



论文链接:[2111.06377] Masked Autoencoders Are Scalable Vision Learners (arxiv.org)
论文标题: Masked Autoencoders Are Scalable Vision Learners
指的是(屏蔽自编码器是可扩展的视觉学习器),其中这里的 Autoencoders指的是模型的输入和输出都是相同的,简单来说 Autoencoder=encoder+decoder
发表于: CVPR2021
摘要
本文表明,掩码自编码器 (MAE) 是用于计算机视觉的可扩展自监督学习器。我们的 MAE 方法很简单:我们屏蔽输入图像的随机块并重建丢失的像素。它基于两个核心设计。首先,我们开发了非对称编码器 – 解码器架构,其中编码器仅在补丁的可见子集上运行(没有掩码标记),以及从潜在表示和掩码标记重建原始图像的轻量级解码器。其次,我们发现屏蔽大部分输入图像(例如 75%)会产生重要且有意义的自我监督任务。结合这两种设计使我们能够高效地训练大型模型:我们加速训练(3 倍或更多)并提高准确性。我们的可扩展方法允许学习泛化良好的高容量模型:例如,在仅使用 ImageNet-1K 数据的方法中,vanilla ViT-Huge 模型实现了最佳准确率 (87.8%)。下游任务中的传输性能优于有监督的预训练,并显示出有希望的扩展行为
1、介绍
深度学习见证了能力和容量不断增长的架构的爆炸式增长[29,25,52]。 在硬件快速增长的帮助下,今天的模型很容易过拟合一百万张图像 [13] 并开始需要数亿张(通常无法公开访问的)标记图像 [16]。
通过自我监督的预训练,这种对数据的需求已经在自然语言处理 (NLP) 中成功解决。 基于 GPT [42,43,4] 中的自回归语言建模和 BERT [14] 中的掩码自动编码的解决方案在概念上很简单:它们删除了一部分数据并学习预测删除的内容。 这些方法现在可以训练包含超过一千亿个参数的可泛化 NLP 模型 [4]。
掩码自编码器的想法是一种更通用的去噪自编码器 [53],在计算机视觉中也很自然且适用。 事实上,与视觉密切相关的研究 [54,41] 早于 BERT。 然而,尽管在 BERT 成功之后人们对这个想法产生了浓厚的兴趣,但视觉中自动编码方法的进展落后于 NLP。 我们问:是什么使视觉和语言之间的掩码自动编码不同? 我们尝试从以下几个角度来回答这个问题:
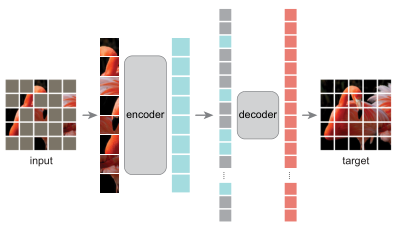
图一:我们的 MAE 架构。 在预训练期间,大量随机的图像块子集(例如 75%)被屏蔽掉。 编码器应用于可见补丁的小子集。 在编码器之后引入掩码标记,完整的编码块和掩码标记集由一个小型解码器处理,以像素为单位重建原始图像。 预训练后,解码器被丢弃,编码器应用于未损坏的图像(完整的补丁集)以进行识别任务。
1、直到最近,架构还是不同的。 在视觉方面,卷积网络 [30] 在过去十年中占主导地位 [29]。 卷积通常在规则网格上运行,将”指标”(例如掩码标记 [14] 或位置嵌入 [52])集成到卷积网络中并不容易。 然而,随着 Vision Transformer (ViT) [16] 的引入,这种架构差距已经得到解决,并且不应再成为障碍。2、语言和视觉之间的信息密度不同。 语言是人类生成的具有高度语义和信息密集度的信号。 当训练一个模型来预测每个句子只预测几个遗漏的单词时,这个任务似乎会诱导复杂的语言理解。 相反,图像是具有大量空间冗余的自然信号——例如,可以从相邻的补丁中重新覆盖缺失的补丁,而对零件、对象和场景的高级理解很少。 为了克服这种差异并鼓励学习有用的特征,我们展示了一个简单的策略在计算机视觉中效果很好:屏蔽随机补丁的每一部分。 这种策略在很大程度上减少了冗余,并创建了一项具有挑战性的自我监督任务,需要超越低级图像统计的整体理解。 要对我们的重建任务有一个定性的认识,请参见图 2-4。3、自动编码器的解码器将潜在表示映射回输入,在重建文本和图像之间扮演不同的角色。 在视觉中,解码器重建像素,因此其输出的语义级别低于普通识别任务。 这与语言相反,在语言中,解码器预测包含丰富语义信息的缺失词。 虽然在 BERT 中,解码器可能很简单(MLP)[14],但我们发现,对于图像,解码器设计在确定学习到的潜在表示的语义级别方面起着关键作用。

图二: ImageNetvalidationimages 上的示例结果。 对于每个三元组,我们显示了掩码图像(左)、我们的 MAE reconstruction†(中)和地面实况(右)。 掩蔽率为 80%,196 个补丁中只剩下 39 个。 更多例子在附录中。 †由于没有在可见块上计算损失,可见块上的模型输出质量更差。 人们可以简单地用可见补丁覆盖输出以提高视觉质量。 我们故意选择不这样做,所以我们可以更全面地展示该方法的行为。

图三:COCO 验证图像的示例结果,使用在 ImageNet 上训练的 MAE(与图 2 中的模型权重相同)。观察最右边的两个示例的重建,虽然与地面实况不同,但在语义上是合理的。
在此分析的推动下,我们提出了一种简单、有效且可扩展的掩码自编码器 (MAE) 形式,用于视觉表示学习。 我们的 MAE 从输入图像中屏蔽了随机补丁,并在像素空间中重建丢失的补丁。 它具有不对称编码器-解码器设计。 我们的编码器只对可见的补丁子集进行操作(没有掩码标记),我们的解码器是轻量级的,可以根据掩码标记重建潜在表示的输入(图 1)。 在我们的非对称编码器-解码器中将掩码标记转移到小型解码器导致计算量大幅减少。在这种设计下,非常高的掩码率(例如 75%)可以实现双赢:它优化了准确性,同时 – 降低编码器只处理一小部分(例如 25%)的补丁。 这可以将整体预训练时间减少 3 倍或更多,同样减少内存消耗,使我们能够轻松地将 MAE 扩展到大型模型。
我们的 MAE 学习非常高容量的模型,这些模型可以很好地泛化。 通过 MAE 预训练,我们可以在 ImageNet-1K 上训练 ViT-Large/-Huge [16] 等需要大量数据的模型,并提高泛化性能。 使用普通的 ViT-Huge 模型,我们在 ImageNet-1K 上微调时达到了 87.8% 的准确率。 这优于之前仅使用 ImageNet-1K 数据的所有结果。 我们还评估了对象检测、实例分割和语义分割的转移学习。 在这些任务中,我们的预训练比其监督预训练对手取得了更好的结果,更重要的是,我们通过扩大模型观察到了显着的收益。 这些观察结果与 NLP 中自监督预训练的观察结果一致 [14,42,43,4],我们希望它们能让我们的领域探索类似的轨迹。

图4.使用 MAE 重建 ImageNetvalidationimages,该 MAE 以 75% 的掩蔽率进行预训练,但应用于具有更高掩蔽率的输入。 预测与原始图像似乎不同,表明该方法可以泛化。
2.相关工作
掩码语言建模及其自回归对应部分,例如 BERT [14] 和 GPT [42,43,4],是非常成功的 NLP 预训练方法。 这些方法保留一部分输入序列并训练模型来预测缺失的内容。 这些方法已被证明具有出色的扩展性 [4],并且大量证据表明这些预训练的表示可以很好地推广到各种下游任务。
自编码是学习表示的经典方法。 它有一个将输入映射到潜在表示的编码器和一个重构输入的解码器。 例如,PCA 和 k-means 是自动编码器 [26]。 去噪自编码器 (DAE) [53] 是一类自编码器,它破坏输入信号并学习重建原始的、未损坏的信号。 一系列方法可以被认为是不同损坏下的广义 DAE,例如,屏蔽像素 [54,41,6] 或去除颜色通道 [64]。我们的 MAE 是一种去噪自编码形式,但与经典 DAE 不同 以多种方式。
掩码图像编码方法从被掩码损坏的图像中学习表示。 [54] 的开创性工作将掩蔽作为 DAE 中的一种噪声类型。 上下文编码器 [41] 使用卷积网络修复大的缺失区域。 受 NLP 成功的启发,最近相关的方法 [6,16,2] 基于 Transformers [52]。 iGPT [6] 对像素序列进行操作并预测未知像素。 ViT 论文 [16] 研究了用于自监督学习的掩码补丁预测。 最近,BEiT [2] 建议预测离散标记 [39,45]。
自监督学习方法对计算机视觉产生了浓厚的兴趣,通常侧重于不同的预训练任务 [15,55,37,64,40,17]。 最近,对比学习 [3,22] 很流行,例如 [56,38,23,7],它对两个或多个视图之间的图像相似性和不相似性(或仅相似性 [21,8])进行建模 . 对比和相关方法强烈依赖于数据增强 [7,21,8]。 自动编码追求一个概念上不同的方向,它表现出我们将要展示的不同行为。
3.方法
我们的掩码自编码器 (MAE) 是一种简单的自编码方法,可以在给定部分观察的情况下重建原始信号。 与所有自动编码器一样,我们的方法有一个将观察到的信号映射到潜在表示的编码器,以及一个从潜在表示重建原始信号的解码器。 与经典的自动编码器不同,我们采用不对称设计,允许编码器仅对部分观察信号(无掩码标记)进行操作,并采用轻量级解码器从潜在表示和掩码标记重新构建完整信号。 图 1 说明了这个想法,接下来介绍。
Masking.Following ViT [16],我们将图像划分为规则的非重叠补丁。 然后我们对补丁的子集进行采样并屏蔽(即删除)剩余的补丁。 我们的采样策略很简单:我们在不替换的情况下随机采样,遵循均匀分布。 我们简单地将其称为”随机抽样”。
具有高掩蔽率(即移除补丁的比率)的随机采样在很大程度上消除了冗余,从而创建了一项无法通过从可见相邻补丁外推来轻松解决的任务(见图 2-4)。 均匀分布可防止潜在的中心偏差(即在图像中心附近有更多被屏蔽的补丁)。 最后,高度稀疏的输入为设计高效编码器创造了机会,接下来介绍。
MAE 编码器。我们的编码器是 ViT [16],但只应用在可见的、未屏蔽的补丁上。 就像在标准 ViT 中一样,我们的编码器通过添加位置嵌入的线性投影嵌入补丁,然后通过一系列 Transformer 块处理结果集。 然而,我们的编码器只对整个集合的一小部分(例如 25%)进行操作。屏蔽补丁被删除; 不使用掩码令牌。 这使我们能够仅使用一小部分计算和内存来训练非常大的编码器。 全套由轻量级解码器处理,如下所述。
MAE 解码器。 MAE 解码器的输入是完整的令牌集,包括 (i) 编码的可见补丁和 (ii) 掩码令牌。 见图1。 每个掩码标记 [14] 是一个共享的、学习的向量,表示存在要预测的缺失补丁。 我们为这个完整集合中的所有标记添加了位置嵌入; 如果没有这个,掩码令牌将没有关于它们在图像中的位置的信息。 解码器有另一系列的 Transformer 模块。
MAE 解码器仅在预训练期间用于执行图像重建任务(仅使用编码器生成用于识别的图像表示)。 因此,可以以独立于编码器设计的方式灵活地设计解码器架构。 我们用非常小的解码器进行实验,比编码器更窄更浅。 例如,我们的默认解码器每个 tokenvs 的计算量小于 10%。 编码器。 通过这种非对称设计,全套令牌仅由轻量级解码器处理,这显着减少了预训练时间。
重建目标。我们的 MAE 通过预测每个蒙版块的像素值来重建输入。 解码器输出中的每个元素都是一个表示补丁的像素值向量。 解码器的最后一层是线性投影,其输出通道数等于补丁中的像素值数。 解码器的输出被重新整形以形成重建的图像。 我们的损失函数计算像素空间中重建图像和原始图像之间的均方误差 (MSE)。 我们仅在掩码补丁上计算损失,类似于 BERT [14].1
我们还研究了一个变体,其重建目标是每个蒙版块的归一化像素值。 具体来说,我们计算一个补丁中所有像素的均值和标准差,并使用它们来规范化这个补丁。 在我们的实验中,使用归一化像素作为重建目标可以提高表示质量。
简单的实现。我们的 MAE 预训练可以有效地实现,重要的是,不需要任何专门的稀疏操作。 首先,我们为每个输入补丁生成一个标记(通过线性投影和添加的位置嵌入)。 接下来,我们根据掩蔽率随机打乱令牌列表并删除列表的最后一部分。 这个过程为编码器生成了一小部分令牌,相当于在没有替换的情况下采样补丁。 编码后,我们将掩码标记列表附加到编码补丁列表中,并解散这个完整列表(反转随机洗牌操作)以将所有标记与其目标对齐。 解码器应用于此完整列表(添加了位置嵌入)。 如前所述,不需要稀疏操作。 这个简单的实现引入的开销可以忽略不计,因为 shuffling 和 unshuf-fling 操作很快。

图5. 掩蔽率,高掩蔽率 (75%) 适用于微调(顶部)和线性探测(底部)。 y 轴是本文所有图中的 ImageNet-1K 验证准确率 (%)。
Experiments
我们在ImageNet-1K数据集上进行自监督预训练,然后再通过监督训练评估预训练模型的表达能力。
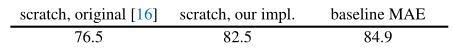
Baseline:ViT-Large 。我们采用ViT-Large作为消融实验的骨干,上表为从头开始训练与MAE微调的性能对比。可以看到:从头开始训练(200epoch),ViT-L的性能为82.5%且无需强正则技术;而MAE(注:仅微调50epoch)则取得了大幅性能提升。
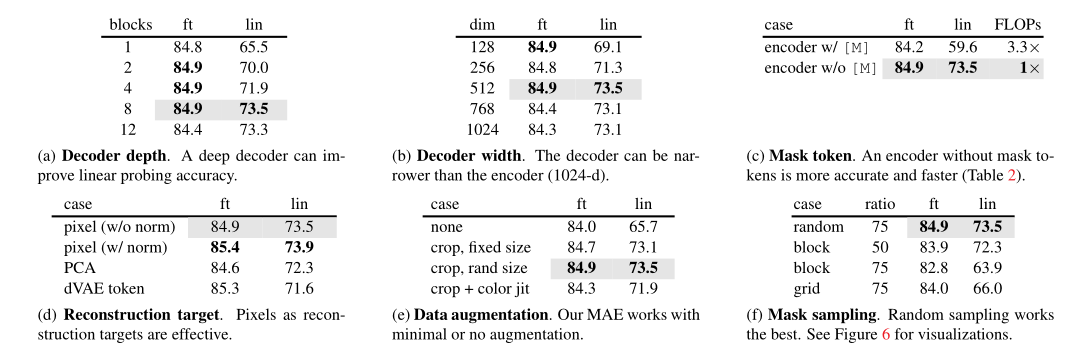
表1. 在 ImageNet-1K 上使用 ViT-L/16 进行 MAE 消融实验。 我们报告了微调 (ft) 和线性探测 (lin) 的准确度 (%)。 如果不指定,默认为:解码器深度为8,宽度为512,重构目标为非归一化像素,数据增强为随机resize裁剪,掩蔽率为75%,预训练长度为800个epoch。 默认设置标记为 inray。
Decoder Design 从Table1(a)与Table1(b)可以看到: 解码器的设计可以非常灵活 。总而言之,默认解码器非常轻量,仅有8个模块,维度为512,每个token的计算量仅为编码的9%。
- Decoder depth:decoder 的深度对 linear probing 影响很大, 因为 decoder 越深,那么训练时过程中会使它的浅层对应的特征与预训练的重建任务越无关,也就是越抽象,利于迁移。而 finetune 因为会在新任务上重新学习,所以深度对他影响要小很多。
- Decoder width:decoder的宽度对 linear probing 影响很大, 对finetune 影响很小。
- 所以作者最后的模型选择 finetune 方式迁移到下游任务,且采用比较浅比较窄的 decoder(8 个 blocks, 512-d width), 这样能够加速且省显存。
Mask Token MAE的的重要设计:在编码阶段跳过掩码token,在解码阶段对其进行处理。Table1(c)给出了性能对比,可以看到: 编码器使用掩码token则会导致性能下降 。
- encoder 是否使用 mask token:文中取可见 patches 的方式是对输入的所有 patch (假设一共有 N 个patch)先 shuffle 一下, 然后把后 N * masking_ratio 的 patch 丢掉,只有前面部分过网络。
- 另一种可能的方法是在 encoder 那增加一个 mask token 指代哪些 patch 需要保留哪些不需要保留。 实验结果表明这样做效果明显变差了, 原因使用 mask encoding 在训练时模型见到的是一些残缺的输入, 但是在实际下游任务中见到的确实完整的输入, 这会带来很大的 gap。
Recontruction target 重建目标 Table1(d)比较了不同重建目标的性能:1. 直接对原始像素重建;2. 以 patch 内像素的统计量对 patch 做 norm 后的像素重建;3.PCA 后重建; 4. dVAE。可以看到: 引入块归一化可以进一步提升模型精度 。
Data Augmentation 数据增广 Table1(e)比较了不同数据增广的影响,可以看到: MAE仅需crop即可表现非常好,添加ColorJitter反而会影响性能 。另外,令人惊讶的是: 当不使用数据增广时,MAE性能也非常优秀 。
Mask Sampling Table1(f)比较了不同掩码随机采样策略,可以看到:不同的采样策略均具有比较好的性能,而 随机采样则具有最佳性能 。
Masking ratio 下图给出了掩码比例的影响,可以看到: 最优比例惊人的高 。掩码比例为75%有益于两种监督训练方式(端到端微调与linear probing)。这与BERT的行为截然相反,其掩码比例为15%。

图6. 掩码采样策略决定了借口任务的难度,影响了重建质量和表示(表 1f)。 这里的每个输出都来自使用指定掩蔽策略训练的 MAE。 左:随机抽样(我们的默认设置)。 中间:逐块采样 [2],删除大的随机块。右侧:网格采样,保留每四个补丁之一。图像来自验证集。
与此同时,从上图可以看到:端到端微调与linear probing两种方式存在不同的趋势:
- 对于linear probing而言,模型性能随掩码比例非常稳定的提升直到达到最高点,精度差约为20%;
- 对于微调来说,模型性能再很大范围的掩码比例内均极度不敏感,而且所有微调结果均优于linear probing方式。
Training Schedule 下图给出了不同训练机制的性能对比(此时采用了800epoch预训练),可以看到: 更长的训练可以带来更定的精度提升 。作者还提到:哪怕1600epoch训练也并未发现linear probing方式的性能饱和。 这与MoCoV3中的300epoch训练饱和截然相反 :在每个epoch,MAE仅能看到25%的图像块;而MoCoV3则可以看到200%,甚至更多的图像块。
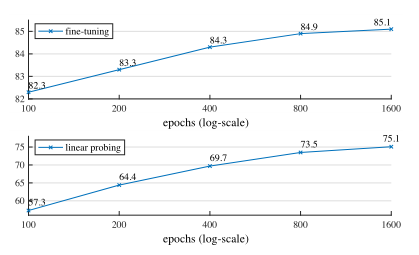
图7. 训练时间表。 更长的训练计划会带来显着的改善。 这里的每个点都是一个完整的训练计划。 模型为 ViT-L,默认设置见表 1。
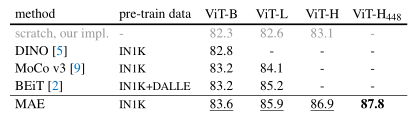
表3. 与之前在 ImageNet-1K 上的结果的比较。 预训练数据是 ImageNet-1K 训练集(除了 BEiT 中的分词器是在 250M DALLE 数据上预训练的 [45])。 所有自监督方法都通过端到端的微调进行评估。 ViT 型号为 B/16、L/16、H/14 [16]。 每列的最佳值带有下划线。 所有结果都在 224 的图像大小上,除了 ViT-H 的额外结果是 448。这里我们的 MAE 重建归一化像素并预训练了 1600 个时期。
上表给出了所提MAE与其他自监督方案的性能对比,从中可以看到:
- 对于ViT-B来说,不同方案的性能非常接近;对于ViT-L来说,不同方案的性能差异则变大。这意味着: 对更大模型降低过拟合更具挑战性 。
- MAE可以轻易的扩展到更大模型并具有稳定的性能提升。比如: ViT-H取得了86.9%的精度,在448尺寸微调后,性能达到了87.8% ,超越了此前VOLO的最佳87.1%(尺寸为512)。注:该结果仅使用了ViT,更优秀的网络表达可能会更好。
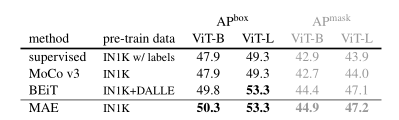
表4. 使用 ViT Mask R-CNN 基线的 COCO 对象检测和分割。 所有条目均基于我们的实现。 自监督条目使用无标签的 IN1K 数据。 掩码 AP 遵循与盒式 AP 类似的趋势 。
上表给出了COCO检测与分割任务上的迁移性能对比,可以看到: 相比监督预训练,MAE取得了全配置最佳 。当骨干为ViT-B时,MAE可以取得2.4AP指标提升;当骨干为ViT-L时,性能提升达4.0AP。
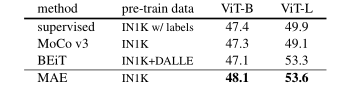
表5. ADE20K 语义分割 (mIoU) 使用 Uper-Net。 BEiT结果使用官方代码复现。 其他条目基于我们的实现。 自监督条目使用无标签的 IN1K 数据。
6.讨论和结论
可扩展的简单算法是深度学习的核心。 在 NLP 中,简单的自监督学习方法(例如 [42,14,43,4])可以从指数缩放模型中获益。 在计算机视觉中,尽管自监督学习取得了进展,但实际的预训练范式主要受到监督(例如 [29,46,25,16])。 在这项研究中,我们在 ImageNet 和迁移学习中观察到自动编码器——一种类似于 NLP 技术的简单自我监督方法——提供了可扩展的好处。 视觉中的自监督学习现在可能走上与 NLP 类似的轨迹。
另一方面,我们注意到图像和语言是不同性质的信号,必须谨慎处理这种差异。 图像只是记录的光,没有语义分解成单词的视觉类比。 我们不是尝试移除对象,而是移除最有可能不形成语义段的随机补丁。 同样,我们的 MAE 重建像素,它们不是语义实体。 尽管如此,我们观察到(例如,图 4)我们的 MAE 推断出复杂的、整体的重建,表明它已经学习了许多视觉概念,即语义。 我们假设这种行为是通过 MAE 内部丰富的隐藏表示发生的。 我们希望这个观点能激发未来的工作。
更广泛的影响。所提出的方法根据训练数据集的学习统计数据预测内容,因此将反映这些数据中的偏差,包括具有负面社会影响的偏差。 该模型可能会生成不存在的内容。 在基于这项工作生成图像时,这些问题值得进一步研究和考虑。
如何看待何恺明最新一作论文Masked Autoencoders?
来源:知乎
如何看待何恺明最新一作论文Masked Autoencoders? – 田永龙的回答 – 知乎 https://www.zhihu.com/question/498364155/answer/2220207439
如何看待何恺明最新一作论文Masked Autoencoders? – 苏剑林的回答 – 知乎 https://www.zhihu.com/question/498364155/answer/2239991489
如何看待何恺明最新一作论文Masked Autoencoders? – Bowen Cheng的回答 – 知乎 https://www.zhihu.com/question/498364155/answer/2219792200
如何看待何恺明最新一作论文Masked Autoencoders? – 田柯宇的回答 – 知乎 https://www.zhihu.com/question/498364155/answer/2219887558
Original: https://blog.csdn.net/qq_42014059/article/details/121954068
Author: MT_Joy
Title: Masked Autoencoders Are Scalable Vision Learners(屏蔽自编码器是可扩展的视觉学习器)–文献翻译和笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548778/
转载文章受原作者版权保护。转载请注明原作者出处!