

2021SC@SDUSC
EmbedRank方法提取关键词的启动,在launch.py函数中。
引入项目中的其它模块:
import argparse
from configparser import ConfigParser
from swisscom_ai.research_keyphrase.embeddings.emb_distrib_local import EmbeddingDistributorLocal
from swisscom_ai.research_keyphrase.model.input_representation import InputTextObj
from swisscom_ai.research_keyphrase.model.method import MMRPhrase
from swisscom_ai.research_keyphrase.preprocessing.postagging import PosTaggingCoreNLP
from swisscom_ai.research_keyphrase.util.fileIO import read_file
提取关键词的函数:def extract_keyphrases(embedding_distrib, ptagger, raw_text, N, lang, beta=0.55, alias_threshold=0.7):
参数说明:
embedding_distrib:嵌入分发器对象请参见@嵌入分发器。
ptagger:位置标记对象请参见@PosTagger。
raw_text:一个包含要提取的行文本的字符串。
N:提取的关键词的数量。
lang:语言。
beta:MMR的测试系数(权衡信息性/多样性)
alias_threshold:将候选词组合为别名的阈值
返回值:包含三个元素的元组:
1)前N候选列表(如果没有足够的候选词,则更少)(字符串列表)2)关联相关性分数列表(浮点列表)3)列表,每个关键短语包含别名列表(字符串列表列表)
def extract_keyphrases(embedding_distrib, ptagger, raw_text, N, lang, beta=0.55, alias_threshold=0.7):
tagged = ptagger.pos_tag_raw_text(raw_text)
text_obj = InputTextObj(tagged, lang)
return MMRPhrase(embedding_distrib, text_obj, N=N, beta=beta, alias_threshold=alias_threshold)
def load_local_embedding_distributor():
config_parser = ConfigParser()
config_parser.read('config.ini')
sent2vec_model_path = config_parser.get('SENT2VEC', 'model_path')
return EmbeddingDistributorLocal(sent2vec_model_path)
def load_local_corenlp_pos_tagger():
config_parser = ConfigParser()
config_parser.read('config.ini')
host = config_parser.get('STANFORDCORENLPTAGGER', 'host')
port = config_parser.get('STANFORDCORENLPTAGGER', 'port')
return PosTaggingCoreNLP(host, port)
main函数:
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Extract keyphrases from raw text')
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument('-raw_text', help='raw text to process')
group.add_argument('-text_file', help='file containing the raw text to process')
parser.add_argument('-tagger_host', help='CoreNLP host', default='localhost')
parser.add_argument('-tagger_port', help='CoreNLP port', default=9000)
parser.add_argument('-N', help='number of keyphrases to extract', required=True, type=int)
args = parser.parse_args()
if args.text_file:
raw_text = read_file(args.text_file)
else:
raw_text = args.raw_text
embedding_distributor = load_local_embedding_distributor()
pos_tagger = load_local_corenlp_pos_tagger(args.tagger_host, args.tagger_port)
print(extract_keyphrases(embedding_distributor, pos_tagger, raw_text, args.N, 'en'))

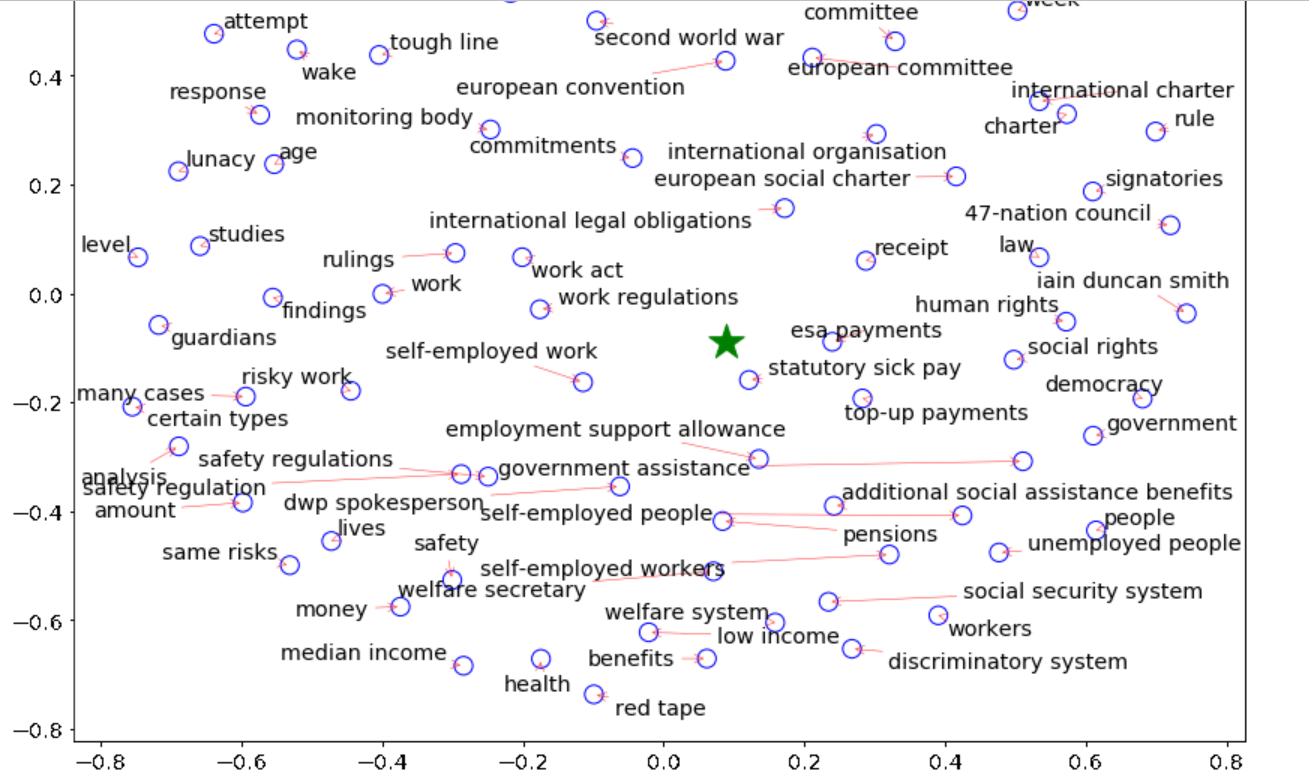
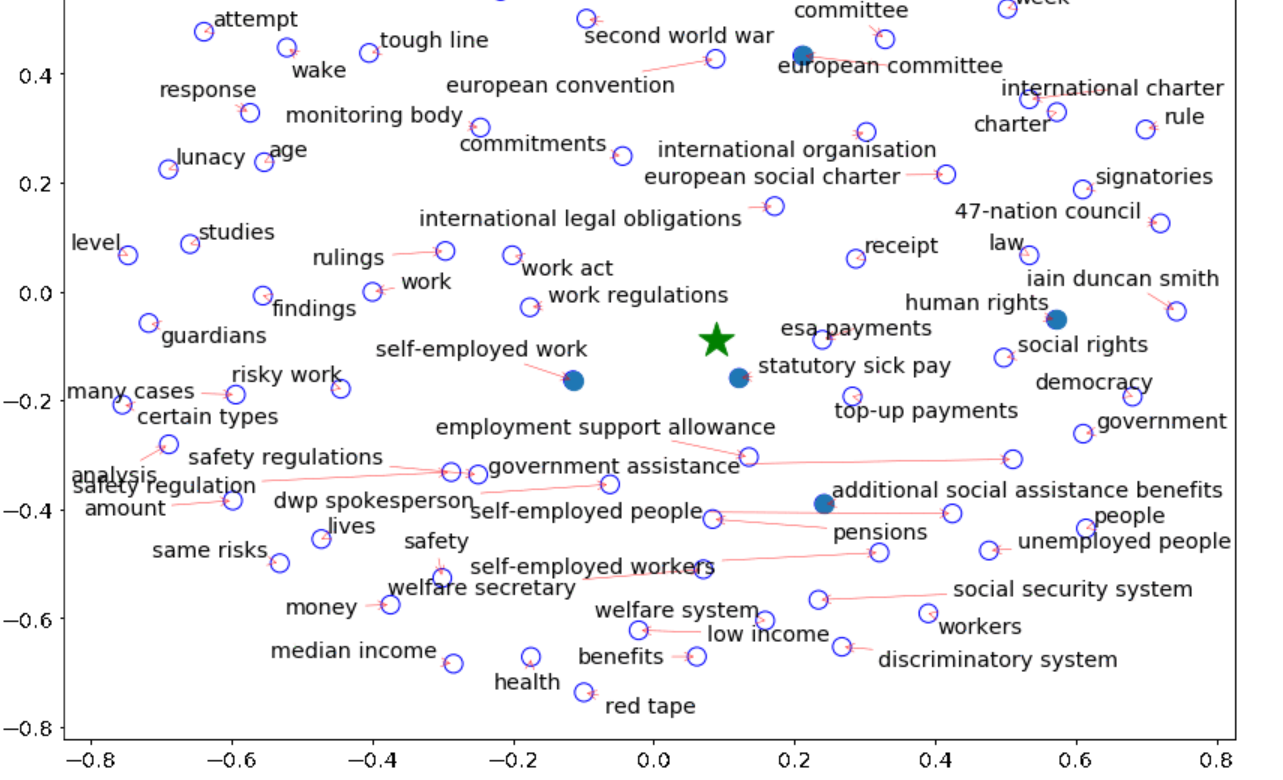
通过使用句子嵌入,嵌入秩将文档和候选短语都嵌入到相同的嵌入空间中。利用候选对象与文档之间的余弦相似度,利用最大边际相关性选择N个候选对象作为关键词,利用候选对象之间的余弦相似度来建模多样性。一个超参数,beta(default=0.55),控制着在提取关键短语时对信息性和多样性的重要性。(beta=1仅信息性,仅=0多样性)当调用extract_keyphrases时,您可以更改beta超参数值:
kp1 = launch.extract_keyphrases(embedding_distributor, pos_tagger, raw_text, 10, 'en', beta=0.8)
如果想复制论文的结果,必须将beta设置为1或0.5,并通过指定alias_threshold=1到extract_keyphrases方法来关闭别名特性。
Original: https://blog.csdn.net/qq_46765753/article/details/121939409
Author: gh冲
Title: blog14 launch.py
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545098/
转载文章受原作者版权保护。转载请注明原作者出处!