

- Embedding原理
1.1 基本原理
在自然语言处理中,embedding是一个重要的概念。那么Embedding是什么呢?
假设一个词库中有
 个单词,每个单词有对应的one-hot编码(),例如,apple为第二个单词,orange为第4756个单词,则对应的one-hot编码如下:
,
个单词,每个单词有对应的one-hot编码(),例如,apple为第二个单词,orange为第4756个单词,则对应的one-hot编码如下:
,
在onehot编码中,只有单词所在位置的数值为1,其他位置均为0。这种编码方式,
。而embedding 一方面可以改变这种相关单词相似度为0的问题,使得;另外一方面可以使得原来单词表示由的向量降维为的向量。
实现Embedding的方式为Embedding矩阵,词库中所有的
个单词共用一个Embedding矩阵,矩阵的每一列为对应单词的embedding向量,因此,用表示embedding matrix,有;为第个单词的embedding向量,为第个单词的one-hot向量,。可以看做是单词的编码(encoding)。图示如下:

图1. Embedding图示
Embedding不仅可以降维,还可以升维(相当于放大镜),参见https://zhuanlan.zhihu.com/p/164502624
学习Embedding矩阵的过程和神经网络中学习其他参数的过程类似,矩阵
一共有个参数。利用词库中的句子,可以构造监督学习神经网络,输入为上下文(Contents),输出为目标(Target,的向量,每个位置代表预测单词的权重)。根据选取上下文的方式,有基于数据窗的语言模型、有Skip-grams Model。同时,根据激活函数softmax的输出向量大小,有Hierarchical softmax,详细参见https://zhuanlan.zhihu.com/p/114538417。
1.2 pytorch中基本语法
在pytorch中的Torch.nn库中有embedding,其基本使用方法如下:
input_num = 10
output_dim = 3
content_num = 4
embedding = nn.Embedding(input_num, output_dim)
输入的上下文为 [[banana banana a eat] [cat drink, water, a]]
x = torch.LongTensor([[2,2,0,5], [4, 6,9,0]])
out = embedding(x)
print(out)
其中,
为词库大小,为词向量的大小(我们想要将one-hot转化为维的向量)。注意embedding初始化的时候为矩阵中的每个元素赋初值,通过输入上下文(这里输入两个样本,每个样本包含了4个上下文单词),训练矩阵。根据初始化而未经网络训练的矩阵,得到2个样本对应的4个上下文单词对应的4个词向量,结果如下:
>> tensor([[[-0.1218, 0.3078, -0.9995],
[-0.1218, 0.3078, -0.9995],
[-0.5878, 1.2404, 0.4759],
[ 0.2810, -0.1184, -0.0488]],
[[-0.3581, 1.6169, 0.9860],
[-0.6140, -0.4148, -1.7148],
[ 0.1756, -0.8653, -0.1736],
[-0.5878, 1.2404, 0.4759]]], grad_fn=)
对数据的解释如下:
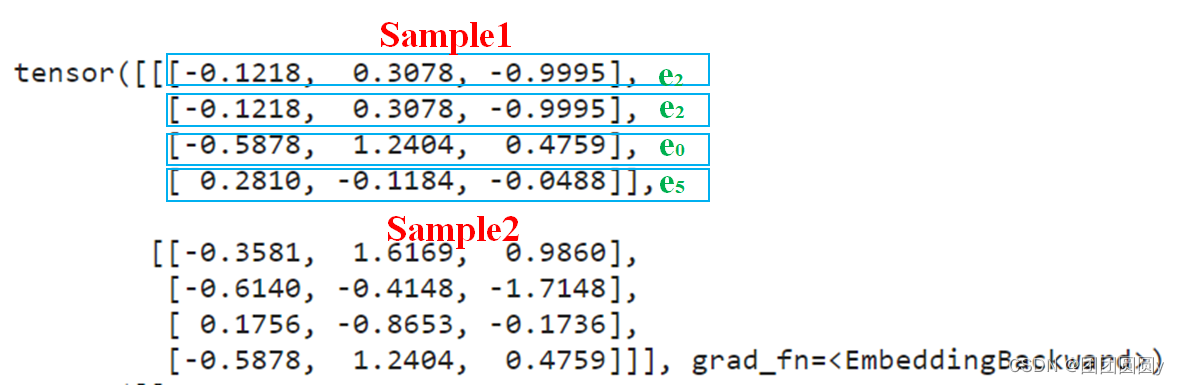
图2. embedding输出说明
下面,通过一个简单的例子,构建网络训练Embedding矩阵
。
- 实例
2.1 监督学习语言网络
这里为了展示怎么用pytorch.nn.embedding实现,胡乱邹个例子意思一下。句子以及对应的编码如下:
A cute cat drinks water and eats many big melons
0 1 2 3 4 5 6 7 8 9
那么,在该示例中,词库的单词数量为
,通过embedding,将其转化为的词向量,输入网络训练。例如,通过选取上下文的4个单词()预测目标单词,最终输出。
在这里我们输入数据为
、对应的原始编码,预测目标为和对应的one-hot编码,代码如下:
例如,0:a 1:cute 2:cat 3:drink 4: water 5:and 6:eat 7:many 8:big 9:melons
输入的上下文为 [cat drink a and] [water eat, melons, a]]
x = torch.LongTensor([[2,3,0,5], [4, 6,9,0]])
预测的target分别为water、big
target = torch.Tensor([[0,0,0,0,1,0,0,0,0,0], [0,0,0,0,0,0,0,0,1,0]])
构建的网络如下:

图3. 构建监督学习的语言模型
2.2 代码
构建网络代码如下,
class Model(torch.nn.Module):
def __init__(self, input_num, output_dim, content_num):
super(Model,self).__init__()
self.embedding = nn.Embedding(input_num, output_dim)
self.linear = nn.Linear(output_dim * content_num, input_num)
def forward(self, x):
out = self.embedding(x)
out = torch.flatten(out,1)
out = self.linear(out)
out = F.softmax(out)
return out
'''
input_num: 词库中一共有input_num个词
output_dim: Embedding转化为output_dim维度的词向量
content_num: 在网络中,输入上下文单词个数
flatten_num: 将上下文的词向量展开为flatten_num大小的向量,输入网络训练
'''
词库中一共有input_num个词;将其转化为output_dim维度的词向量,
例如,0:a 1:apple 2:banana 3:cut 4: cat 5:eat 6:drink 7:hi 8:tree 9:water
input_num = 10
output_dim = 3
content_num = 4
model = Model(input_num, output_dim, content_num)
model = model.to(device)
训练时的代码如下:
board = SummaryWriter('/kaggle/working/ML_Embedding/logs')
loss_function = nn.MSELoss()
opt = torch.optim.Adam(model.parameters(), lr=0.003, weight_decay=1e-3)
Epochs = 100
for epoch in range(Epochs):
pred = model(x)
loss = loss_function(pred, target)
#一般下面三行指令是放一起的
opt.zero_grad()
loss.backward()
opt.step()
print('epoch=',epoch,' train_loss=',loss.item())
board.add_scalar("Train_loss", loss.item(), epoch)
board.close()
这里只是简单实现以下,其中的损失函数可能在得到
之后,由于输出为多个,使用Loss_func = nn.CrossEntropyLoss()交叉熵函数可能更好,这里不再展示。
2.3 结果
loss下降的过程如下。

图4. 训练的loss收敛图
虽然是随便编的例子,我们也可以看到,在训练过程中,loss逐渐下降并收敛。
Original: https://blog.csdn.net/qq_45031079/article/details/124548471
Author: 团团圆圆y
Title: 自然语言处理—Embedding简单应用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545066/
转载文章受原作者版权保护。转载请注明原作者出处!