

python –利用朴素贝叶斯进行文本分类
一,分类目标
寻找文本的某些特征,然后根据这些特征将文本归为某个类。
使用监督式机器学习方法对文本进行分类:首先假设已经有分好类的N篇文档:(d1,c1)、(d2,c2)、(d3,c3)……(dn,cn)
di表示第i篇文档,ci表示第i个类别。目标是:寻找一个分类器,这个分类器能够:当丢给它一篇新文档d,它就输出d (最有可能)属于哪个类别。
二、朴素贝叶斯分类器
朴素贝叶斯分类器是一个概率分类器。假设现有的类别C={c1,c2,……cm}。给定一篇文档d,文档d最有可能属于哪个类呢?这个问题用数学公式表示如下:
$P(Y,X) = P(Y|X)P(X)=P(X|Y)P(Y) $
其中P ( Y ) P(Y)P(Y)叫做先验概率,P ( Y ∣ X ) P(Y|X)P(Y∣X)叫做后验概率,P ( Y , X ) P(Y,X)P(Y,X)叫做联合概率。
在机器学习的视角下,我们把X XX理解成“具有某特征”,把Y YY理解成”类别标签”(一般机器学习问题中都是X=>特征, Y=>结果对吧)。在最简单的二分类问题(是与否判定)下,我们将Y YY理解成”属于某类“的标签。
三、jieba切词
jieba分词属于概率语言模型分词。概率语言模型分词的任务是:在全切分所得的所有结果中求某个切分方案S,使得P(S)最大。
jieba支持三种分词模式:
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
精确模式,试图将句子最精确地切开,适合文本分析;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jeiba分词过程:
生成全切分词图:根据trie树对句子进行全切分,并且生成一个邻接链表表示的词图(DAG),查词典形成切分词图的主体过程如下所示:
for(int i=0;i<len;){
boolean match = dict.getMatch(sentence, i,
wordMatch);//到词典中查询
if (match) {// 已经匹配上
for (String word:wordMatch.values)
{//把查询到的词作为边加入切分词图中
j = i+word.length();
g.addEdge(new CnToken(i, j, 10, word));
}
i=wordMatch.end;
}else{//把单字作为边加入切分词图中
j = i+1;
g.addEdge(new CnToken(i,j,1,sentence.substring(i,j)));
i=j;
}
}
计算最佳切分路径:在这个词图的基础上,运用动态规划算法生成切分最佳路径。
使用了HMM模型对未登录词进行识别:如进行中国人名、外国人名、地名、机构名等未登录名词的识别,重新计算最佳切分路径。
四、实现朴素贝叶斯分类文本
demo代码如下
import os
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
def cut_words(file_path):
"""
对文本进行分词
:param file_path: txt文本路径
:return: 用空格分隔的字符串
"""
text_with_spaces = ''
text = open(file_path,'r',encoding='gb18030').read()
text_cut = jieba.cut(text)
print(text_cut)
for word in text_cut:
text_with_spaces += word + ' '
print(text_with_spaces)
return text_with_spaces
def loadfile(file_dir,label):
"""
加载路径下所有文件
:return:
"""
file_list = os.listdir(file_dir)
word_list = []
labels_list = []
for file in file_list:
file_path = file_dir + '/' + file
word_list.append(cut_words(file_path))
labels_list.append(label)
return word_list,labels_list
train_words_list1, train_labels1 = loadfile(r'D:\taoqing\data\train\女性','女性')
train_words_list2, train_labels2 = loadfile(r'D:\taoqing\data\train\体育', '体育')
train_words_list3, train_labels3 = loadfile(r'D:\taoqing\data\train\文学', '文学')
train_words_list4, train_labels4 = loadfile(r'D:\taoqing\data\train\校园', '校园')
train_words_list = train_words_list1 + train_words_list2 + train_words_list3 + train_words_list4
train_labels = train_labels1 + train_labels2 + train_labels3 + train_labels4
test_words_list1, test_labels1 = loadfile(r'D:\taoqing\data\test\女性','女性')
test_words_list2, test_labels2 = loadfile(r'D:\taoqing\data\test\体育', '体育')
test_words_list3, test_labels3 = loadfile(r'D:\taoqing\data\test\文学', '文学')
test_words_list4, test_labels4 = loadfile(r'D:\taoqing\data\test\校园', '校园')
test_words_list = test_words_list1 + test_words_list2 + test_words_list3 + test_words_list4
test_labels = test_labels1 + test_labels2 + test_labels3 + test_labels4
stop_words = open(r'D:\taoqing\data\stop\\stopword.txt', 'r', encoding='utf-8').read()
stop_words = stop_words.encode('utf-8').decode('utf-8-sig')
stop_words = stop_words.split('\n')
tf = TfidfVectorizer(stop_words=stop_words,max_df=0.3)
train_features = tf.fit_transform(train_words_list)
test_features = tf.transform(test_words_list)
clf = MultinomialNB(alpha=0.001)
clf.fit(train_features,train_labels)
predicted_labels = clf.predict(test_features)
print('准确率:',metrics.accuracy_score(test_labels,predicted_labels))
五、数据集说明
由于精力有限,目前是构造了四类文本数据集,跑出来后分类结果的准确率在98%左右,可能是数据集偏少的一部分原因,有兴趣的小伙伴可以私信我要相关数据集。
最后附结果图:
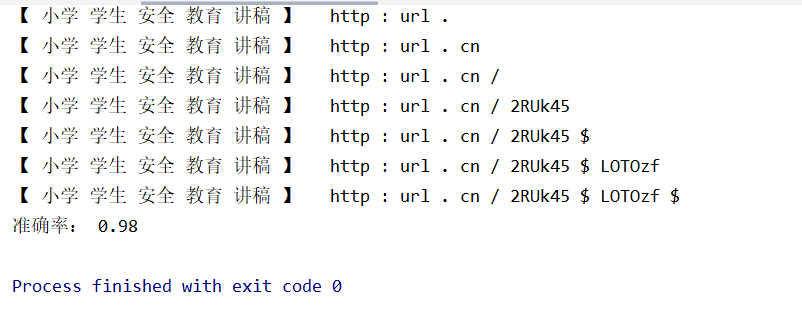

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持
Original: https://blog.csdn.net/weixin_42947172/article/details/116905192
Author: 贝加尔湖畔_tq
Title: python –利用朴素贝叶斯进行文本分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/547925/
转载文章受原作者版权保护。转载请注明原作者出处!