(为约等于值,忽略了tv2以上产生的进位操作)的链表迁移操作耗时。可以认为其添加、删除定时器节点及到期check的操作时间复杂度均为O(1)。
参考链接:
1. CSDN-时间轮定时器实现
2. 浪的不轻-多级时间轮定时器
3. changan’s blog-linux定时器时间轮算法
Original: https://www.cnblogs.com/lfri/p/15917019.html
Author: Rogn
Title: 定时器时间轮算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549218/
转载文章受原作者版权保护。转载请注明原作者出处!