

Abstract
我们研究了一种篱笆(Lattice)结构的LSTM模型为中文NER任务。它能够编一序列的a sequence 的characters 和words。相对于characters编码,它能够加载words信息;相对于words编码,它不用承受 分割误差(segmentation errors)。门控循环细胞单元(gated recurren cell )使我们可以选择句子中最相关的characters和words,以获得最好的结果。各种实验结果表明,我们的模型比 characters类和words类的模型都要棒。
1 Introduction
NER近些年来很火,这是一个序列标注任务,需要预测实体编辑和类别标签。目前的 state-of-the-art 模型是 LSTM-CRF模型,它用character信息来预测words。
中文NER是一般需要先进行word segment的,然而,segment-> NER 过程会遭受 segment的误差传播,即segment 误差会影响NER的识别结果。
目前已经证实,character类的模型 outperform word类的模型。character类的模型有一个缺点就是:word信息没有被利用,而这些信息应该是很有用的。为了解决这个问题,我们提出了篱笆(Lattice)结构的LSTM-CRF模型。如图1所示,我们用字典构建了一个匹配句子的 charater-word 篱笆网络,结果,word信息,如 长江大桥、长江、大桥,可以被用来消除 潜在的相关命名实体,如 江大桥。


因为在lattice中,word-character path是指数级的,为此,我们搞了一个Lattice-LSTM结构来自动控制信息流。如图2所示,对每个character来说,门控单元被用来动态的routine 来自不同路径的信息。

结果证明,我们的模型效果超棒。
; 2 Related Work
3 Model
Follow 最好的英文NER任务,我们用 LSTM-CRF 作为我们的主要网络结构,用BIOES作为tagging架构。
3.1 Character-Based Model


在这里,e c e^c e c代表一个 character embedding lookup table。
用的是双向LSTM来做特征提取,即h c j = [ h c j ← , → h c j ] h_c^j=[h_c^j \leftarrow ,\rightarrow h_c^j]h c j =[h c j ←,→h c j ]。接着,一个标准的CRF被用在h c j h_c^j h c j 上为序列标注。
- Char + bichar.

这里,e b e^b e b代表一个charater bigram lookup table。
* Char + softword.
已经被证实,用segment作为一个soft特征,确实可以提高 character类NER任务的表现。

这里,e s e^s e s代表一个 segmentation label embedding lookup table。s e g ( c j ) seg(c_j)s e g (c j )代表c j c_j c j 上的segment label,它是一个word segmentor提供的,用BMES来作表征。
; 3.2 Word-Based Model

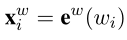
在这里,e w e^w e w代表一个word embedding lookup table. 用的是双向LSTM来做特征提取,即h c j = [ h c j ← , → h c j ] h_c^j=[h_c^j \leftarrow ,\rightarrow h_c^j]h c j =[h c j ←,→h c j ]。接着,一个标准的CRF被用在h c j h_c^j h c j 上为序列标注。
新点:Integrating character representations

character CNN和LSTM一直以来可以被表示 一个word中的character表征,这里我们用了它们2个。上式子中 x j c x_j^c x j c 代表此w j w_j w j 种的character表征。
- Word + char LSTM.
令每个输入character c j c_j c j embedding为e c ( c j ) e^c(c_j)e c (c j ),我们用双向LSTM来学习word中每个character的双向隐层表示,最后词w i w_i w i 的character表示为:

其中,len(i)是词w i w_i w i 的character长度。
* Word + char LSTM
我们研究” Word + char LSTM”的一个变体,即 用一个single LSTM来得到每个c j c_j c j 的隐层表征h j c ← h_j^c \leftarrow h j c ←、→ h j c \rightarrow h_j^c →h j c 。将 character hidden states 融入 word representation 的方式和上面相同。
* Word + char CNN
令每个输入character c j c_j c j embedding为e c ( c j ) e^c(c_j)e c (c j ),那么每word的character表征向量x i c x_i^c x i c 的表示为:

其中,ke=3是卷积核的大小,max意味着 max pooling.
3.3 Lattice Model
咱的模型看起来像是 character类模型的扩展,添加了word信息和门控单元。

如第2节所示,我们用自动分割的大原始文本来构建词典D。模型的基本循环单元是由一个character单元向量 c j c c_j^c c j c 和一个隐藏向量h j c h_j^c h j c 构成的。这基本的循环LSTM函数是:
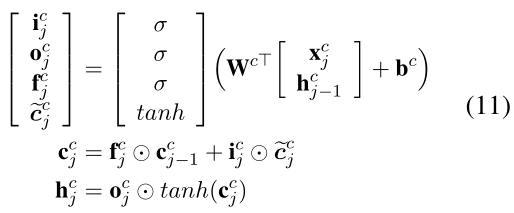
其中,i j c i_j^c i j c 、f j c f_j^c f j c 、o j c o_j^c o j c 分别代表输入门、遗忘门、输出门。与character类模型不同的是,现在c j c c_j^c c j c 的计算考虑了句子中的词典级次级序列w b , e d w_{b,e}^d w b ,e d ,每个w b , e d w_{b,e}^d w b ,e d 的表征公式如下:

其中,e w e^w e w代表着 word embedding lookup table.
另外,c b , e w c_{b,e}^w c b ,e w 被用来表示 x b , e w x_{b,e}^w x b ,e w 的循环状态,c b , e w c_{b,e}^w c b ,e w 的计算公式如下:

这里没有输出门,因为序列标注是对 character level 而言的。
with c b , e w c_{b,e}^w c b ,e w ,这里就有了更多的数据流入到 character c j c c_j^c c j c 。例如,在figure2中,c 7 c c_7^c c 7 c 的输入就有 x 7 c x_7^c x 7 c (桥)、c 6 , 7 w c_{6,7}^w c 6 ,7 w (大桥)、c 4 , 7 w c_{4,7}^w c 4 ,7 w (长江大桥)。我们连接所有的 c b , e w c_{b,e}^w c b ,e w with b ∈ { b ′ ∣ w b ′ , e d ∈ D } b \in { b’|w_{b’,e}^d \in D }b ∈{b ′∣w b ′,e d ∈D } 和这细胞状态c e c c_e^c c e c 。我们再用一个门控单元 i b , e c i_{b,e}^c i b ,e c 来控制 子序列 c b , e w c_{b,e}^w c b ,e w 流入到 c b , e c c_{b,e}^c c b ,e c 的contribution。

细胞单元的值 c j c c_j^c c j c 的计算公式因此变为:
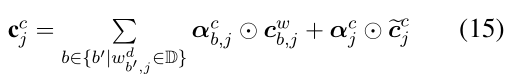
在公式15中,这门控值 i b , j c i_{b,j}^c i b ,j c 和i j c i_j^c i j c 被正则化为 α b , j c α_{b,j}^c αb ,j c 和α j c α_j^c αj c ,计算公式如下所示:

这最后的隐藏向量h j c h_j^c h j c 仍然和公式11中一样。
; 3.4 Decoding and Training
CRF层是建立在 h 1 h_1 h 1 、h 2 h_2 h 2 … h μ h_μh μ之上,对应的标签序列 y = l 1 , l 2 , . . . , l μ y = l_1,l_2,…,l_μy =l 1 ,l 2 ,…,l μ的概率为:
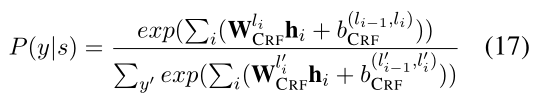
其中,y ′ y’y ′代表了一条被任意标注的序列。训练损失函数为:

其中,代表着参数集合。
4 Experiments
我们做了大量实验。
4.1 Experimental Settings
Data:OntoNotes 4、MSRA、Weibo NER、a Chinese resume datase。
Segmentation:对OntoNotes 4 和MSRA来讲,其训练集上的 黄金标注分割是可以得到的。对OntoNotes 来讲,其验证集和测试集上的黄金分割也是可以得到的,但是,对MSRA来讲,其测试集得不到 黄金分割,Weibo 和 resume 数据集也得不到。于是,我们采用 神经网络分词器 来自动进行分割。具体的,针对OntoNotes 4 和MSRA,我们训练分词器在它们各自的训练集上;对Weibo 和 resume ,我们采用了 Yang et al 的最好的模型。
Word Embeddings:我们用word2vec 预训练了word embedding,然后在NER训练中进行微调;我们用word2vec 预训练了character embedding 和 character bigram embedding,然后在NER训练中进行微调;
Hyper-parameter settings:参数设置如图所示。针对每个具体的数据集,没有用网格搜索进行微调。

4.2 Development Experiments
结果如下所示:

其中,值得注意的是:
(1)a word-based LSTM CRF baseline 给出了F1值为64.12%,比 a character-based LSTM CRF baseline 要高。
(2)A CNN representation of character sequences gives a slightly higher F1-score compared to LSTM character representations.
(3)在 word embedding中,当给char CNN增加 bichar后,F1值却下降了。考虑原因为:CNN本身已经抓住了 character 级的N-gram信息。
(4)Lattice-based 结果最棒。值得注意的是:当bigram 信息加强后,F1值并没有提升。考虑其原因: words are better sources of information for character disambiguation compared with bigrams, which are also ambiguous.
(5)Lattice-based 表现超过 char+subword,说明:ws the advantage of lattice word information as compared with segmentor word information
; 4.3 Final Results
用4.2节得到的3种类最优模型和历史上那些名模一起 来在四种数据上做实验。
4.4 Discussion
F1 against sentence length:
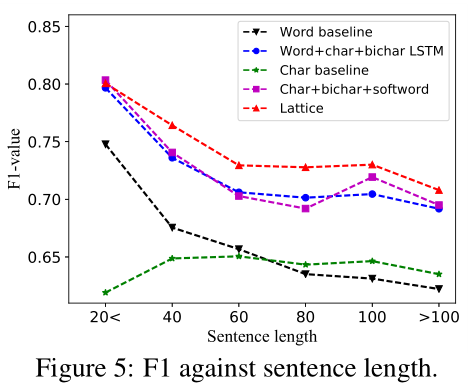
值得注意的是以下几点:
(1)The word-based baseline gives substantially higher F1-scores over short sentences, but lower F1-scores over long sentences, which can be because of lower segmentation accuracies over longer sentences.
(2)The accuracy of lattice also decreases as the sentence length increases, which
can result from exponentially increasing number of word combinations in lattice.
Case Study
注意到word+char+bichar和lattice有相同的word信息源,区别在于:word+char+bichar首先使用词汇是在分词器中,这会施加硬约束(即,固定词)到NER任务中。相比之下,lattice LSTM可以自由考虑所有词典汇词。
; 5 Conclusion
由于lattice方法和word segment是独立的,所以在利用word信息上对NER消歧更有效果。
Original: https://blog.csdn.net/weixin_42425256/article/details/124215734
Author: 青灯剑客
Title: Chinese NER Using Lattice LSTM 论文解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548251/
转载文章受原作者版权保护。转载请注明原作者出处!