

目录
- 贝叶斯网络
以随机变量做节点所形成的有向无环图。
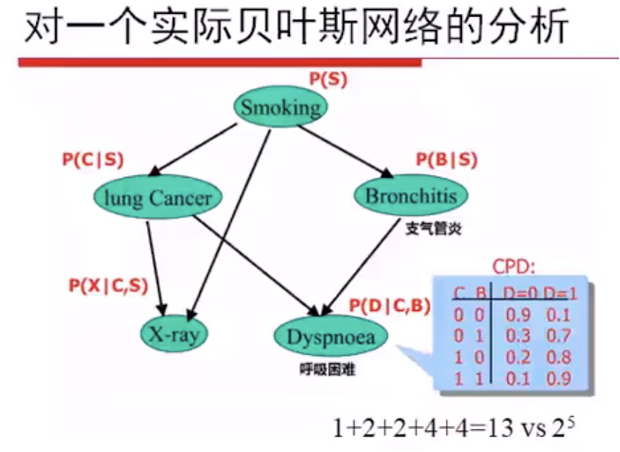

朴素贝叶斯:
- 可以胜任许多文本分类的问题。
- 无法解决语料中 一词多义和 多词一义的问题——它更像是词法分析,而非语义分析。
- 如果使用词向量作为文档的特征, 一词多义和 多词一义会造成计算文档间相似度的不准确性。
- 可以通过增加”主题”的形式,一定程度的解决上述问题:
一个词可能被映射到多个主题中—— 一词多义
多个词可能被映射到某个主题的概率很高—— 多词一义
- 主题模型
PLSA/PLSI:probabilistic latent semantic analys. 可用EM算法来算(两层的贝叶斯网络)
LSI:Latent Semantic Indexing
SVD:
LDA(Latent Dirichlet Allocation):无监督/降维/聚类(三层的贝叶斯网络)
(注意:区分LDA(Linear Discriminant Analysis)线性判别分析,有监督,有监督方式的降维)
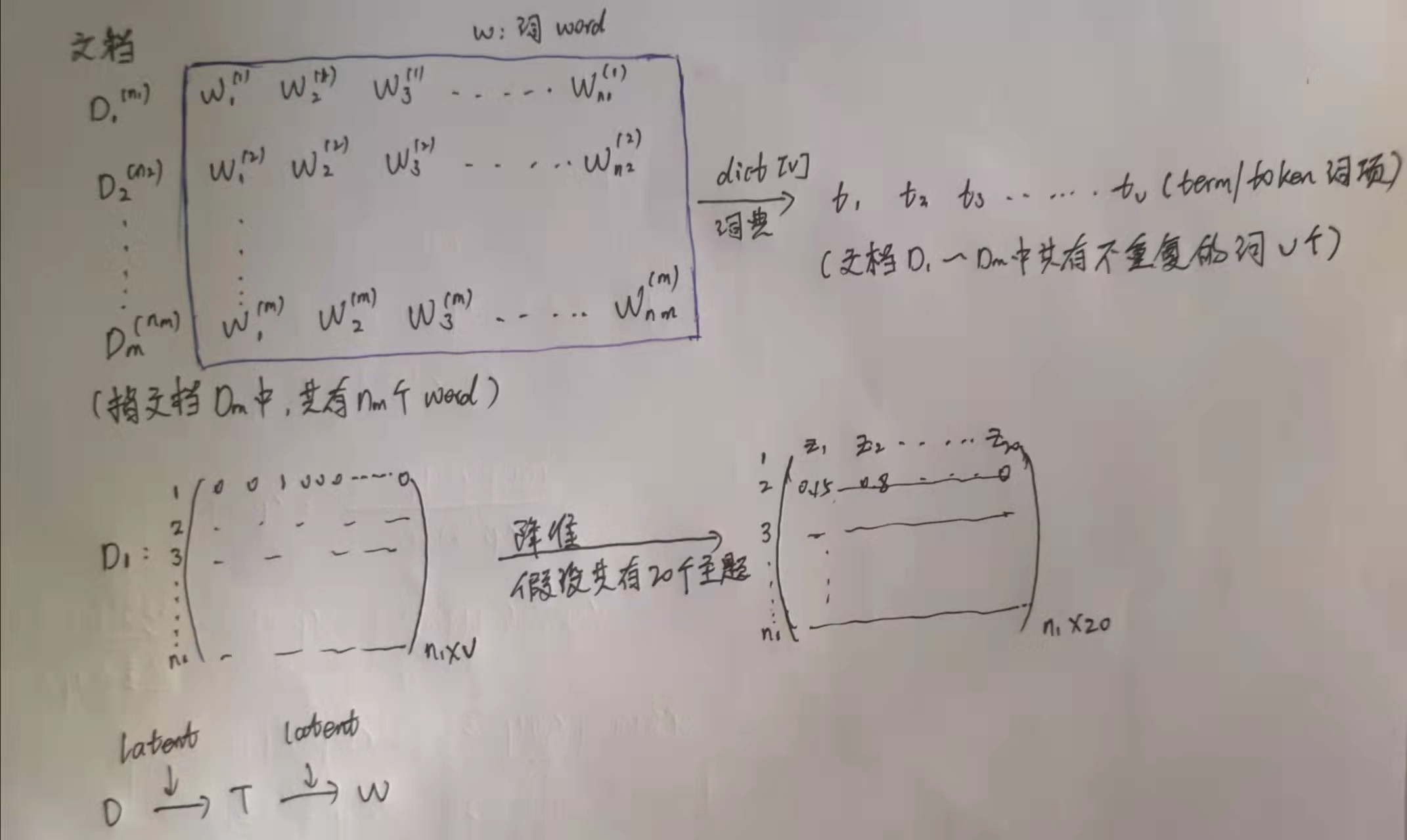
2.1 主题模型的直观理解
2.2 共轭先验分布

2.3 二项分布及其共轭先验——Beta分布
2.3.1 Bete分布


其中,Beta分布具有 两个参数: α , β

注:Bete期望值和最大值点的位置不一定一样
2.3.2 二项分布与其先验分布

先验概率和后验概率的关系


2.3.3二项分布与先验举例


2.4 共轭先验的直接推广
2.4.1 Dirichlet分布

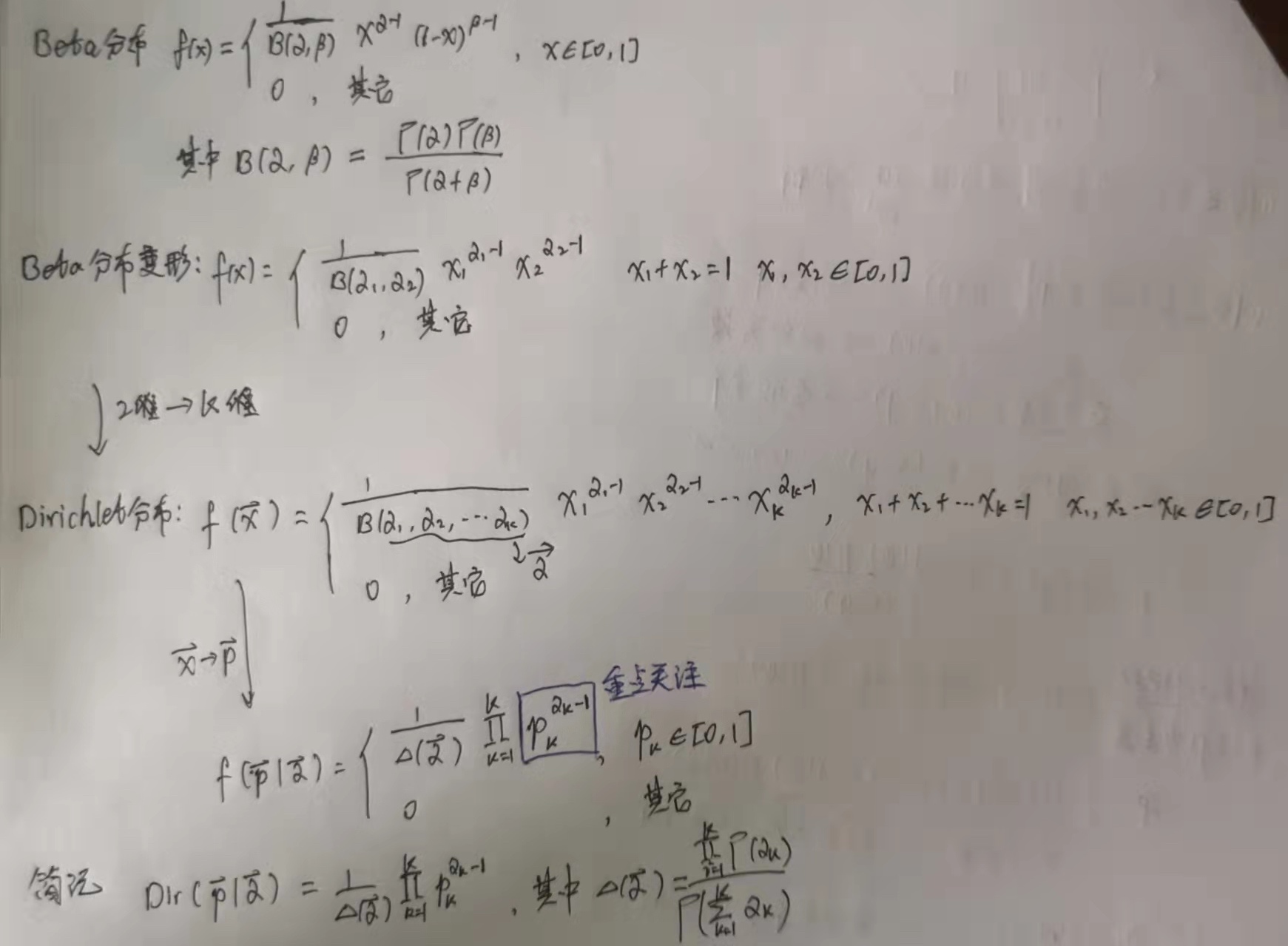


2.4.2对称Dirichlet分布

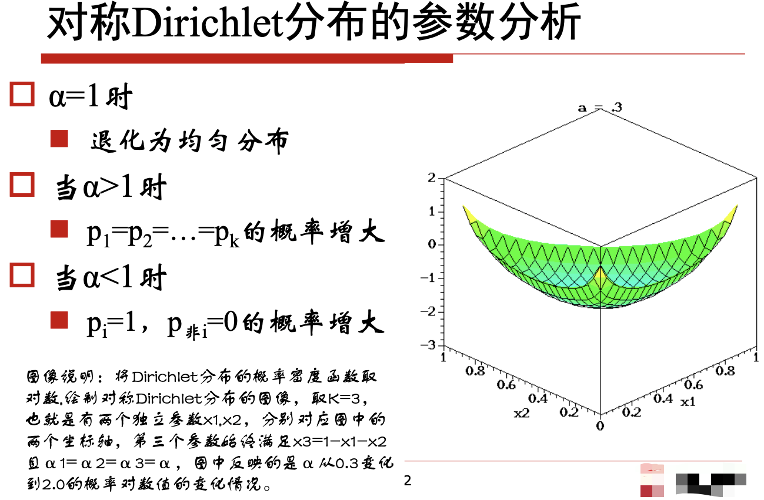
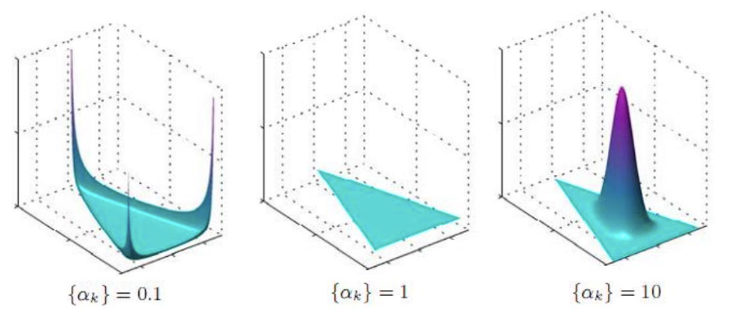
Alpha尽量的不要太大,减少先验的占比
2.5 LDA的解释
2.5.1 判别模型和生成模型
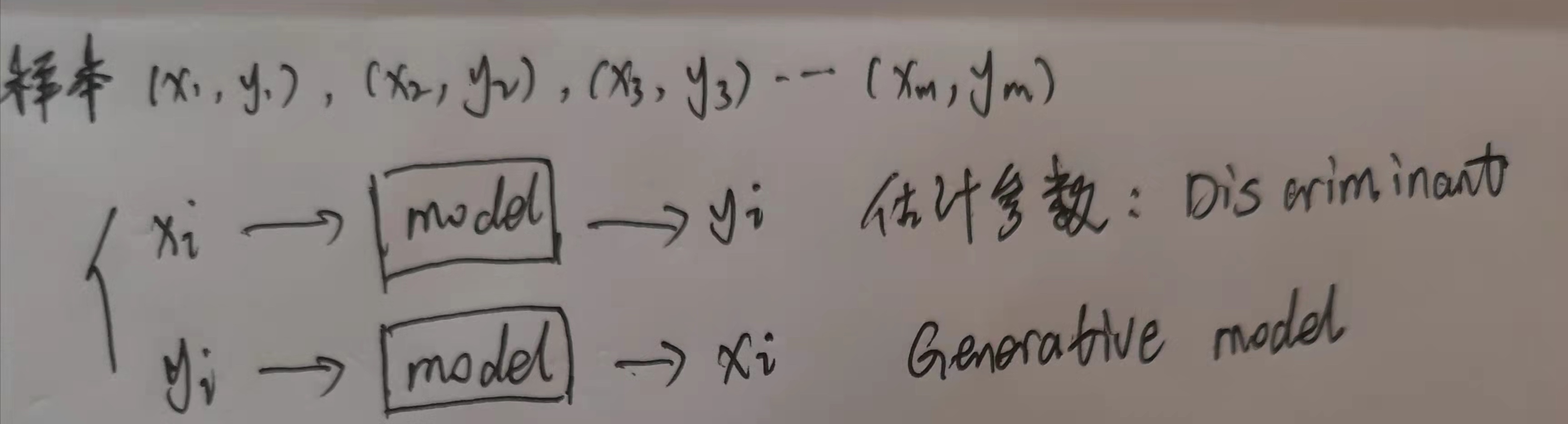
判别模型:线性回归,逻辑回归,决策树,随机森林,SVM,CNN,CRF
生成模型:LDA(Latent Dirichlet Allocation),NB(贝叶斯网络),HMM
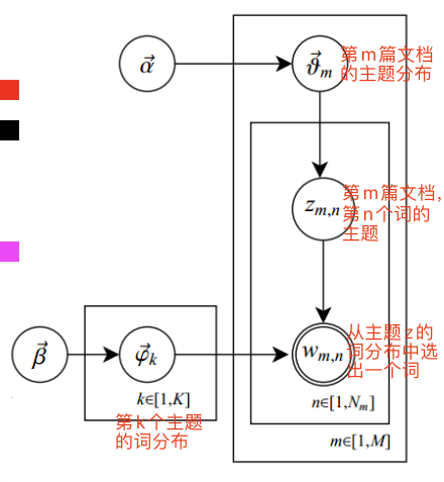
2.5.2 LDA的解释
LDA是一个生成模型,大概流程如下:
(1) 共有m篇文档,一共涉及K个主题;
(2) 每篇文章(长度为Nm)都有各自的主题分布,主题分布是多项分布,该多项分布的参数服从对称Dirichlet分布,该对称Dirichlet分布的参数为 α , k。

(3) 每个主题都有各自的词分布,词分布为多项分布,该多项分布的参数服从对称Dirichlet分布,该对称Dirichlet分布的参数为 β , k。

(4) 对于某篇文章中的第n个词,首先从该文章的主题分布中采样一个主题,然后在这个主题对应的词分布中采样一个词。不断重复这个随机生成过程,直到m篇文章全部完成上述过程。


3.LDA总结
(1)由于在词和文档之间加入 主题的概念,可以较好的解决 一词多义和 多词一义的问题。
(2)在实践中发现,LDA用于短文档往往效果不明显——这是可以解释的:因为一个词被分配给某个主题的次数和一个主题包括的词数目尚未收敛。往往需要通过其他方案”连接”成长文档。
(3)用户的评论/Twitter/微博。LDA可以和其他算法 相结合。首先使用LDA将长度为Ni的文档 降维到K维(主题的数目),同时给出每个主题的概率(主题分布),从而可以使用if-idf继续分析或直接作为文档的特征进入 聚类或者 标签传播算法——用于社区发现等问题。
- LDA实现
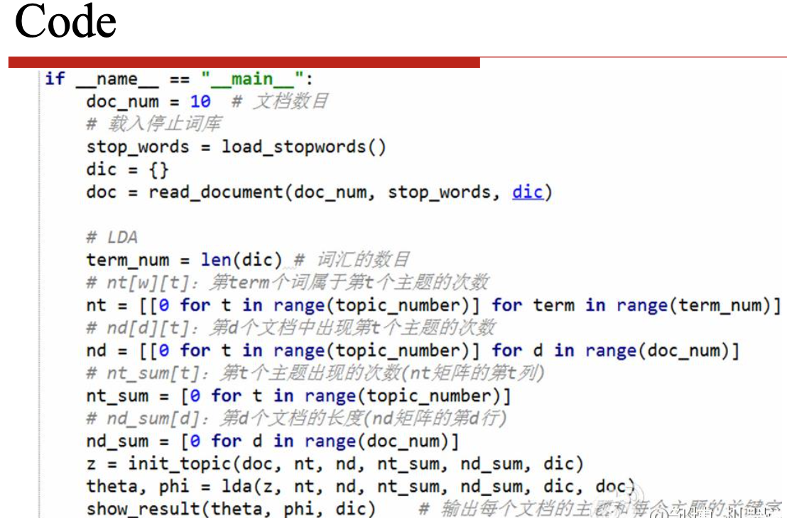
4.1 手撕LDA



4.2 LDA的其它库实现
Genism,开源实现库等

5.LDA应用场景
- 针对国内某石油企业的例行检查处理结果,试通过主题模型方案,分析例检结果中最突出的问题是什么?
2.聊天记录分析感兴趣话题
数据处理流程:
(1)获取QQ群聊天记录:txt文本格式(图1)
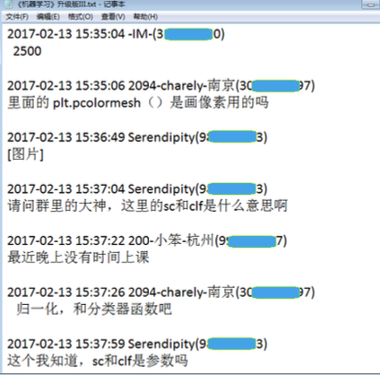
(2)整理成”QQ号/时间/留言”的规则形式
- 正则表达式
- 清洗特定词:表情,@xx
- 使用停止词库
- 获得csv表格数据(图2)
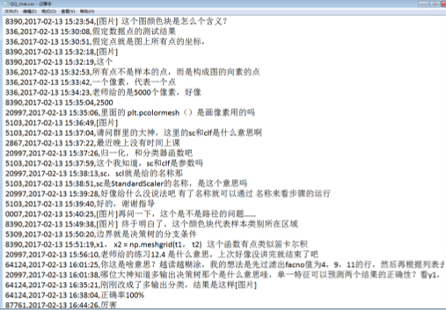
(3)合并相同QQ号的留言
长文档利于计算每人感兴趣话题(图3)

(4)LDA模型计算主题
调参与可视化
(5)计算每个QQ号及众人感兴趣话题
- 附录
6.1 LDA中参数的学习





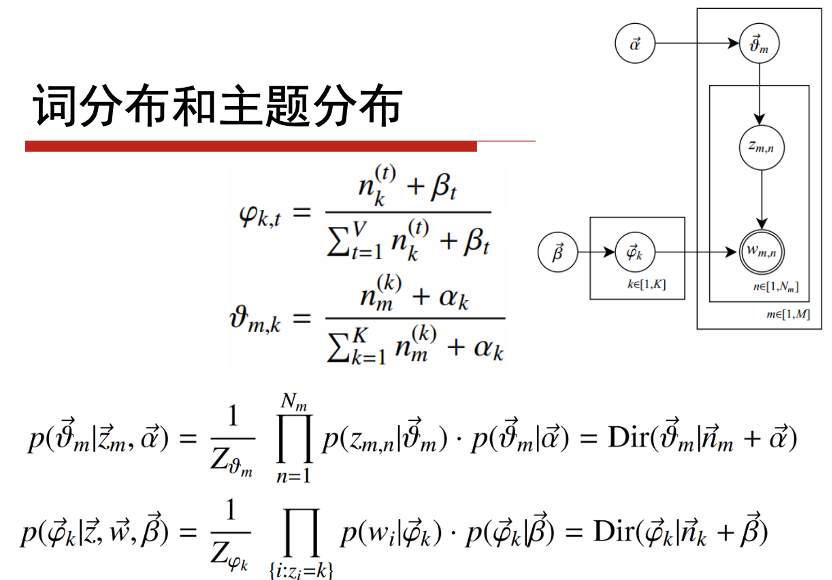

6.2超参数的确定





- 参考文献


Original: https://blog.csdn.net/zhao_crystal/article/details/121317941
Author: zhao_crystal
Title: LDA(Latent Dirichlet allocation)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548259/
转载文章受原作者版权保护。转载请注明原作者出处!