

LSTM是RNN的升级版,加了门控装置,解决了长时记忆依赖的问题。但由于门控装置复杂,带来了计算量增加,所以引进了 简化版的LSTM,即GRU。本文介绍GRU的基本原理,并将其与LSTM和RNN进行对比,分析它们各自的优劣。
重点理解 LSTM中h(t)和C(t)的本质,以及 为什么门机制可以解决梯度问题,并且简化计算。
目录
一、从传统RNN说起
传统RNN称为循环神经网络,由于其输入时间序列,使用隐层神经元处理这个时间序列,并在一个 timestep走过这个序列,从而 记下了整个序列的序列信息,隐藏神经元从初始的记忆状态s(0)最后变成了有记忆状态的s(t)。
计算公式如下:
(1)t时刻,隐藏层神经元的激活值为:st=f(Uxt+Wst-1+b1);
(2)t时刻,输出层的激活值为:ot=g(V*st+b2)
得出的参数为 U:传递输入x的参数;W:传递上一步状态的参数,以及隐层节点和输出层节点的值b1和b2。这样一个序列输入后,预测的值走过timestep步长后,输出了预测结果。
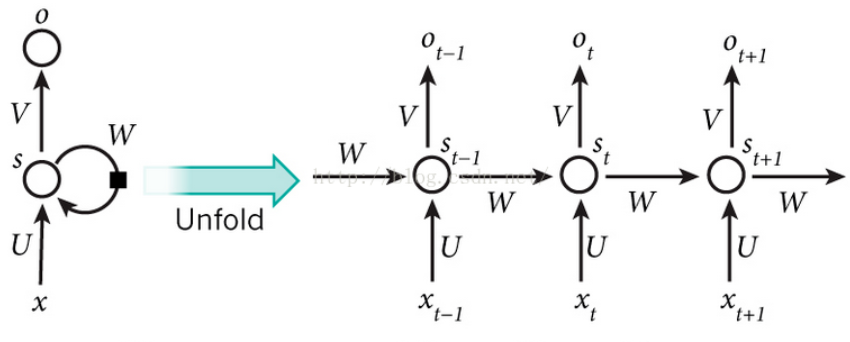

如下图,此时只有一个传递状态h(t)。这样下去难免会出现下图的情况:早期比较早的记忆被忘的差不多了,就 不能处理长序列,记忆长时间的序列信息:
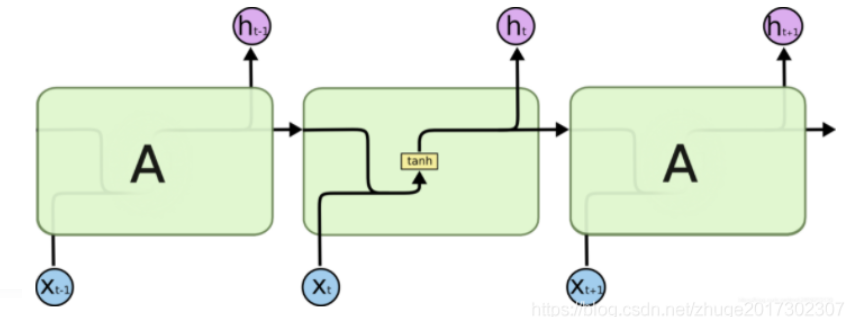
还有就是,由于RNN的梯度计算 依赖于激活函数的对角矩阵与稀疏矩阵U的连积,当激活函数为tanh或者sigmoid时,会出现 梯度消失问题;为relu时会出现 梯度爆炸问题。梯度消失就意外这 对长期依赖关系的不敏感,即长期记忆丢失。
具体梯度原理见:(62条消息) 【神经网络】学习笔记十七——IRNN:初始化矩阵RNN_杨的博客-CSDN博客
基于
(1)梯度问题;
(2)长期记忆丢失问题;
LSTM提供了很好的解决方案。
二、改进的RNN:LSTM
LSTM采用两大机制来解决上面的缺点。首先, 针对梯度消失问题,采用 门机制解决; 对于短期记忆覆盖长期记忆的问题,LSTM采用 cell state来保存长期记忆,配合门机制对信息进行过滤,从而达到对长期记忆的控制。
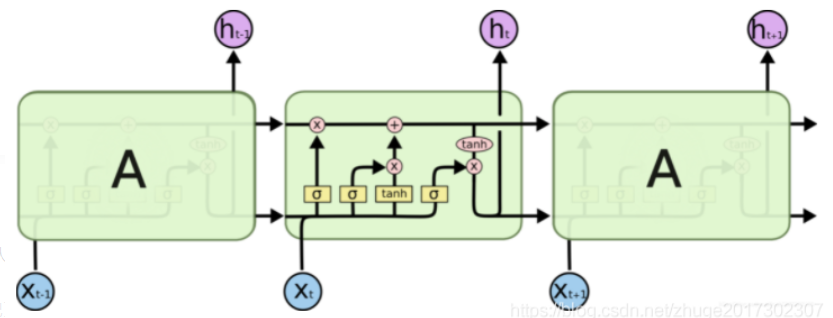
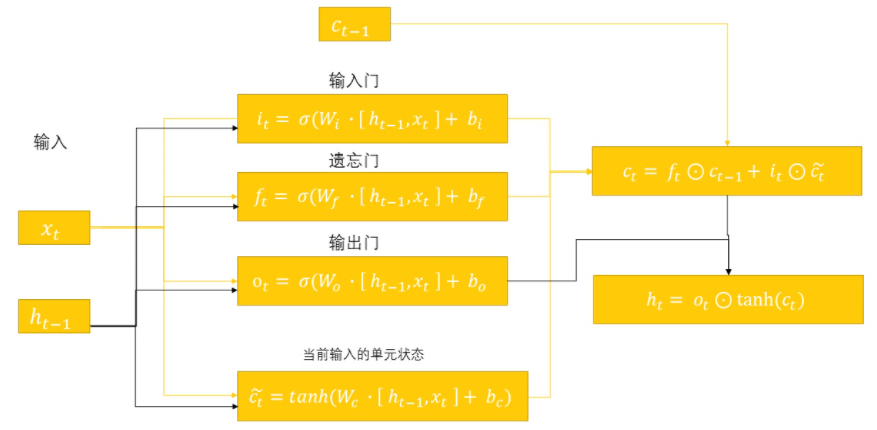
门机制带来了以下两个好处:
(1)极大减轻了梯度消失问题, 简化了调参复杂度(连乘变成了加法,所以简化);
(2)门机制提供了 特征过滤,将有用的信息保存,没用的信息过滤, 并保存了长期记忆。
解释一下短期记忆h(t)和长期记忆C(t)的原理和传递关系:
(1)首先,我们要理解h(t)和C(t)的本质。 C(t)的本质是0~t时刻的全局信息, h(t)的本质时0~(t-1)时刻的全局信息的影响下,当前时刻t的信息的上下文表示;
(2)从计算公式中来看,全局信息C(t)是由上一时刻的全局信息C(t-1)和当前时刻信息x(t)经过输入门和遗忘门过滤一些信息,结合而成;
h(t)则是将C(t)先经过tanh函数压缩为(-1,1)之间的数值,然后通过输出门对C(t)进行过滤,来获知当前单元的上下文信息。这意味着 当前时刻的上下文信息h(t)不过是全局信息C(t)的一部分;
(3)注意本单元状态是由当前时刻输入信息x(t)和上下文信息h(t-1)构成的;
门机制解决了以下问题:
(1)门控解决梯度消失问题的原理是,将梯度计算中 激活函数导数的连积变成了加法,同时仅有长时记忆C(t)参加反向传播,这样就不会因为激活函数的对角矩阵元素值大于1或者小于1连乘导致的梯度问题;
(2)解决长期记忆被覆盖的问题:采用 cell state保存长期记忆,配合门机制进行信息过滤,从而很好的保存了长期记忆。
详见:(62条消息) 【神经网络】学习笔记十七——IRNN:初始化矩阵RNN_杨的博客-CSDN博客
三、简化版的LSTM:GRU
GRU是RNN的另一种变体,也采用门机制解决梯度问题和长期记忆被覆盖问题,不同的是GRU可以视作简化版的LSTM,比对一下二者的公式:
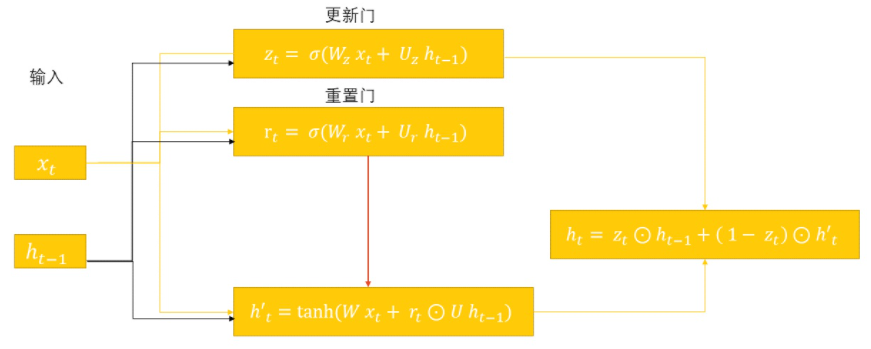
可以看出以下几点:
(1)首先, 门的计算公式没什么区别,都是由当前上下文信息h(t-1)和当前时刻输入x(t)组成而成,不过由三个门简化成两个门;
(2)其次,GRU的
相当于LSTM的当前时刻cell状态, 都表示当前信息;
(3)GRU的h(t)和LSTM的C(t)计算公式一样, 都表示长期记忆;
那么从公式上看,
(1)GRU 抛弃了LSTM的上下文状态信息h(t),它认为既然已经有了长期记忆,就不需要上下文信息h(t)来参与计算;
(2)其次,在生成当前时刻全局信息时,既然遗忘门和输入门所代表的 前t-1个时刻的全局信息和当前cell的状态信息是此消彼长的关系,就不用两个概率了,直接用
替换掉了输入门,简单又高效,简化了计算过程;
四、LSTM和GRU的区别和选择
区别有两个:
(1)LSTM选择暴漏部分信息,只输出h(t),而C(t)只是作为长期记忆的信息载体,并不输出;而GRU选择暴漏全部信息;
(2)输出变化所带来的结构调整:为了与LSTM的信息流保持一致,重置门本质上是输出门的一种变化,由于输出变了,所以其被调整到计算当前cell状态的
中。
总结
首先,可以肯定的是GRU和LSTM都比传统的RNN要表现好。
对于两者来说, GRU参数少,收敛速度更快,花费时间少,可以加速迭代过程。而从效果上说,二者并没有优劣之分,取决于具体的任务和数据集而定。实际上来讲,二者的表现差距往往不大,远远没有调参效果明显。
Original: https://blog.csdn.net/zhuge2017302307/article/details/120686267
Author: 昔我往矣wood
Title: 【学习笔记】【GRU】十八——GRU原理简介与LSTM的比较
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548479/
转载文章受原作者版权保护。转载请注明原作者出处!