

NLP经典论文:NNLM 笔记
- 论文
- 介绍
* - 优点
- 缺点
- 模型结构
* - 整体模型
– - 输入层
– - 隐藏层
– - 输出层
– - 优化目标
– - 示例
- 文章部分翻译
* - Abstract
- 相关的笔记
- 相关代码
* - pytorch
- tensorflow
– - pytorch API:
论文
原论文:《A Neural Probabilistic Language Model》
介绍
2003/02发表的文章,提出了神经网路语言模型。该模型使用前 n − 1 n-1 n −1 个词来预测第 n n n 个词,计算概率 p ( w n ∣ w 1 , w 2 , . . . , w n − 1 ) p(w_n|w_{1}, w_{2}, …, w_{n-1})p (w n ∣w 1 ,w 2 ,…,w n −1 )。首先将前 n − 1 n-1 n −1 个词用 one-hot 表示,然后使用投影矩阵降维,再将降维后的 n − 1 n-1 n −1 个词的表示拼接起来,输入到单层的使用 tanh 激活的神经网络中,得到一个富含输入信息的 hidden state 向量,或者说是 context 向量,再经过一个线性层得到字典中词得预测分值,经过softmax后得到每个词的概率,其中概率最大的就是模型的预测词。
优点
由于NNLM模型使用了低维紧凑的词向量对上文进行表示,这解决了词袋模型带来的数据稀疏、语义鸿沟等问题。
缺点
模型在神经网络层参数量巨大。
模型结构
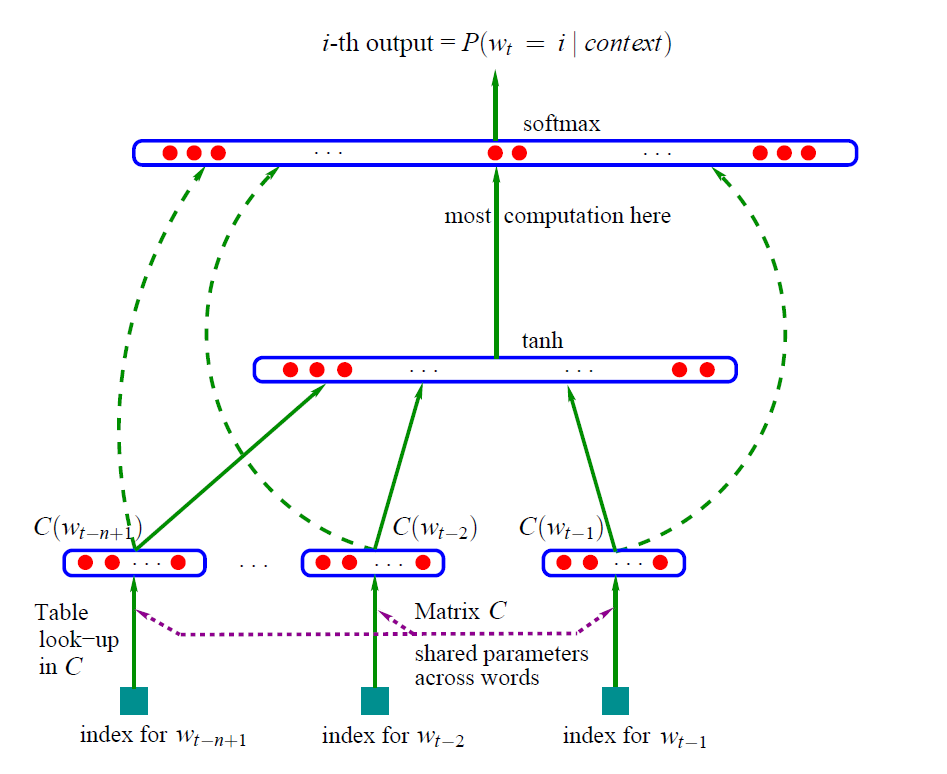

; 整体模型
输入
w t − n + 1 , w t − n + 2 , . . . , w t − 1 w_{t-n+1}, w_{t-n+2}, …, w_{t-1}w t −n +1 ,w t −n +2 ,…,w t −1 为输入长度为n-1的一串文本,文本通过one-hot表示,w ∈ R V × 1 w \in R^{V \times 1}w ∈R V ×1,V为字典大小,包含词的总数。
输出
f ( w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) = w t ^ f(w_{t-n+1}, w_{t-n+2}, …, w_{t-1})=\hat{w_t}f (w t −n +1 ,w t −n +2 ,…,w t −1 )=w t ^,w ^ \hat{w}w ^为预测词,为m a x { p } max{\boldsymbol{p}}m a x {p }所对应的词,其中
p = { p ( w 1 ∣ w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) , p ( w 2 ∣ w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) , . . . , p ( w i ∣ w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) , . . . } , i = 1 , 2 , 3 , . . . , V \boldsymbol{p}={p(w_1|w_{t-n+1}, w_{t-n+2}, …, w_{t-1}), p(w_2|w_{t-n+1}, w_{t-n+2}, …, w_{t-1}), …, p(w_i|w_{t-n+1}, w_{t-n+2}, …, w_{t-1}),…}, i=1, 2, 3, …, V p ={p (w 1 ∣w t −n +1 ,w t −n +2 ,…,w t −1 ),p (w 2 ∣w t −n +1 ,w t −n +2 ,…,w t −1 ),…,p (w i ∣w t −n +1 ,w t −n +2 ,…,w t −1 ),…},i =1 ,2 ,3 ,…,V
意思就是给定n-1个输入词(w t − n + 1 , w t − n + 2 , . . . , w t − 1 w_{t-n+1}, w_{t-n+2}, …, w_{t-1}w t −n +1 ,w t −n +2 ,…,w t −1 ),预测第n个词w t w_{t}w t 时,{ p } {\boldsymbol{p}}{p }中概率最大的那个p ( w i ∣ w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) p(w_i|w_{t-n+1}, w_{t-n+2}, …, w_{t-1})p (w i ∣w t −n +1 ,w t −n +2 ,…,w t −1 )所对应的那个词w i w_i w i ,就是预测输出的词。
整体流程

; 输入层

输入
w t − n + 1 , w t − n + 2 , . . . , w t − 1 w_{t-n+1}, w_{t-n+2}, …, w_{t-1}w t −n +1 ,w t −n +2 ,…,w t −1 为输入长度为n-1的一串文本,文本通过one-hot表示,w ∈ R V × 1 w \in R^{V \times 1}w ∈R V ×1,V为字典大小,包含词的总数。
输出
x = C t − n + 1 ⊕ C t − n + 2 ⊕ . . . ⊕ C t − 1 , x ∈ R m ( n − 1 ) × 1 \boldsymbol{x}=C_{t-n+1}\oplus C_{t-n+2}\oplus …\oplus C_{t-1}, \boldsymbol{x}\in R^{m(n-1)\times 1}x =C t −n +1 ⊕C t −n +2 ⊕…⊕C t −1 ,x ∈R m (n −1 )×1
其中,⊕ \oplus ⊕为拼接操作,C i = C w i C_{i}=\boldsymbol{C}w_{i}C i =C w i ,C i ∈ R m × 1 C_i \in R^{m\times 1}C i ∈R m ×1,C \boldsymbol{C}C为变换矩阵,投影矩阵,C ∈ R m × V \boldsymbol{C} \in R^{m \times V}C ∈R m ×V,把one-hot表示的稀疏向量从稀疏的V维空间投影到稠密的m维空间。然后再将C i C_i C i 拼接起来,形成上下文信息,传递给下一层。
隐藏层

; 输入
x = C t − n + 1 ⊕ C t − n + 2 ⊕ . . . ⊕ C t − 1 , x ∈ R m ( n − 1 ) × 1 \boldsymbol{x}=C_{t-n+1}\oplus C_{t-n+2}\oplus …\oplus C_{t-1}, \boldsymbol{x}\in R^{m(n-1)\times 1}x =C t −n +1 ⊕C t −n +2 ⊕…⊕C t −1 ,x ∈R m (n −1 )×1
输出
t a n h ( H x + d ) ∈ R h × 1 , H ∈ R h × m ( n − 1 ) , d ∈ R h × 1 tanh(\boldsymbol{H}\boldsymbol{x}+\boldsymbol{d})\in R^{h \times 1}, \boldsymbol{H}\in R^{h \times m(n-1)}, \boldsymbol{d}\in R^{h \times 1}t a n h (H x +d )∈R h ×1 ,H ∈R h ×m (n −1 ),d ∈R h ×1,h为隐藏层神经元个数。
这层提取输入的特征,传给下一层。
输出层
; 输入
- 输入层与输出层连接时:t a n h ( H x + d ) tanh(\boldsymbol{H}\boldsymbol{x}+\boldsymbol{d})t a n h (H x +d ),x x x
- 输入层与输出层不连接时:t a n h ( H x + d ) ∈ R h × 1 tanh(\boldsymbol{H}\boldsymbol{x}+\boldsymbol{d})\in R^{h \times 1}t a n h (H x +d )∈R h ×1
输出
w t ^ \hat{w_t}w t ^
过程
- 输入层与输出层连接时: y = b + W x + U t a n h ( H x + d ) \boldsymbol{y} = \boldsymbol{b}+\boldsymbol{Wx}+\boldsymbol{U}tanh(\boldsymbol{H}\boldsymbol{x}+\boldsymbol{d})y =b +W x +U t a n h (H x +d ) 其中b ∈ R V × 1 , W ∈ R V × m ( n − 1 ) , U ∈ R V × h \boldsymbol{b}\in R^{V \times 1}, \boldsymbol{W}\in R^{V \times m(n-1)}, \boldsymbol{U}\in R^{V \times h}b ∈R V ×1 ,W ∈R V ×m (n −1 ),U ∈R V ×h,通常W \boldsymbol{W}W为0 \boldsymbol{0}0
- 输入层与输出层不连接时: y = b + U t a n h ( H x + d ) , y ∈ R V × 1 \boldsymbol{y} = \boldsymbol{b}+\boldsymbol{U}tanh(\boldsymbol{H}\boldsymbol{x}+\boldsymbol{d}), \boldsymbol{y} \in R^{V \times 1}y =b +U t a n h (H x +d ),y ∈R V ×1
y \boldsymbol{y}y可以理解为融合特征之后,对每一个字典里面的词进行预测值打分,打分的值并不为概率,y \boldsymbol{y}y经过softmax,才是最后的预测概率p , p ∈ R V × 1 \boldsymbol{p}, \boldsymbol{p} \in R^{V \times 1}p ,p ∈R V ×1
p = e y ∑ i V e y i \boldsymbol{p}=\frac{e^{\boldsymbol{y}}}{\sum\limits_{i}^{V}e^{y_i}}p =i ∑V e y i e y
softmax结构

本文的分值y为图中的z,本文的概率p为图中的y。
{ p } {\boldsymbol{p}}{p }中概率最大的那个p ( w i ∣ w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) p(w_i|w_{t-n+1}, w_{t-n+2}, …, w_{t-1})p (w i ∣w t −n +1 ,w t −n +2 ,…,w t −1 )所对应的那个词w i w_i w i ,就是预测输出的词。
; 优化目标
交叉熵cross entropy loss
这里使用的是交叉熵cross entropy loss
C E H ( p , q ) = − ∑ x ∈ X p ( x ) log q ( x ) CEH(p,q)=-\sum\limits_{x \in \boldsymbol{X}} p(x)\log q(x)C E H (p ,q )=−x ∈X ∑p (x )lo g q (x )
其中X \boldsymbol{X}X为x的取值范围,多分类任务中代表类别。
这里有2个模型,一个x的真实模型,一个是构造的模型,我们希望构造的模型尽量接近真实模型。交叉熵越小,表示两个概率分布越靠近。p(x)为x的真实概率分布,q(x)为构造模型的概率分布。
NNLM模型的优化目标
l o s s = m i n ( − ∑ t = 1 T log p ( w t ∣ w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) ) loss=min(-\sum\limits_{t=1}^T\log p(w_t|w_{t-n+1}, w_{t-n+2}, …, w_{t-1}))l o s s =m i n (−t =1 ∑T lo g p (w t ∣w t −n +1 ,w t −n +2 ,…,w t −1 ))
待优化的参数为:b , d , W , U , H , C \boldsymbol{b}, \boldsymbol{d}, \boldsymbol{W}, \boldsymbol{U}, \boldsymbol{H}, \boldsymbol{C}b ,d ,W ,U ,H ,C
对于一个输入样本w t − n + 1 , w t − n + 2 , . . . , w t − 1 w_{t-n+1}, w_{t-n+2}, …, w_{t-1}w t −n +1 ,w t −n +2 ,…,w t −1 来说,真实概率为one-hot编码值,模型的预测概率为p \boldsymbol{p}p
示例
原文为:我/爱/中国/共产党,假设字典大小V=4
f ( w t − n + 1 , w t − n + 2 , . . . , w t − 1 ) = w t ^ f(w_{t-n+1}, w_{t-n+2}, …, w_{t-1})=\hat{w_t}f (w t −n +1 ,w t −n +2 ,…,w t −1 )=w t ^
w t − n + 1 , w t − n + 2 , . . . , w t − 1 w_{t-n+1}, w_{t-n+2}, …, w_{t-1}w t −n +1 ,w t −n +2 ,…,w t −1 为:我/爱/中国
预测词w t ^ \hat{w_t}w t ^为:共产党
词one-hot编码我[1,0,0,0]爱[0,1,0,0]中国[0,0,1,0]共产党[0,0,0,1]
输入到NNLM模型中,最后得到的概率p = [ 0.1 , 0.1 , 0.2 , 0.6 ] \boldsymbol{p}=[0.1, 0.1, 0.2, 0.6]p =[0 .1 ,0 .1 ,0 .2 ,0 .6 ]
p \boldsymbol{p}p
概率值
p ( 我 ∣ 我 , 爱 , 中 国 ) p(我\mid我, 爱, 中国)p (我∣我,爱,中国)
0.1
p ( 爱 ∣ 我 , 爱 , 中 国 ) p(爱\mid我, 爱, 中国)p (爱∣我,爱,中国)
0.1
p ( 中 国 ∣ 我 , 爱 , 中 国 ) p(中国\mid我, 爱, 中国)p (中国∣我,爱,中国)
0.2
p ( 共 产 党 ∣ 我 , 爱 , 中 国 ) p(共产党\mid我, 爱, 中国)p (共产党∣我,爱,中国)
0.6
p ( 共 产 党 ∣ 我 , 爱 , 中 国 ) p(共产党|我, 爱, 中国)p (共产党∣我,爱,中国)的概率最大,预测的词为:共产党
文章部分翻译
Abstract
相关的笔记
相关代码
pytorch
tensorflow
keras
pytorch API:
Original: https://blog.csdn.net/sinat_39448069/article/details/121223226
Author: 电信保温杯
Title: NLP经典论文:NNLM 笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545223/
转载文章受原作者版权保护。转载请注明原作者出处!