

百度BML&飞桨训练营(十二)【paddle- NLP】评论观点抽取和属性级情感分析
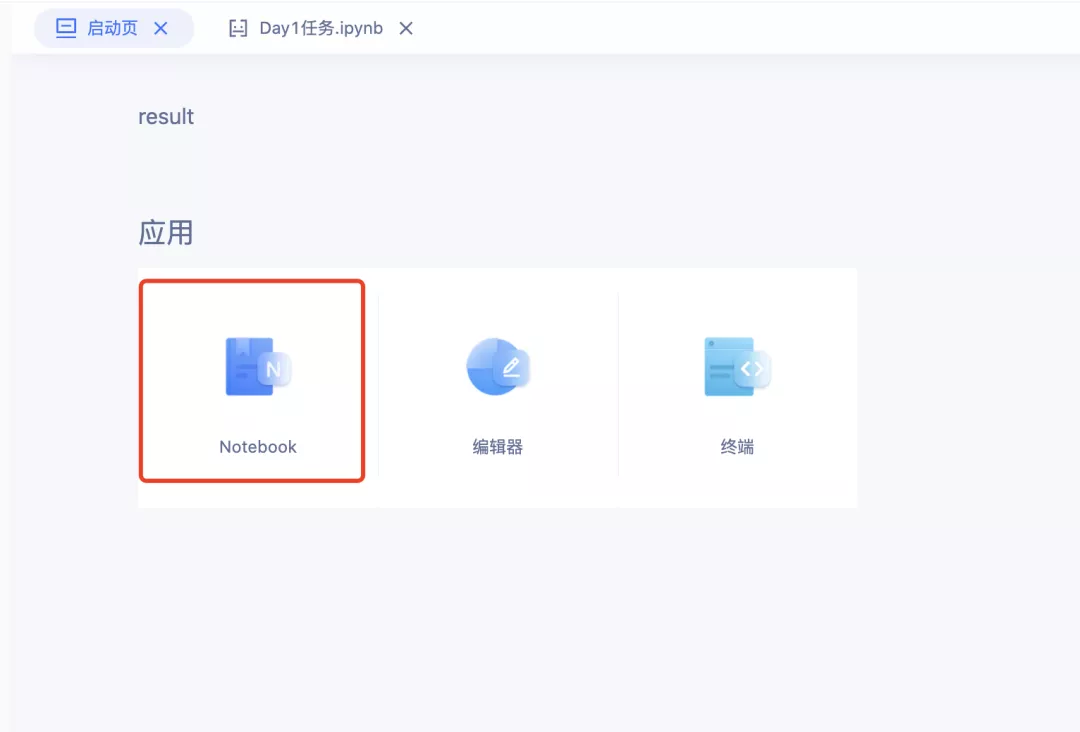
点击Notebook,创建”NLP通用”
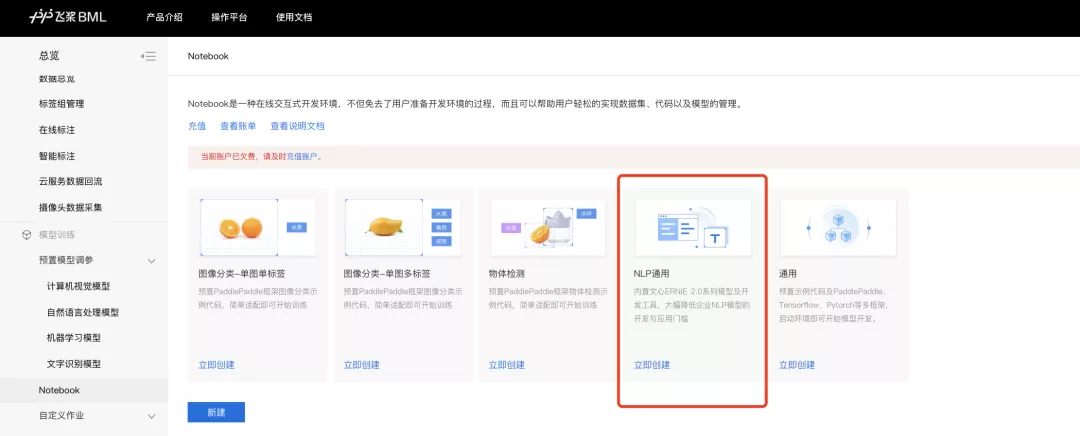

填写任务信息
下载数据集和相关依赖文件至本地
下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/125082
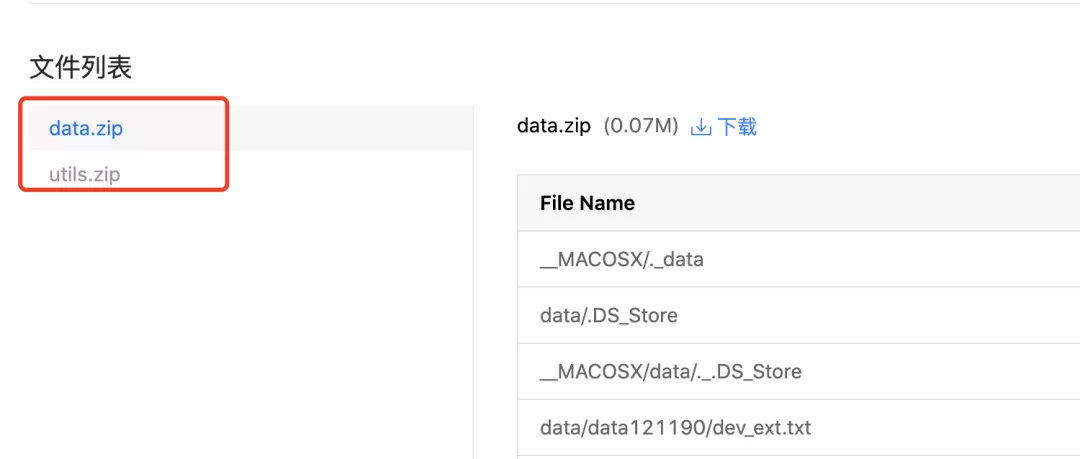
1.找到创建的Notebook任务,点击配置
开发语言:Python3.7
AI框架:PaddlePaddle2.0.0
资源规格:GPU V100
2.打开Notebook

3.创建一个Notebook,选择Python3
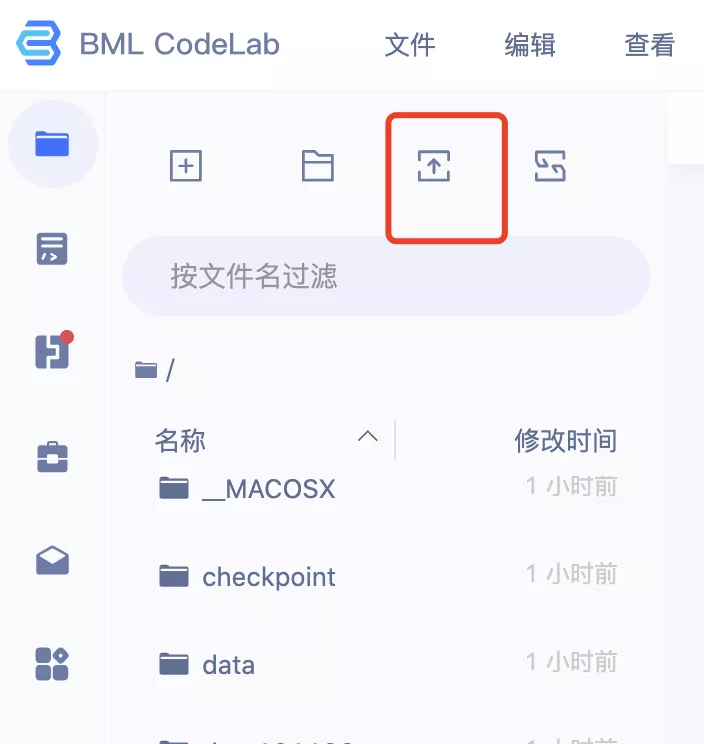
第二步:上传数据集和模型依赖文件至Notebook
1.下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/125082
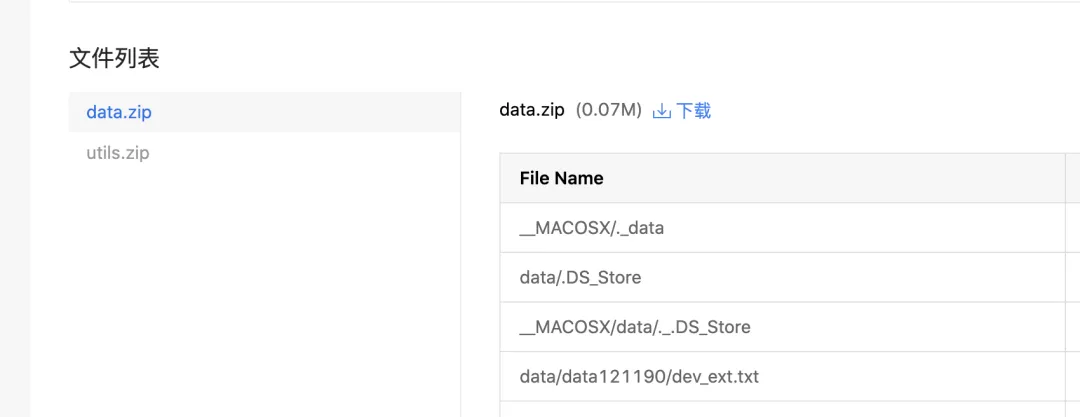
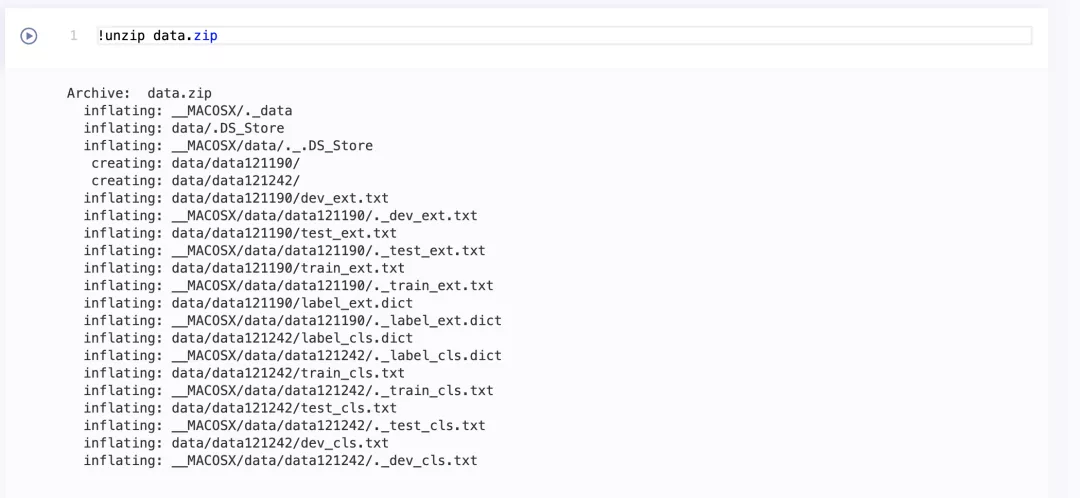
2.解压数据集和依赖文件
!unzip data.zip
!unzip utils.zip
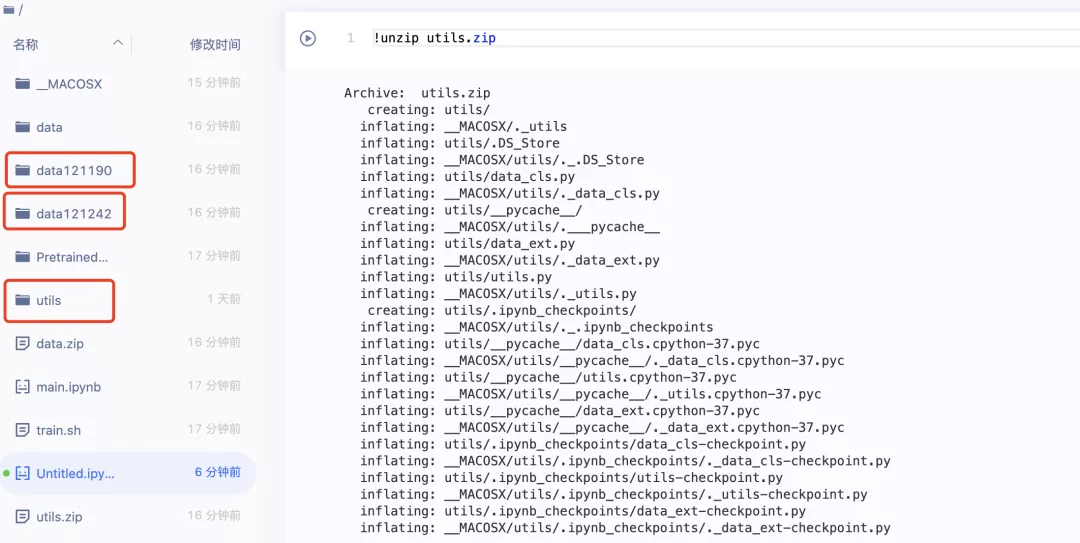
将数据集和文件剪切至Notebook的根目录,位置如下图所示
第三步:配置环境和安装PaddleNLP
!pip install paddlepaddle-gpu==2.2.1.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
!pip install –upgrade paddlenlp
第四步:处理数据集
1.数据加载
将训练、评估和测试数据集,以及标签词典加载到内存中。相关代码如下:
import os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import ChunkEvaluator
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed
from utils import data_ext, data_cls
train_path = "/home/work/data121190/train_ext.txt"
dev_path = "/home/work/data121190/dev_ext.txt"
test_path = "/home/work/data121190/test_ext.txt"
label_path = "/home/work/data121190/label_ext.dict"
label2id, id2label = data_ext.load_dict(label_path)
train_ds = load_dataset(data_ext.read, data_path=train_path, lazy=False)
dev_ds = load_dataset(data_ext.read, data_path=dev_path, lazy=False)
test_ds = load_dataset(data_ext.read, data_path=test_path, lazy=False)
for example in train_ds[9:11]:
print(example)
2.将数据转换成特征形式
在将数据加载完成后,接下来,我们将各项数据集转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。
model_name = "skep_ernie_1.0_large_ch"
batch_size = 8
max_seq_len = 512
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(data_ext.convert_example_to_feature, tokenizer=tokenizer, label2id=label2id, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
test_ds = test_ds.map(trans_func, lazy=False)
for example in train_ds[9:11]:
print("input_ids: ", example[0])
print("token_type_ids: ", example[1])
print("seq_len: ", example[2])
print("label: ", example[3])
print()
3.构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype="int64"),
Pad(axis=0, pad_val= -1)
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(test_ds, batch_sampler=test_batch_sampler, collate_fn=batchify_fn)
第五步:模型构建与训练配置
1.模型构建
我们将基于SKEP模型实现图1所展示的评论观点抽取功能。具体来讲,我们将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列。接下来,我们将基于该向量序列进行预测每个位置上的输出标签。相应代码如下。
class SkepForTokenClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForTokenClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
sequence_output, _ = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
return logits
2.训练配置
接下来,定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
num_epoch = 3 #迭代次数
learning_rate = 3e-5 #学习率
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = "./checkpoint/"
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = ChunkEvaluator(label2id.keys())
第六步:模型训练与配置
1.本节我们将定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:
def evaluate(model, data_loader, metric):
model.eval()
metric.reset()
for idx, batch_data in enumerate(data_loader):
input_ids, token_type_ids, seq_lens, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
predictions = logits.argmax(axis=2)
num_infer_chunks, num_label_chunks, num_correct_chunks = metric.compute(seq_lens, predictions, labels)
metric.update(num_infer_chunks.numpy(), num_label_chunks.numpy(), num_correct_chunks.numpy())
precision, recall, f1 = metric.accumulate()
return precision, recall, f1
def train():
# start to train model
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, _, labels = batch_data
# logits: batch_size, seql_len, num_tags
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits.reshape([-1, len(label2id)]), labels.reshape([-1]), ignore_index=-1)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best_ext.pdparams")
print(f'evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final_ext.pdparams")
train()
2.接下来,我们将加载训练过程中评估效果最好的模型,并使用测试集进行测试。相关代码如下。
load model
model_path = "./checkpoint/best_ext.pdparams"
loaded_state_dict = paddle.load(model_path)
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
model.load_dict(loaded_state_dict)
evalute on test data
precision, recall, f1 = evaluate(model, test_loader, metric)
print(f'evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
模型精度显示如下:

第二步:数据处理
本实践中包含训练集、评估和测试3项数据集,以及1个标签词典。其中标签词典记录了两类情感标签:正向和负向。
另外,数据集中需要包含3列数据:文本串和相应的序列标签数据
1.数据加载
将训练、评估和测试数据集,以及标签词典加载到内存中。相关代码如下:
import os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import AccuracyAndF1
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed, decoding, is_aspect_first, concate_aspect_and_opinion, format_print
from utils import data_ext, data_cls
train_path = "/home/work/data121242/train_cls.txt"
dev_path = "/home/work/data121242/dev_cls.txt"
test_path = "/home/work/data121242/test_cls.txt"
label_path = "/home/work/data121242/label_cls.dict"
load and process data
label2id, id2label = data_cls.load_dict(label_path)
train_ds = load_dataset(data_cls.read, data_path=train_path, lazy=False)
dev_ds = load_dataset(data_cls.read, data_path=dev_path, lazy=False)
test_ds = load_dataset(data_cls.read, data_path=test_path, lazy=False)
print examples
for example in train_ds[:2]:
print(example)
2.将数据转换成特征形式
在将数据加载完成后,接下来,我们将各项数据集转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。
model_name = "skep_ernie_1.0_large_ch"
batch_size = 8
max_seq_len = 512
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(data_cls.convert_example_to_feature, tokenizer=tokenizer, label2id=label2id, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
test_ds = test_ds.map(trans_func, lazy=False)
print examples
print examples
for example in train_ds[:2]:
print("input_ids: ", example[0])
print("token_type_ids: ", example[1])
print("seq_len: ", example[2])
print("label: ", example[3])
print()
3. 构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。
第三步:模型构建
将基于SKEP模型实现图1所展示的评论观点抽取功能。具体来讲,我们将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列。我们使用CLS位置对应的输出向量进行情感分类。相应代码如下。
class SkepForSequenceClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForSequenceClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
第四步:训练配置
定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
model hyperparameter setting
num_epoch = 3
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = "./checkpoint/"
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = AccuracyAndF1()
第五步:模型训练与测试
1.模型训练
定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:
def evaluate(model, data_loader, metric):
model.eval()
metric.reset()
for batch_data in data_loader:
input_ids, token_type_ids, _, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
correct = metric.compute(logits, labels)
metric.update(correct)
accuracy, precision, recall, f1, _ = metric.accumulate()
return accuracy, precision, recall, f1
def train():
# start to train model
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, _, labels = batch_data
# logits: batch_size, seql_len, num_tags
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits, labels)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
accuracy, precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best_cls.pdparams")
print(f'evalution result: accuracy:{accuracy:.5f} precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final_cls.pdparams")
train()
2.模型测试
将加载训练过程中评估效果最好的模型,并使用测试集进行测试。相关代码如下。
load model
model_path = "./checkpoint/best_cls.pdparams"
loaded_state_dict = paddle.load(model_path)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
model.load_dict(loaded_state_dict)
accuracy, precision, recall, f1 = evaluate(model, test_loader, metric)
print(f'evalution result: accuracy:{accuracy:.5f} precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
模型精度如下:

第二步:全模型推理
开源了基于全量数据训练好的评论观点抽取模型和属性级情感分类模型,我们可以使用下面的命令进行下载,并基于下载好的模型进行全流程情感分析预测。
1.下载开源模型
下载评论观点抽取模型
!wget https://bj.bcebos.com/paddlenlp/models/best_ext.pdparams
下载属性级情感分类模型
!wget https://bj.bcebos.com/paddlenlp/models/best_cls.pdparams
label_ext_path = "/home/work/data/data121190/label_ext.dict"
label_cls_path = "/home/work/data/data121242/label_cls.dict"
ext_model_path = "/home/work/best_ext.pdparams"
cls_model_path = "/home/work/best_cls.pdparams"
model_name = "skep_ernie_1.0_large_ch"
ext_label2id, ext_id2label = data_ext.load_dict(label_ext_path)
cls_label2id, cls_id2label = data_cls.load_dict(label_cls_path)
tokenizer = SkepTokenizer.from_pretrained(model_name)
print("label dict loaded.")
ext_state_dict = paddle.load(ext_model_path)
ext_skep = SkepModel.from_pretrained(model_name)
ext_model = SkepForTokenClassification(ext_skep, num_classes=len(ext_label2id))
ext_model.load_dict(ext_state_dict)
print("extraction model loaded.")
cls_state_dict = paddle.load(cls_model_path)
cls_skep = SkepModel.from_pretrained(model_name)
cls_model = SkepForSequenceClassification(cls_skep, num_classes=len(cls_label2id))
cls_model.load_dict(cls_state_dict)
print("classification model loaded.")
3.
def predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512):
ext_model.eval()
cls_model.eval()
encoded_inputs = tokenizer(list(input_text), is_split_into_words=True, max_seq_len=max_seq_len,)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# extract aspect and opinion words
logits = ext_model(input_ids, token_type_ids=token_type_ids)
predictions = logits.argmax(axis=2).numpy()[0]
tag_seq = [ext_id2label[idx] for idx in predictions][1:-1]
aps = decoding(input_text, tag_seq)
# predict sentiment for aspect with cls_model
results = []
for ap in aps:
aspect = ap[0]
opinion_words = list(set(ap[1:]))
aspect_text = concate_aspect_and_opinion(input_text, aspect, opinion_words)
encoded_inputs = tokenizer(aspect_text, text_pair=input_text, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
logits = cls_model(input_ids, token_type_ids=token_type_ids)
prediction = logits.argmax(axis=1).numpy()[0]
result = {"aspect": aspect, "opinions": opinion_words, "sentiment": cls_id2label[prediction]}
results.append(result)
# print results
format_print(results)
max_seq_len = 512
input_text = "环境装修不错,也很干净,前台服务非常好"
predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
input_text = "蛋糕味道不错,很好吃,店家很耐心,服务也很好,很棒"
predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
另外也可使用保存在checkpoint里的bestmodel文件进行预测,修改预测的model_path为checkpoint中的model即可。
第三步:结果示例
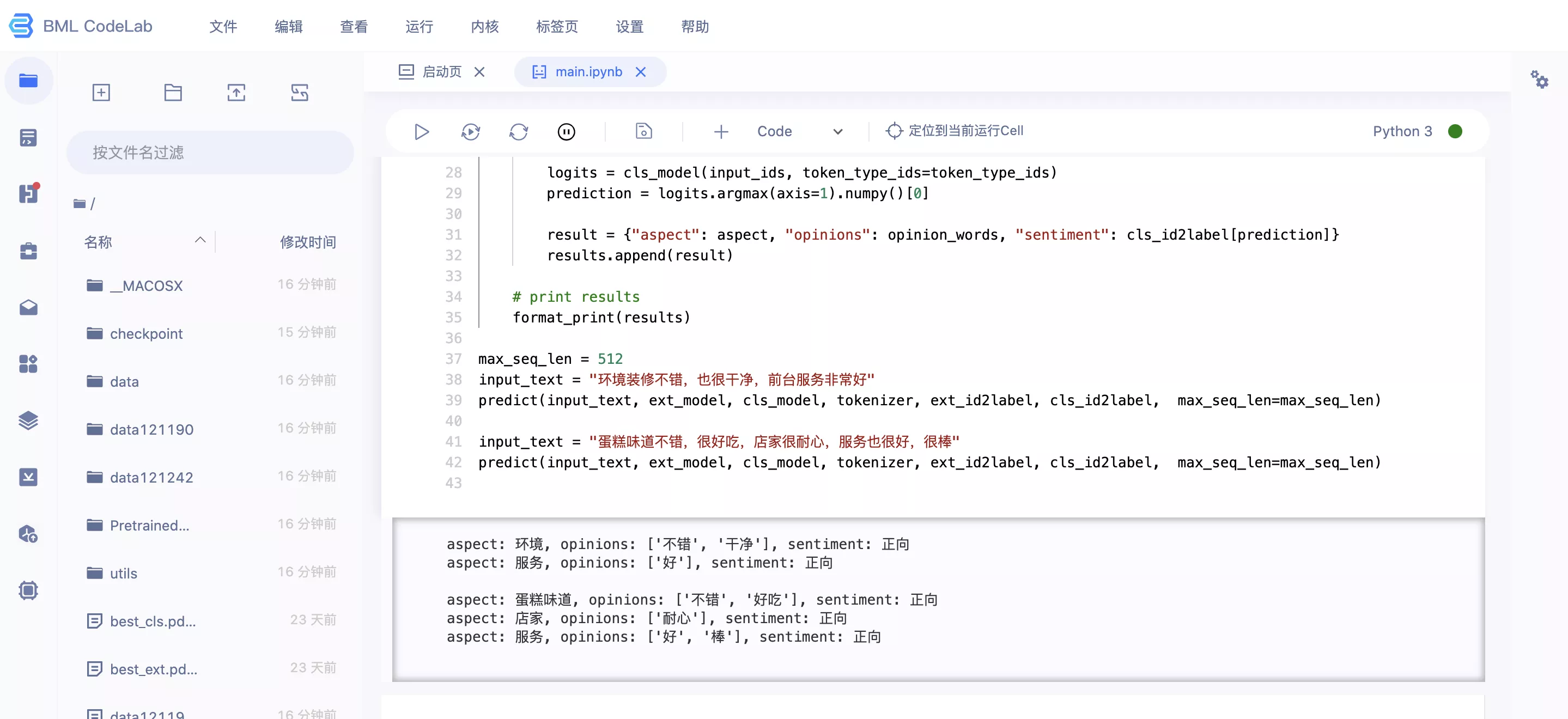
Original: https://blog.csdn.net/weixin_47567401/article/details/122486585
Author: 翼达口香糖
Title: 百度BML&飞桨训练营(十二)【paddle- NLP】评论观点抽取和属性级情感分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545259/
转载文章受原作者版权保护。转载请注明原作者出处!