



©PaperWeekly 原创 · 作者 |王馨月
学校 |四川大学本科生
研究方向 |自然语言处理

概要
本文针对自然语言处理的新范式——我们称之为”prompt-based 学习”,进行了综述与组织。

论文标题:
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
论文作者:
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig
论文链接:
https://arxiv.org/abs/2107.13586
区别于传统的监督学习中训练模型接受输入 x 并将输出 y 预测为 P(y|x),Prompt-based 学习基于直接对文本概率进行建模的语言模型。为了使用这些模型执行预测任务,使用模板将原始输入 x 修改为具有一些未填充槽的文本字符串 prompt x’,然后使用语言模型对未填充信息进行概率填充以获得最终字符串 x ,从中可以导出最终输出 y。
这个框架强大且有吸引力的原因有很多:它允许语言模型在大量原始文本上进行预训练,并且通过定义一个新的 prompting 函数,模型能够执行少样本甚至零样本学习,可以适应很少或没有标记数据的新场景。
在本文中,我们介绍了这种有发展前途的范式的基础知识,描述了一组统一的数学符号,可以涵盖现有的很多工作;并沿多个维度组织现有工作,例如预训练模型的选择、prompt 和调整策略。为了让感兴趣的初学者更容易接触到该领域,我们不仅对现有工作以及基于 prompt 的概念的高度结构化类型进行了系统综述和,还发布了其他资源,在这个网站中包含了持续更新的综述以及论文列表:
http://pretrain.nlpedia.ai/


引言
NLP 的两次巨变
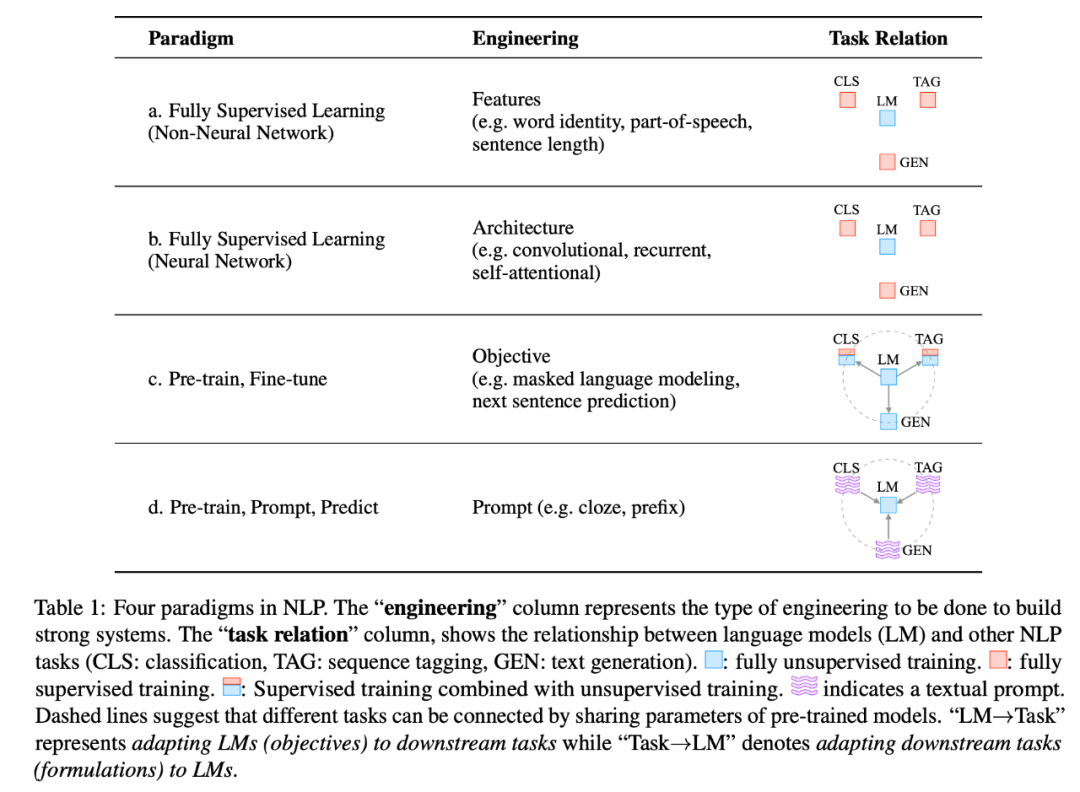
第一次巨变是”pre-train and fine-tune” 范式,第二次巨变则是目前的 “pre-train, prompt, and predict”。如图,是 NLP 中的四种范式。
Prompting 的正式描述
在传统的 NLP 监督学习系统中,我们采用输入 x(通常是文本),并基于模型 预测输出 y。y 可以是标签、文本或其他各种输出。为了学习这个模型的参数 ,我们使用一个包含输入和输出对的数据集,并训练一个模型来预测这个条件概率。
监督学习的主要问题是,为了训练模型 ,必须有任务的监督数据,而对于许多任务来说,这些数据是无法大量获取的。Prompt-based 学习方法试图通过学习一个语言模型(LM)来规避这个问题,该 LM 对文本 x 本身的概率 进行建模,并使用该概率来预测 y,从而减少或消除了对于大型监督数据集的需求。
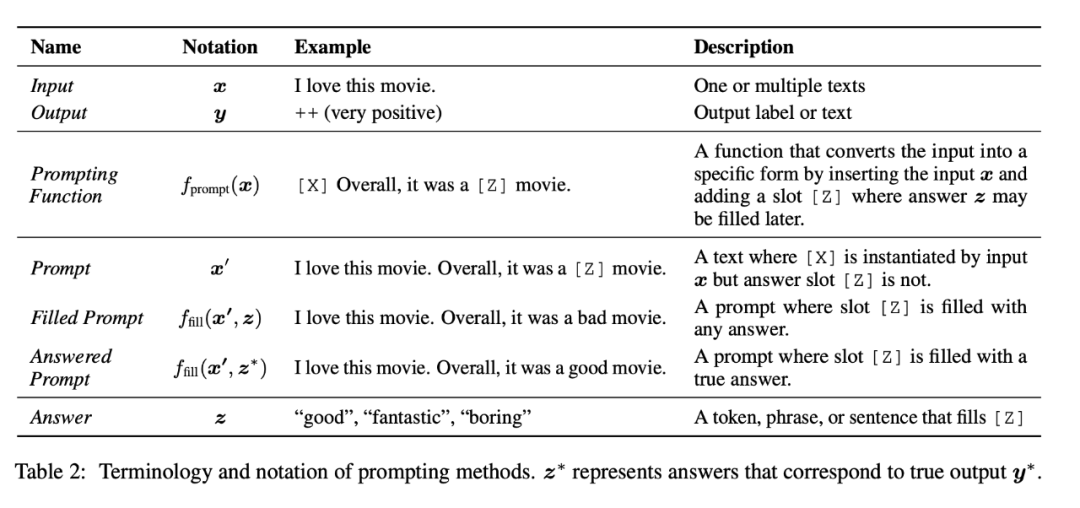
在本节中,我们对最基本的提示形式进行了数学描述,其中包含许多有关 prompt 的工作,并且可以扩展以涵盖其他内容。具体来说,基本 prompt 分三步预测得分最高的 。分别为:
- prompt 添加:通过 将输入文本转化为一个 prompt
- 回答搜索:找到能将 LM 分数最大化的得分最高的文本
- 回答mapping:通过得分最高的回答 ,得到得分最高的输出
如图所示,是 Prompt 方法的一些术语和符号表示。
Prompting 设计过程中的注意事项
有了基本的数学公式后,还需要了解一些基本设计注意事项:
- 预训练模型选择:有多种预训练 LM 可用于计算 。对于 Prompt 方法在效用维度存在差异。
- Prompt 工程:鉴于 prompt 指定了任务,选择合适的 prompt 不仅对准确性有很大影响,而且对模型首先执行的任务也有很大影响;
- 回答工程:根据任务的不同,我们可能希望设计不同的 Z,可能与映射函数一起设计;
- 扩展范式:如上所述,上述等式仅代表已被提议用于执行此类 prompt 的各种基础框架中最简单的。还有一些扩展这种基本范式以进一步提高结果或适用性的方法;
- 基于 prompt 的训练策略:有训练参数的方法,包括 prompt 和 LM。
Prompt 方法分类
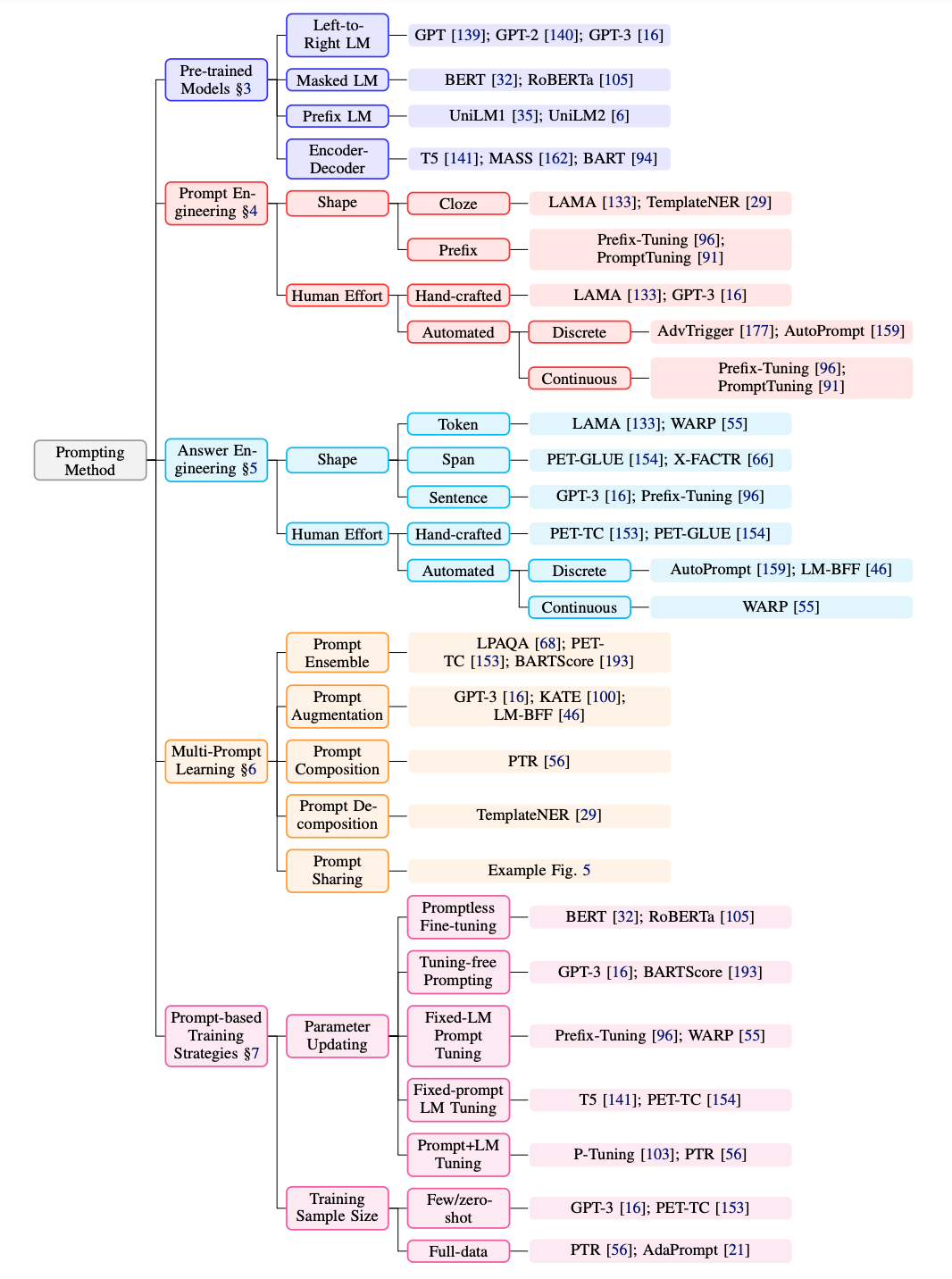
Prompt 方法分类


总结
在本文中,作者总结并分析了统计自然语言处理技术发展中的几个范式,并认为 Prompt-based 学习是一种很有前途的新范式,它可能代表着我们看待 NLP 方式的另一个重大变化。
作者在原文中列出了详细的表格、实例甚至 timeline 以帮助读者更加直观地了解这一新范式,非常值得阅读原文。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是 最新论文解读,也可以是 学术热点剖析、 科研心得或 竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人 原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供 业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信( pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在 「知乎」也能找到我们了
进入知乎首页搜索 「PaperWeekly」
点击 「关注」订阅我们的专栏吧
·

Original: https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/119336766
Author: PaperWeekly
Title: CMU预训练模型最新综述:自然语言处理新范式—预训练、Prompt和预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548716/
转载文章受原作者版权保护。转载请注明原作者出处!