



作者:景
单位:燕山大学
; 前言
先说说通常意义上的预训练模型,以BERT为例,它采用大规模预料对Transformer编码器进行预训练,保存编码器参数后接下游任务,针对不同的下游任务采取不同的微调措施,例如接分类器、接解码器等。这么做的好处在于”对症下药”,但实则可以看做是妥协的产物——因为在谷歌刚提出BERT的时候,并没有针对”只编不解”这个问题的良好对策,bert在编码器堆叠了12层,这12层模型的参数经过了大规模语料的千锤百炼,对文本特征的捕获能力是极强的,但是其下游任务(这里特指需要解码的生成式任务)却只是经过了特定的小规模语料的训练,编码器和解码器对文本特征的捕获能力不一致,存在一种虎头蛇尾的现象。同时,bert的预训练任务——完形填空,也不一定适配下游的所有任务。
那么,有没有一种预训练方法,能够涵盖编码器、解码器,让编解码器拥有同等捕获文本特征的能力呢?假设有的话,不难想象,它在解决序列到序列这一类问题的时候,应当超越单纯的自编码模型和自回归模型。
今天笔者要讲述的论文,就是基于这一点出发的。
BART:Bidirectional and Auto-Regressive Transformers ,字面意思为双向自回归Transformer,依旧是基于Transformer改造出的模型。在GPT分走了Transformer的解码器部分,BERT分走了Transformer的编码器部分之后,BART终于将”老父亲”的所有”家产”一起打包带走。
贡献
- 提出使用多种噪声破坏原文本,再将残缺文本通过序列到序列的任务重新复原的预训练任务
- BART模型的提出解决了预训练模型编码器、解码器表征能力不一致的问题
- 在2019年生成式NLP任务的榜单上刷新了多个SOTA,验证了模型的有效性与先进性
模型
BART uses the standard sequence-to-sequence Transformer architecture , except, following GPT, that we modify ReLU activa-tion functions to GeLUs (Hendrycks & Gimpel, 2016)and initialise parameters from N(0,0.02). For ourbase model, we use 6 layers in the encoder and de-coder, and for our large model we use 12 layers ineach. The architecture is closely related to that used inBERT, with the following differences: (1) each layer ofthe decoder additionally performs cross-attention overthe final hidden layer of the encoder (as in the trans-former sequence-to-sequence model); and (2) BERTuses an additional feed-forward network before word-prediction, which BART does not. In total, BART con-tains roughly 10% more parameters than the equiva-lently sized BERT model.
BART模型使用了标准的Transformer结构为基础,并吸纳借鉴了BERT和GPT的优点,做出了自己的改进:
- 解码器模块参考GPT:将ReLU激活函数替换为GeLU激活函数
- 编码器模块区别于BERT:舍弃了前馈神经网络模块,精简了模型参数
- 编解码器衔接部分参考了Transformer:解码器的每一层都要对编码器最后一层的输出信息进行交叉注意力计算(也就是编解码注意力机制)
预训练任务的设置
BART的预训练任务设置可谓是模型的核心理念。
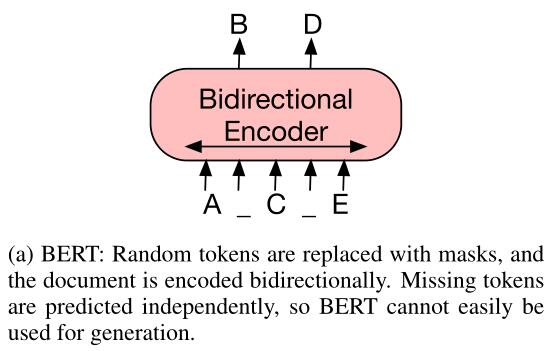
上图a哪怕不看图注,也可以一眼看出是BERT的预训练任务设置,随机掩盖一部分(15%)的词汇,整个预训练过程就是 完形填空:盖词→预测→预测错误计算损失→反向调参;
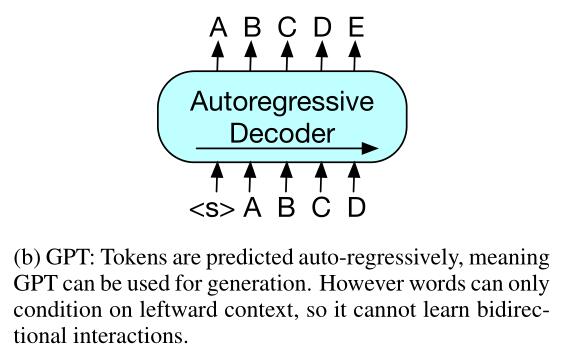
图b是GPT内置的预训练任务,采用的是自回归机制:预测下一个字→预测错误→反向调参→继续预测下一个字。
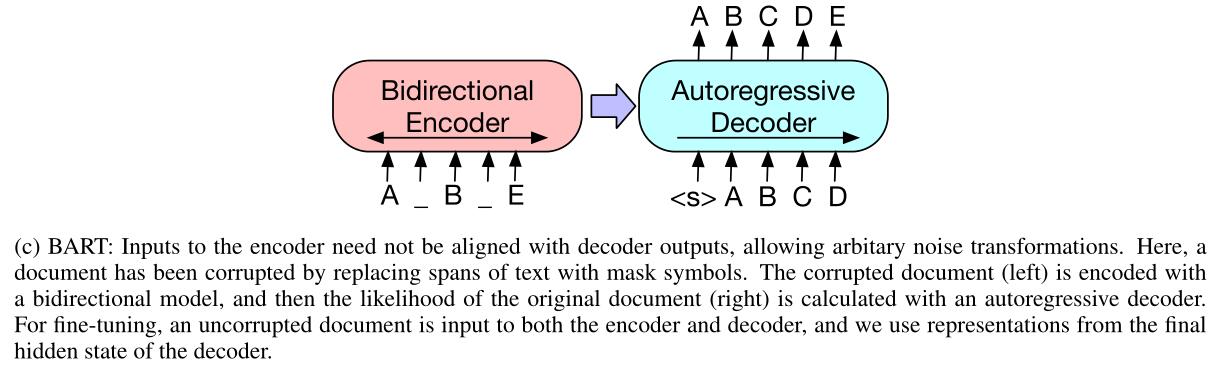
在BART模型中,原始文本参与了两个过程,如上图c所示:
1. 添加噪声随机进行”破坏”后输入编码器,噪声的设置方式包括但不限于掩码、乱序等,如下图所示。
2. 添加起始标记后从解码器输入。

单从上边两个数据流向来看,BART与BERT和GPT区别并不大,巧妙的是作者设置将残缺文本经过编码器的输出结合了自回归解码器,让模型针对原文本先做了 完形填空,接着做 默写,先训练了编码,再训练了解码,最终的预训练目标又回归到原文本,充分利用了编码器和解码器的优点来提升自身的性能。
; 微调
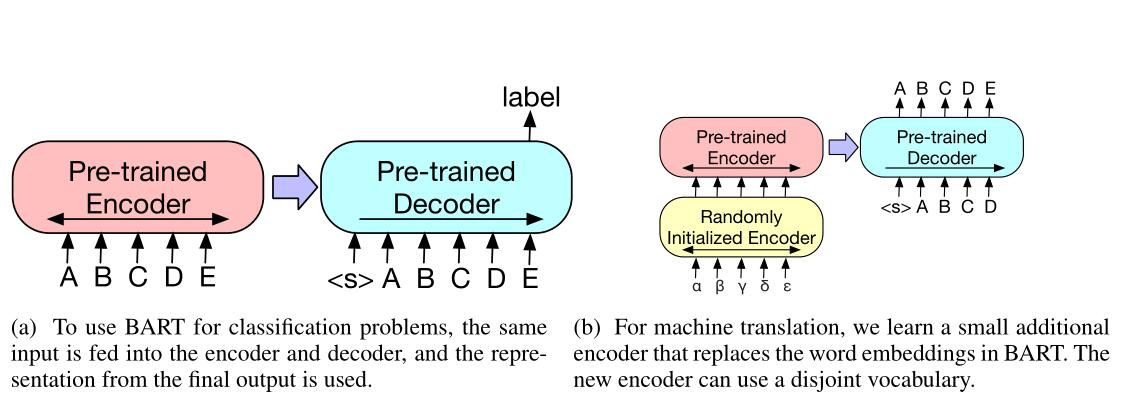
BART模型的下游任务接法如上所示,对于分类任务,编码输入和解码输入保持一致性;对于生成式任务,则编码器输入为源文本,解码器输入为目标文本。
实验结果展示
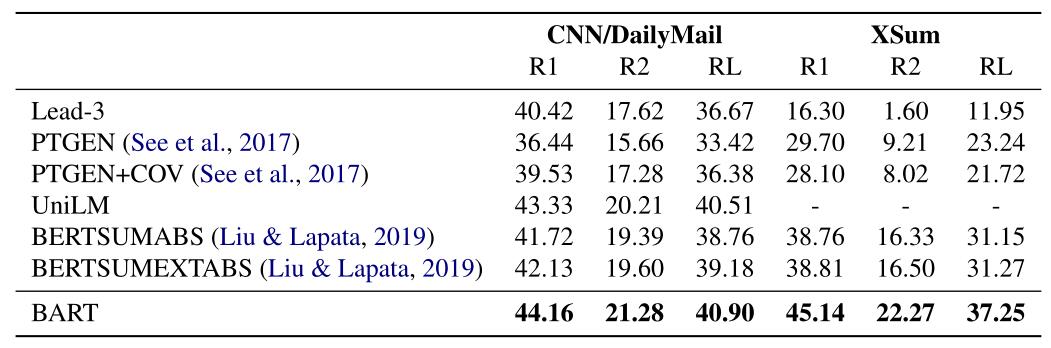
在各个数据集上的指标对比如下。
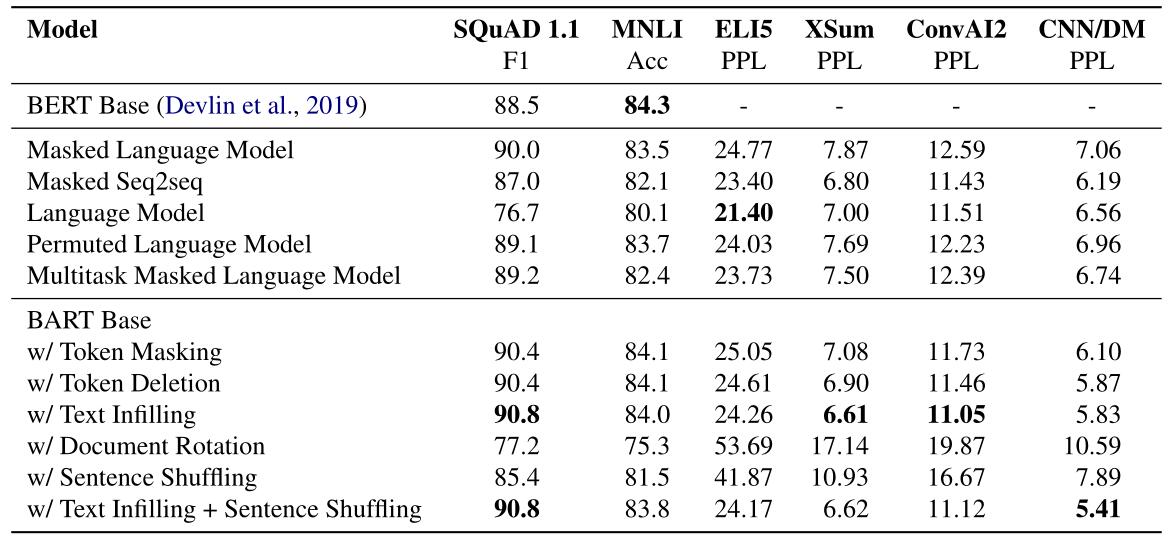
各大large版模型的效果对比:
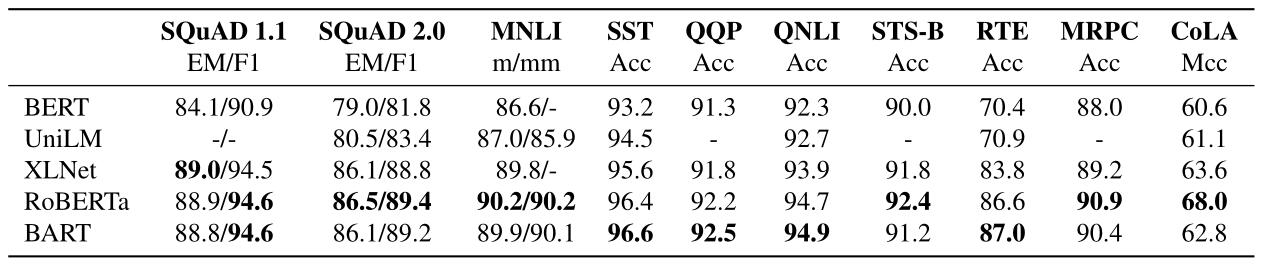
在两大摘要数据集上的实验结果:
; 结论
作者提出了一种预处理模型BART,可以在训练过程中将残缺文档映射到原始文档。BART在分类式任务上取得了与RoBERTa相似的表现,同时在一些文本生成任务上取得了新的最先进的结果。
Original: https://blog.csdn.net/u011150266/article/details/117742695
Author: 期待成功
Title: 论文笔记| BART:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545289/
转载文章受原作者版权保护。转载请注明原作者出处!