

前言
近两年来,对比学习在图像领域大火,在NLP领域也出现了一些利用对比学习的工作。对比学习的一般思想是构造正样例(与原样例语义相似的样例)和负样例(与原样例语义不相似的样例),通过设计对比损失函数,缩小语义相似样例在表示空间中的距离,增大语义不相似的样例在表示空间中的距离,起到类似聚类的效果。关于对比学习,可以参考下面两篇文章。
哈工大SCIR-对比学习
对白-对比学习在CV与NLP领域的进展
这篇博客记录了几篇将对比学习应用于文本摘要任务的论文,是个人的阅读笔记,仅供个人学习使用。
CONTRASTIVE LEARNING WITH ADVERSARIAL PER-TURBATIONS FOR CONDITIONAL TEXT GENERATION
Link:
https://arxiv.org/pdf/2012.07280.pdf
Motivation
seq2seq模型被广泛的应用在文本生成任务中,seq2seq模型在训练时往往采用teacher-focing的方法。这样就造成训练和测试阶段的不一致,训练时每个时间步输入的是真实label,而测试时看不到真实的token,每个时间步输入的是模型之前生成的token,这样容易导致错误,并且错误会一直积累下去,从而严重影响文本生成的质量,这个问题称为exposure-bias问题。针对这个问题,可以采用对比学习的方法,构造正例和负例,模型在训练时,不仅可以看到真实的标签,还可以看到错误的生成的tokens,从而有效缓解exposure-bias的问题。最简单的对比学习方法就是直接随机的选取非目标的序列作为负样本,但是这种做法并不好,因为随机选取的负样例非常容易被区分,特别是对于大规模的预训练模型来说。这篇文章利用对抗扰动(adversarial perturbations)的方法构造正负样例,使得负样例与目标序列在embedding空间上相似,但是在语义上非常不同,正样例与目标序列在embedding空间上非常不同,但是在语义上很相似,从而增加了正负样例区分的难度,使得模型学习的更加充分。这篇文章在机器翻译,摘要,问答三个任务上测试,发现设计的模型取得很好的效果。
Method
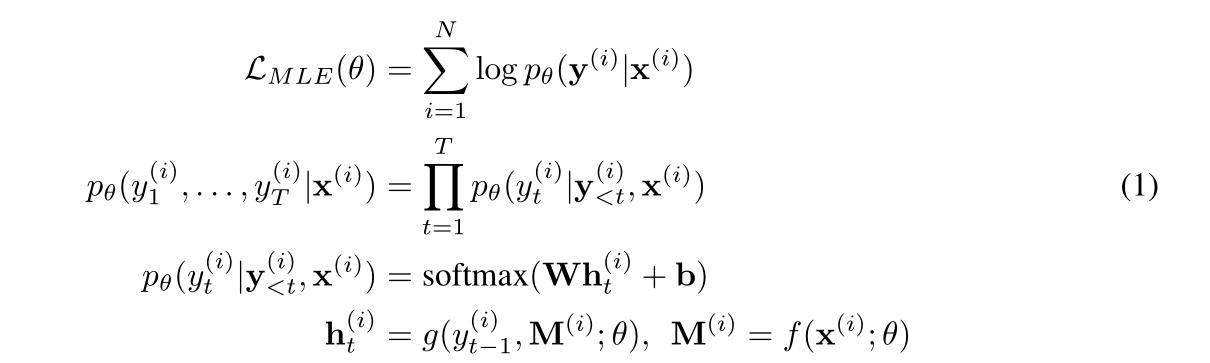

其中f代表encoder,d代表decoder,M是源序列编码后的向量表示。
传统的seq2seq文本生成存在exposure-bias问题,因此文章引入对比学习方法,文章同时构造了正样例和负样例
对于负样例,构造方法如下图所示
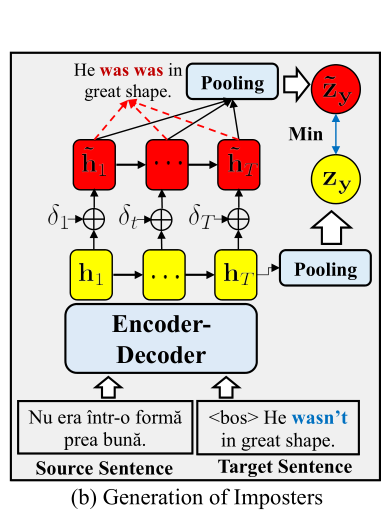
首先为目标序列的隐向量表示H施加一个微小的扰动δ \delta δ,得到一个新的向量表示,使得对应的条件似然(conditional likelihood)最小,从而使得构造负样例在embedding上与目标序列相似,但是在语义上与目标序列非常不同。构造公式如下面的公式3所示。这个式子本身不可解,可以利用 ( Goodfellow,2015)中的方法线性近似,如公式4所示
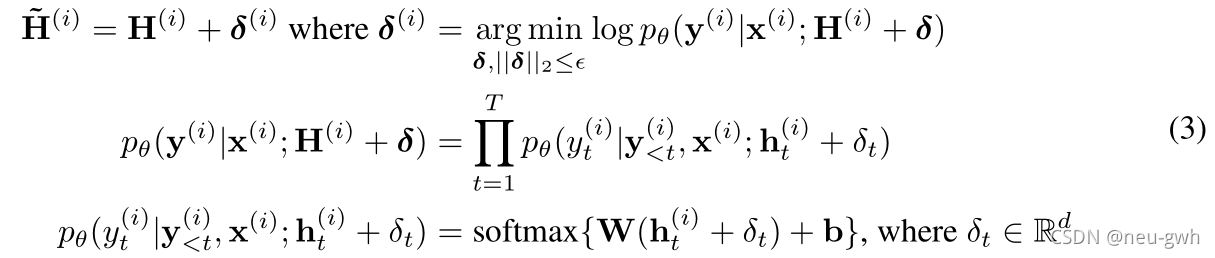
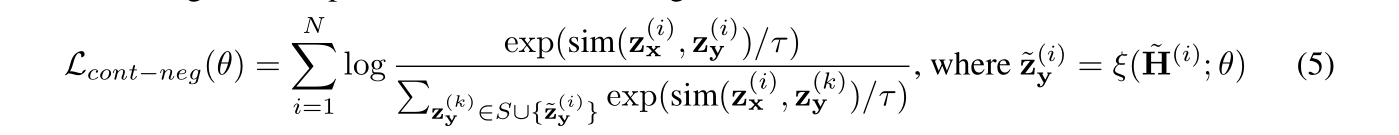
这个目标函数的分子代表拉近源序列和目标序列在表示空间中的距离,分母代表推远源序列和构造的负样例在表示空间中的距离。
对于正样例,构造方法如下图:
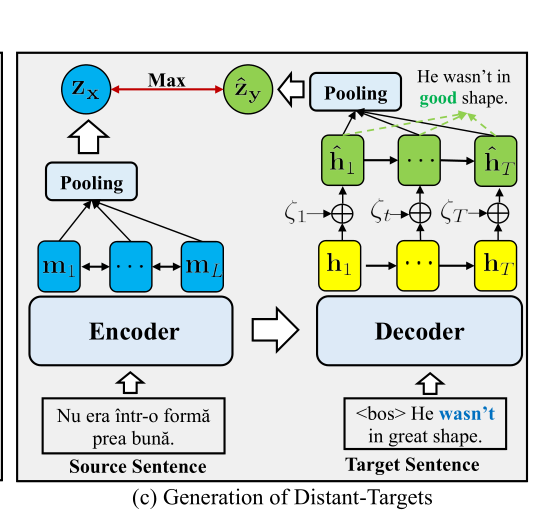
首先为目标序列的隐向量表示增加一个大的扰动,使得构造的样例在embedding空间中与目标序列距离很远,同时通过最小化构造后样例的条件概率分布与原来条件概率分布的KL距离,来最大化构造的正样例的似然,使得构造的正样例在embedding上与源序列很远,但是在语义上与源序列相似。
具体的构造公式如下。这里做了两步近似。首先通过添加一个扰动,使得对比目标函数最小,这一步的目标是增大构造样例与源序列在表示空间中的距离。第二步在这个又添加了一个扰动,使得对应的KL距离最小。
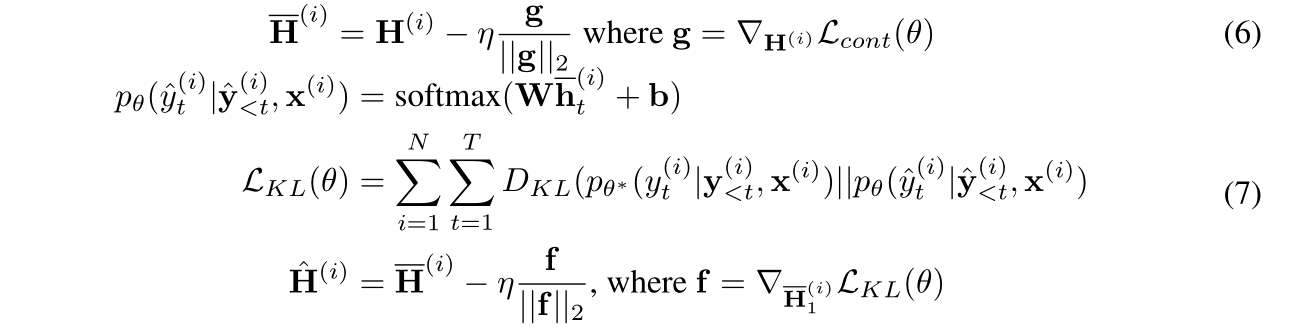
最后构造正样例的目标函数,计算公式如下,分子使得构造的正样例与源序列的距离尽量近,分母使得构造的负样例与源序列的距离尽量远。
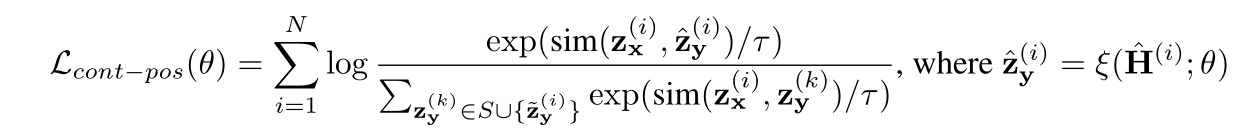
最后总的目标函数如下:
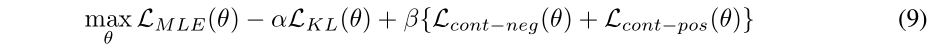
; Code:
https://github.com/seanie12/CLAPS
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
Link
https://aclanthology.org/2021.acl-short.135/
Motivation
生成式文本摘要往往采用seq2seq模型的方法,这种方法存在两个问题,一方面学习的目标函数和最终的评价指标不一致,目标函数使用最大似然函数,是字符级别的,而评价指标是ROUGE等,都是句子级别的。另一方面,由于训练时使用teacher-forcing,存在上篇文章说的exposure-bias问题。在这篇文章中。作者提出了SimCLS模型,与上一篇文章不同,这篇文章将摘要生成和对比学习分离开,分为两个阶段,首先训练seq2seq模型,利用最大似然估计生成候选摘要,然后利用对比学习训练模型,对候选摘要进行reference-free的评价,选出最佳的摘要。
Method
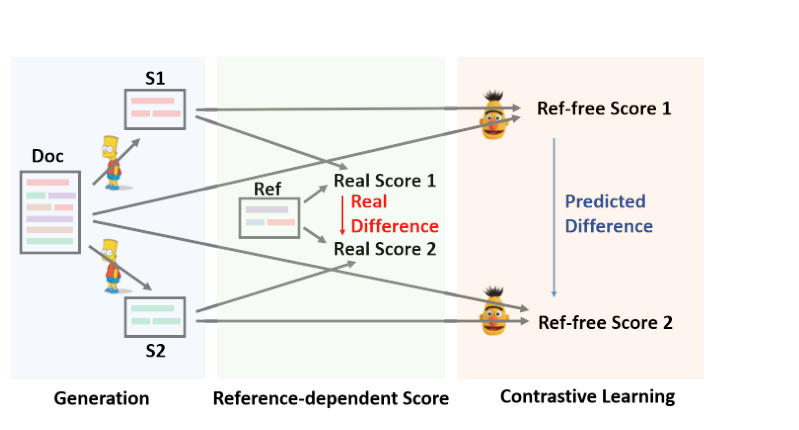
上图给出了模型的总体架构,首先通过预训练的seq2seq模型(BART等)生成摘要,这里利用beam-search生成多个候选摘要,然后再用对比学习的方法训练RoBERTa模型,用训练好的模型对候选摘要进行reference-free的evaluation,为每个候选摘要计算一个与源文档的相关性得分,选出得分最高的摘要。
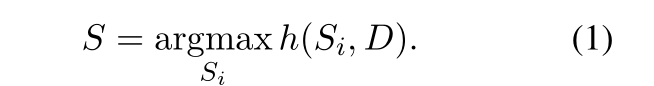
用对比学习方法训练rank模型,这里没有像一般的对比学习方法那样构造正例,负例,这里的对比反映在不同的候选摘要S i S_i S i 与D D D的相关性得分上,对比损失如下:
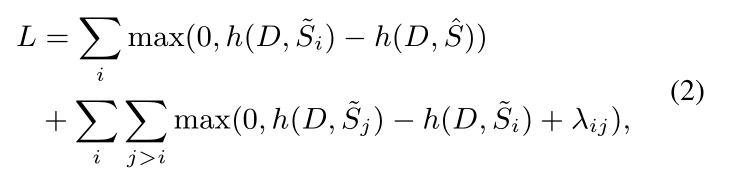
这里的S ^ \hat{S}S ^代表参考摘要,S ~ 1 , ⋯ , S ~ n \tilde{S}{1}, \cdots, \tilde{S}{n}S ~1 ,⋯,S ~n 代表生成的候选摘要,按照ROUGE得分降序排序。
; Code:
https://github.com/yixinL7/SimCLS
Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
Link
https://arxiv.org/abs/2108.11992
Motivation
seq2seq模型对于噪声(data corruption,distribution shift)等不够robust,这篇文章通过结合多种形式的句子级别的数据增强和对比学习,设计了一个seq2seq的文本摘要模型,提高了模型的去噪能力。
Method
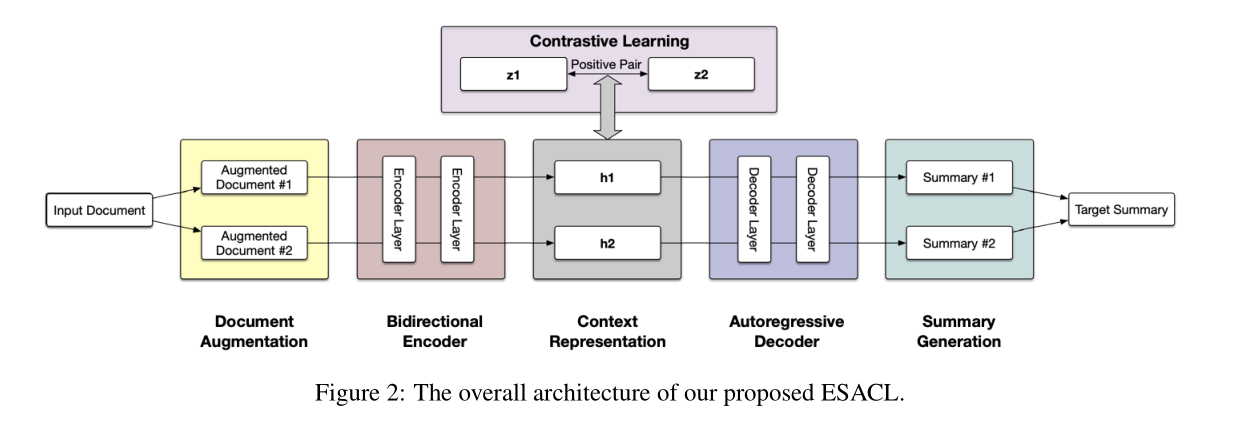
上图给出了模型的总体架构。首先对于给定的文档d,通过句子级别的数据增强得到一对增强后的文档,保留大部分的语义的同时引入噪声。这里的增强方法共有四种:Random Insertion (RI)、Random Swap (RS)、Random Deletion (RD)、Document Rotation(DR)。
对于一个包含k个文档的batch b = d 1 , d 2 , . . . d k b=d_1,d_2,…d_k b =d 1 ,d 2 ,…d k ,每个文档通过增强得到两个文档,一共得到2k个文档,由同一文档增强得到的两个文档构成一对正例,有不同文档增强得到的文档构成负例。将增强后的文档通过编码器编码得到隐向量表示h,同时通过一个非线性映射层g将h投影到另一个隐空间z = g ( h ) z=g(h)z =g (h ),用来计算对比损失函数,计算公式如下:
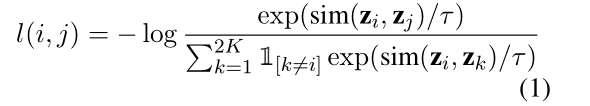
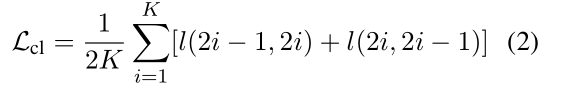
最后利用解码器分别为增强后的文档生成摘要,与原始文档的摘要对比,通过交叉熵函数计算损失L generate \mathcal{L}_{\text {generate }}L generate
最终的损失函数为
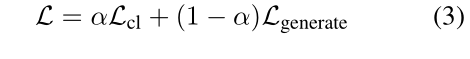
; Code
https://github.com/chz816/esacl
Original: https://blog.csdn.net/sdauguanweihong/article/details/120038239
Author: neu-gwh
Title: 对比学习文本摘要论文阅读笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548638/
转载文章受原作者版权保护。转载请注明原作者出处!