

远程监督关系抽取——综述
- 开山之作
* - [ACL 2009-斯坦福-被引:2799] [Distant supervision for relation extraction without labeled data](https://aclanthology.org/P09-1113/)
- MIL+Deep Learning的发展之路
* - [ACL 2015-中科院自动化所-被引:==888==] [Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks](https://aclanthology.org/D15-1203/)
- [COLING 2016-中科院信工所-被引:108] [Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks](https://aclanthology.org/C16-1139.pdf)
- [ACL 2016-清华-被引:==874==] [Neural Relation Extraction with Selective Attention over Instances](https://aclanthology.org/P16-1200v2.pdf)
- [AAAI 2018-中科院-被引:91] [Large Scaled Relation Extraction with Reinforcement Learning](https://ojs.aaai.org/index.php/AAAI/article/view/11950/11809)
- [ACL 2019-德国AI研究所-被引:70] [Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction](https://aclanthology.org/P19-1134/)
- [AAAI 2019-浙大-被引:39] [Cross-relation cross-bag attention for distantly-supervised relation extraction](https://dl.acm.org/doi/10.1609/aaai.v33i01.3301419)
- [ACL 2021-浙大和阿里-被引:1] [CIL: Contrastive instance learning framework for distantly supervised relation extraction](https://aclanthology.org/2021.acl-long.483.pdf)
- 其他
* - [ACL 2017-北大-被引:75] [Learning with noise: Enhance distantly supervised relation extraction with dynamic transition matrix](https://arxiv.org/abs/1705.03995)
- [ACL 2018-北大-被引:129] [DSGAN: Generative adversarial training for distant supervision relation extraction](https://aclanthology.org/P18-1046/)
不同于有监督的关系抽取方法要求高质量的标注数据,远程监督的方法使用 启发式的规则大批量标注的数据来训练,然而这种通过启发式规则标注的数据往往包含大量噪声,因此远程监督的关系抽取方法的贡献点主要是在于怎么降低噪声对模型的影响。
本文将会对远程监督的主流方法 MIL(Multi-Instance Learning),及其他方法进行梳理。
开山之作
这篇文章是远程监督的开山之作,对远程监督关系抽取下了定义
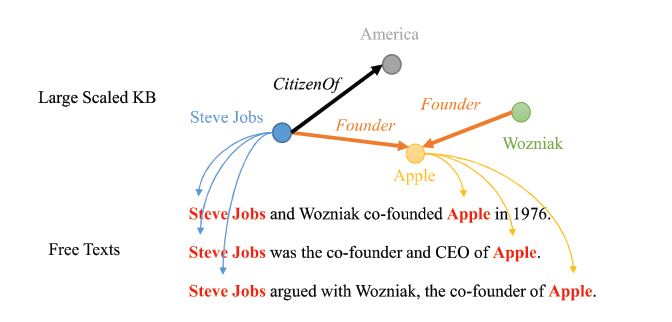

文中提出了一个假设——对于两个有特定关系的实体,任何句子只要包含这两个实体,都会表达这种关系,基于这个假设,作者使用大规模知识图谱中的三元组对齐到非结构化的文本中,生成了大批量的数据。
对其的方式如上图所示:三元组为(Steve Jobs, Founder, Apple),按照远程监督的做法,上图中的三个句子都会打上这个三元组的标签,不难发现,上图的第三句其实就是一个噪声,它并没有表达乔布斯是苹果公司的创始人这个意思。
; MIL+Deep Learning的发展之路
MIL+Deep Learning是远程监督关系抽取的主流方法
PCNNs这篇文章不是第一个提出用MIL(Multi-Instance Learning)来做这个任务的,但他是这个领域第一个把MIL和深度学习结合起来的。MIL的思想在于,把很多的实例打包,即使有很多噪声实例,但包的总体性质还是可以是正确的。放在这个任务中就是,我们把同一个三元组得到的全部标注句子打成一个包,虽然这些标注句子有很多是有噪声的,但是这个包整体是能够反应出这个三元组的语义的。

如上图所示,模型先选出每个包置信度最高的那个句子,然后只用置信度最高的那一个句子来进行后续的训练,注意到本文的每个包中只用到一个句子,这样做的好处在于这一个句子有很大的可能性不是噪声,坏处在于有很多数据没用上,浪费了。
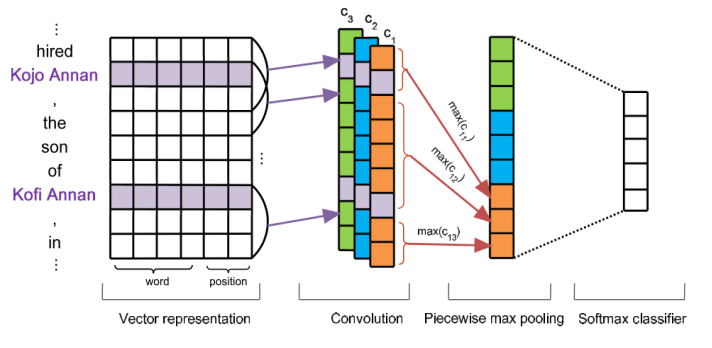
虽然我认为在这个领域,模型设计从来不是最主要的贡献点,但PCNNs的这个模型结构影响了很多后面的工作,因此最后介绍一下PCNNs的模型结构。它把word+position的embedding输出CNN后,根据两个实体的位置,把句子特征分成3份,这三份各自进行最大值池化后拼接到一起,最后输入分类头。
针对Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks中每个包只用到了一个句子,而浪费了许多数据的问题,这篇文章通过把包中的所有句子的特征用一个MaxPooling层简单粗暴的融合到一起,用池化后的输出作为这个包的特征表示。
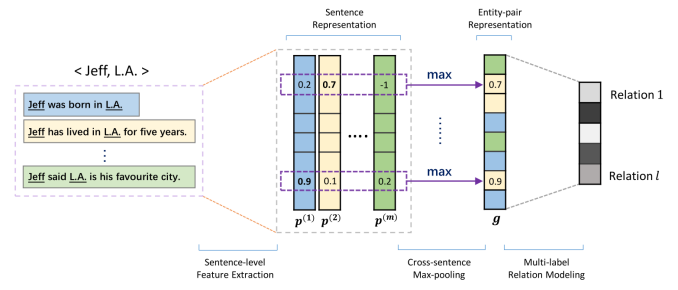
这篇文章的另一个贡献点在于他题目中的Multi-label,这个简单说就是作者把分类中常见的Softmax+CrossEntropy,改成了Sigmoid+BCE+L2,区别在于原本的softmax输出只能是单分类(one-hot),而sigmoid的输出则可以是多分类。
本文的句子编码器还是用的PCNNs。
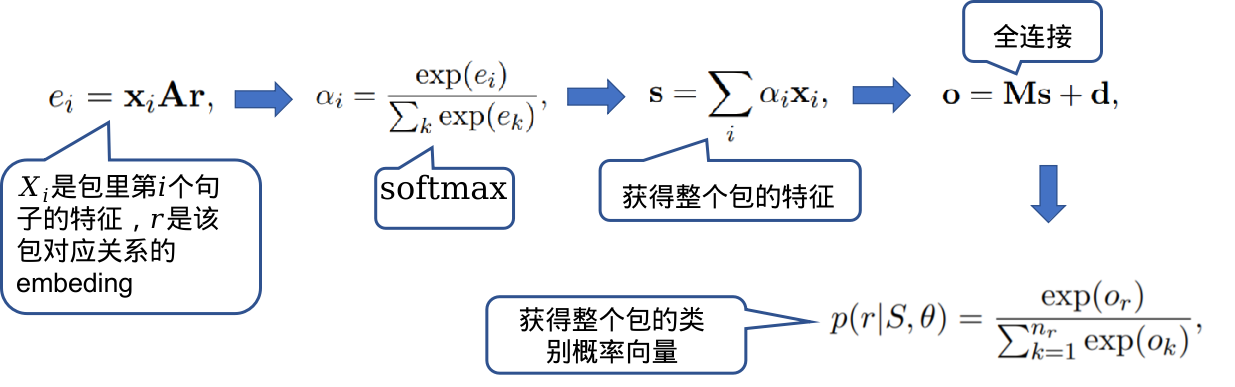
本文与Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks的出发点相同,都是为了解决Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks中数据浪费的问题。不同点在于,相比起Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks简单粗暴的MaxPooling,这篇文章提出了一种Selective Attention机制,能够使模型给包中不同句子的分配权重,以实现让模型更加关注于没有噪声的样本,噪声样本对模型的影响就降低了。具体操作如下图。
用现在的眼光看来,要聚合一个特征集合的方法有很多,比如: Sum,Mean,Max,attention等,而不可学习Sum,Mean,Max的性能往往弱于可学习的attention。
这篇文中的句子编码器还是PCNNs。

这篇使用了强化学习的思想来降低噪声的影响,每个包对应到强化学习中的episode,每个句子对应到强化学习中的state。看到这里,可能大家会有一点违和感,因为对于强化学习而言,state跟state之间是连续变化的,是有过去未来之分的,而如果包中的句子都为state的话,就会导致state跟state之间是独立的,且他们之间没有顺序之分。
正是因此,如上图式(5),文中把折扣因子γ设为1,来消除顺序的影响。且r1,r2,… ,rn-1 = 0, rn = 1或-1(如果包中置信度(不算NA类别)最高那个句子预测对了则为1,否则为-1)这意味着,如果置信度最高的state预测对了,那整个episode的行为都会受到鼓励,否则受到惩罚。等价为有监督的说法就是,如果一个包中执行度最高的句子预测对了,那他就认为这个包的所有句子都预测对了(跟label不一样就是label有噪声),然后把label改为预测结果,继续训练。
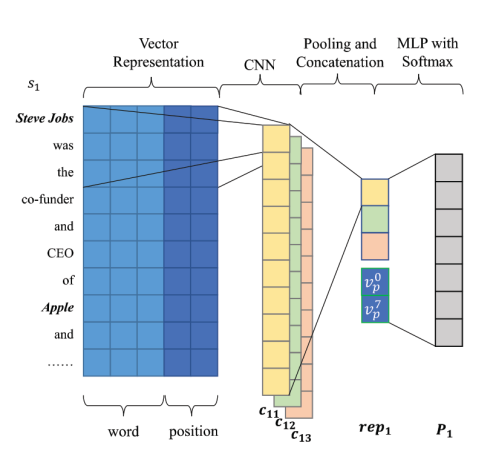
这篇少有的没用PCNNs作为句子编码器,而是他自己提出的一个网络,即先把word+position的embedding输入CNN,然后做一个全局池化得到一个句义特征向量,再把两个实体的位置编码拼接在句义向量后面,再输入MLP及Softmax。
说这篇的目的在于两点:
- 18年底出了GPT1和BERT,这使得18,19年的一大波论文只需要把大规模预训练语言模型引进来就已经是一大贡献点
- 这篇文章follow的是16年的selective attention来聚合包的特征,且往后的文章大部分都是follow的selective attention

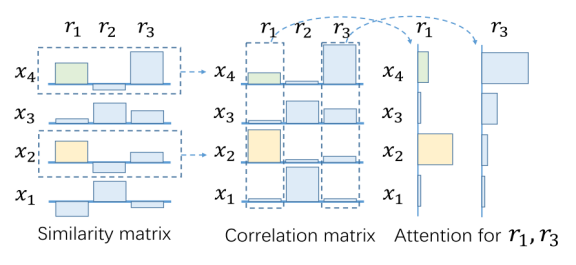
本文有两大贡献点,首先是cross-relation attention。
具体来说,相比之前的selective attention是直接对下图的竖的向量做softmax,而cross-relation attention则是先横着做一次softmax,再竖着做归一化,这在数学上就是一个贝叶斯后验概率的计算,如上图,在理解上则是关系间的互相推理,如下图中,从x4的关系是r3的概率大可以推出x4的关系是r1的概率小。
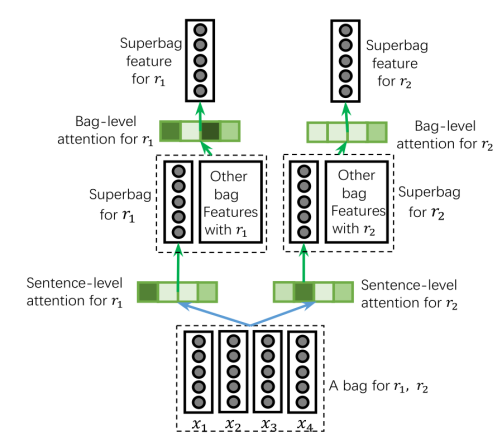
本文的第两大贡献点是cross-bag attention。
作者认为有可能整个包中的所有句子都是错的,因此,他在基于cross-relation attention提取完包的特征后,还会对不同的包特征进行一次selective attention。
这篇的贡献点在于引入了对比学习,实验表明提点明显。
这篇文章也是follow16年的selective attention来聚合包的特征。
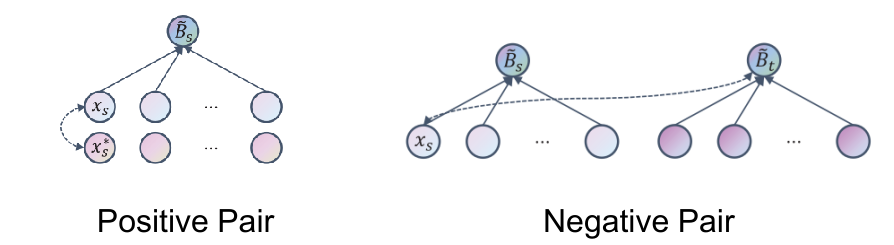
上图为对比学习的正负样本的构造方式,正样本对为原始数据和原始数据进行数据增强后的数据,负样本为其他包的包特征。
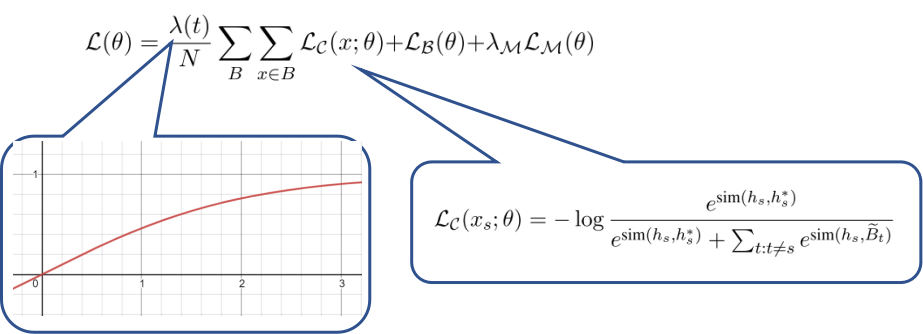
本文的损失函数有3项,其中LB就是交叉熵分类loss,LM是预训练语言模型(Bert)的loss,LC是对比学习的loss,且LC有个随时间逐渐变大的因子λ(t),这意味着一开始对比学习是不起作用的,随着时间的推移,对比学习的loss的权重逐渐增大。
; 其他
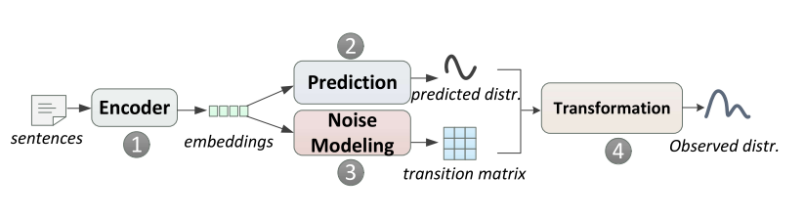
本文希望用一个转移矩阵来学习到噪声的模式,如上图,它会根据句子的embedding生成predicted distr.和transition matrix,推断时模型直接输出predicted distr.,训练时会用transition matrix与predicted distr.相乘,生成observe distr.
损失函数如下图,α的值从1逐渐减小到0,这意味着一开始模型只对predicted distr.进行监督,然而这个predicted distr.是在噪声中学习的,因此predicted distr.可能会犯错,然而在α逐渐减小的过程中,模型对observe distr.的监督力度逐渐变强,对predicted distr.的监督力度逐渐变弱,这时有噪声的监督不会直接影响到predicted distr.,而是由observe distr.通过transition matrix间接影响到了predicted distr.。
然而,如果对transition matrix不加任何约束的话,有可能对observe distr.的监督完全影响不到predicted distr.,那predicted distr.就失去了意义了,因此本文把transition matrix的迹作为损失函数中的一项,如下图的-βtrace(Ti)。因为transition matrix的每一行都做过softmax,因此当transition matrix的迹最大时,transition matrix为单位阵,这时predicted distr.和observe distr.完全一样。通过调节β的大小,来保证predicted distr.和observe distr.有一定的相似性,有不至于使有监督的噪声直接影响到predicted distr.

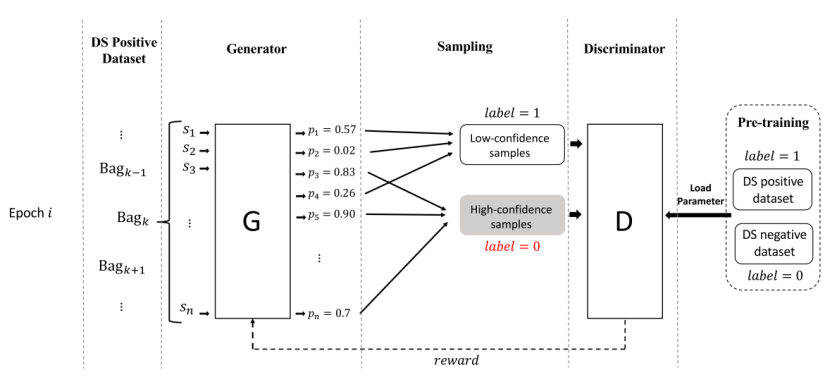
- 与其在噪声中学习,不如在一开始就把噪声滤掉。文中正是出于这个想法,训练了一个噪声过滤器G,如上图。
- 这篇虽然标题有GAN,但它sampling那一步是不可导的,因此G无法直接获得D的梯度,因此它本质上是强化学习。
Original: https://blog.csdn.net/Little_White_9/article/details/123814924
Author: WSLGN
Title: 远程监督关系抽取——综述
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/547965/
转载文章受原作者版权保护。转载请注明原作者出处!