

来源 | Natural Language Processing with PyTorch
作者 | Rao,McMahan
译者 | Liangchu
校对 | gongyouliu
编辑 | auroral-L
全文共5970字,预计阅读时间30分钟。
第六章 自然语言处理的序列模型
6.1 循环神经网络简介
6.1.1 实现Elman RNN
6.2 示例:使用字符 RNN 分类姓氏国籍
6.2.1 SurnameDataset数据集
6.2.2 向量化数据结构
6.2.3 SurnameClassifier模型
6.2.4 训练例程和结果
6.3 总结
序列是项的有序集合。传统的机器学习假设数据点是独立同分布的(independently and identically distributed,IID),但在许多情况下(如语言、语音和时间序列数据),一个数据项取决于它前后的数据项,这种数据也称为序列数据(sequence data)。在人类语言中,序列信息无处不在:例如,语音可以被看作是音素(phoneme)的基本单元序列。在像英语这样的语言中,句子中的单词不是毫无章法的,它们可能会被它前面或后面的词所束缚;例如,在英语中,介词of后面可能跟着冠词the:”The lion is the king of the jungle.”;再比如,在包括英语的许多语言中,动词的数必须与句子主语的数一致:
The book is on the table.
The books are on the table.
有时这些依赖或约束的长度不限。例如:
The book that I got yesterday is on the table.
The books read by the second grade children are shelved in the lower rack.
简而言之,理解序列对于理解人类语言至关重要。在前几章中,你了解了前馈神经网络(如多层感知器(MLP)和卷积神经网络(CNN))以及向量表示的能力。尽管使用这些技术可以处理大量的自然语言处理(NLP)任务,但正如我们将在本章以及第七章和第八章中学习的那样,它们并不能充分地对序列建模。在NLP中使用隐马尔科夫模型、条件随机场和其他类型的概率图模型的传统方法并不是本书涉及的内容,但仍与我们所学内容相关。
在深度学习中,建模序列涉及到维护隐藏的”状态信息”或隐藏状态(hidden state)。当序列中的每个条目被匹配时——例如,当一个句子中的每个单词被模型看到时——隐藏状态就会被更新。因此,隐藏状态(通常是一个向量)封装了到目前为止序列所知的一切。这个隐藏的状态向量也称为序列表示(sequence representation),它可以以多种方式用于许多序列建模任务,这具体取决于我们正在解决的任务,包括从序列分类到预测序列。在本章中,我们将研究序列数据的分类,在第七章中,我们将介绍如何使用序列模型来生成序列。
我们首先介绍最基本的神经网络序列模型:循环神经网络(recurrent neural network,RNN)。然后,我们会在分类情境下展示RNN端到端实例。具体而言,你将看到使用基于字符的RNN给姓氏分类到其国籍的例子。姓氏示例表明序列模型可以捕获语言中的正字法(子词)模式,这个示例的研究方式使读者能够将模型应用于其他情况,包括对文本序列进行建模(其中数据项是单词而不是字符)。
6.1 循环神经网络简介
循环神经网络(recurrent neural network,RNN)的目的是建立张量序列的模型。RNN和前馈网络属于一类模型,RNN 家族中也有几个不同的成员,但在本章中,我们只讨论最基本的形式,有时称为 Elman RNN。循环网络(包括基本的 Elman 形式以及将在第七章中概述的更复杂的形式)的目标是学习序列的表示,这是通过维护一个隐藏状态向量来实现的,它捕获了序列的当前状态。隐藏状态向量由当前输入向量和前一个隐藏状态向量计算得到。这些关系如下图(6-1)所示,它展示了计算依赖项的函数视图(左)和”展开(unrolled)”视图(右)。在两个图例中,输出和隐藏向量一样,但并不总是如此,只是在Elman RNN中,这个隐藏向量是被预测的东西。
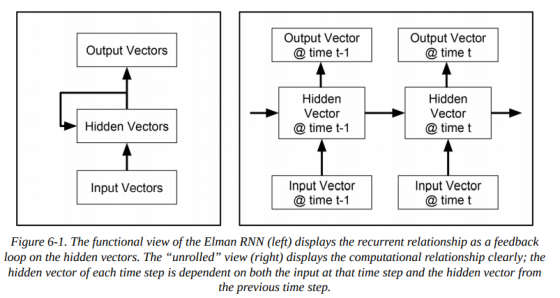

让我们看一个更具体的描述,以了解Elman RNN中发生了什么。如上图(6-1)中展开的视图所示,也称为时间反向传播(backpropagation through time,BPTT),当前时间步的输入向量和前一时间步的隐藏状态向量被映射到当前时间步的隐藏状态向量。如下图(6-2)所示,使用hidden-to-hidden权重矩阵来映射之前的隐藏状态向量,并使用input-to-hidden权重矩阵来映射输入向量,从而计算新的隐藏向量:
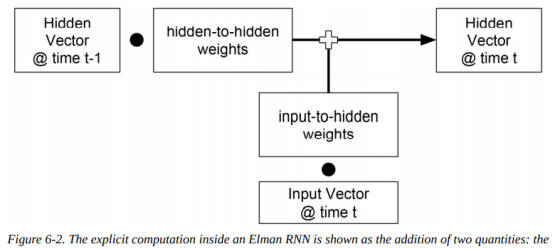

关键的是,hidden-to-hidden和input-to-hidden权重在不同的时间步中是共享的。根据这个事实,你凭直觉应该知道:在训练期间,需要对这些权重进行调整,以便RNN学习如何合并传入信息并维护一个状态表示,总结迄今为止看到的输入。RNN无法知道它处于哪个时间步,相反,它只是简单地学习如何从一个时间步过渡到另一个时间步,并维护一个状态表示,以使得其损失函数最小。
在每个时间步中使用相同的权重来将输入转换为输出是参数共享的另一个例子。在第四章中,我们看到了CNN如何跨空间共享参数。CNN使用称为核(kernel)的参数来计算来自输入数据子区域的输出。卷积核在输入端移动,从每个可能的位置计算输出,以学习平移不变性。与此相反,RNN依赖于一个隐藏的状态向量来捕获序列的状态,从而使用相同的参数来计算每一步的输出。通过这种方式,RNN的目标是通过计算给定的隐藏状态向量和输入向量的任何输出来学习序列不变性。你可以这样认为:RNN 跨时间共享参数,CNN 跨空间共享参数。
由于单词和句子的长度可变,因此RNN或任何一个序列模型都应该能处理可变长度序列(variable-length sequences)。一种可能的技术是人为地将序列限制在一个固定的长度。在本书中,我们使用另一种技术,称为masking,它通过利用序列长度的知识来处理可变长度序列。简而言之,masking允许数据在某些输入不应计入梯度或最终输出时发出信号。PyTorch 提供了处理称为PackedSequences的可变长度序列的原语(primitive),能够从这些不太密集的序列中创建密集的张量,”示例:使用字符 RNN 分类姓氏国籍”就是一个例子。
6.1.1 实现Elman RNN
为了探究RNN的细节,接下来让我们实现一个简单的Elman RNN。PyTorch 提供了许多有用的类和帮助函数来构建RNN。PyTorch RNN 类实现了Elman RNN。在本章中,我们并不直接使用 PyTorch 的RNN类,而是使用RNNCell,它是对RNN的单个时间步的抽象,并以此构建RNN,之所以这样做是因为要显式地为你展示 RNN 的构建。下例(6-1)中展示的类ElmanRNN使用了RNNCell来创建前面描述过的input-to-hidden和hidden-to-hidden权重矩阵。对RNNCell()的每次调用都接受一个输入向量矩阵和一个隐藏向量矩阵,它返回下一个步骤产生的隐藏向量矩阵。
示例 6-1:使用 PyTorch 的RNNCell实现Elman RNN
class ElmanRNN(nn.Module):
""" an Elman RNN built using the RNNCell """
def __init__(self, input_size, hidden_size, batch_first=False):
"""
Args:
input_size (int): size of the input vectors
hidden_size (int): size of the hidden state vectors
bathc_first (bool): whether the 0th dimension is batch
"""
super(ElmanRNN, self).__init__()
self.rnn_cell = nn.RNNCell(input_size, hidden_size)
self.batch_first = batch_first
self.hidden_size = hidden_size
def _initialize_hidden(self, batch_size):
return torch.zeros((batch_size, self.hidden_size))
def forward(self, x_in, initial_hidden=None):
"""The forward pass of the ElmanRNN
Args:
x_in (torch.Tensor): an input data tensor.
If self.batch_first: x_in.shape = (batch_size, seq_size, feat_size)
Else: x_in.shape = (seq_size, batch_size, feat_size)
initial_hidden (torch.Tensor): the initial hidden state for the RNN
Returns:
hiddens (torch.Tensor): The outputs of the RNN at each time step.
If self.batch_first:
hiddens.shape = (batch_size, seq_size, hidden_size)
Else: hiddens.shape = (seq_size, batch_size, hidden_size)
"""
if self.batch_first:
batch_size, seq_size, feat_size = x_in.size()
x_in = x_in.permute(1, 0, 2)
else:
seq_size, batch_size, feat_size = x_in.size()
hiddens = []
if initial_hidden is None:
initial_hidden = self._initialize_hidden(batch_size)
initial_hidden = initial_hidden.to(x_in.device)
hidden_t = initial_hidden
for t in range(seq_size):
hidden_t = self.rnn_cell(x_in[t], hidden_t)
hiddens.append(hidden_t)
hiddens = torch.stack(hiddens)
if self.batch_first:
hiddens = hiddens.permute(1, 0, 2)
return hiddens
除了控制RNN中的输入和隐藏大小超参数外,还有一个布尔参数用于指定维度是否处于零维,这个标志在所有的PyTorch RNN实现中都有出现。当它为真True的时候,RNN 交换输入张量的第0维和第1维。
在类ElmanRNN中,forward()方法循环遍历输入张量,以计算每个时间步长的隐藏状态向量。请注意,有一个用于指定初始隐藏状态的选项,但如果没有提供它,则默认使用一个全零的隐藏状态向量。当ElmanRNN循环遍历输入向量的长度时,它计算一个新的隐藏状态。这些隐藏状态被聚合并最终堆叠起来,在返回之前,将再次检查batch_first标志,如果为真,则输出隐藏向量进行排列,以便batch再次位于第零维上。
这个类的输出是一个三维张量——对于批量维度和每个时间步上的数据点都有一个隐藏状态向量。根据当前任务,有几种不同方式可以用来使用这些隐藏向量。其中一种方式是:将每个时间步分类为一些离散的选项集,该方法通过调整 RNN 权值来跟踪每一步预测的相关信息。此外,你可以使用最后一个向量来对整个序列进行分类,这意味着调整RNN权重以跟踪对最终分类重要的信息。在本章中,我们只讨论分类情境,但在接下来的两章中,我们将更深入地讨论逐步预测。
6.2 示例:使用字符 RNN 分类姓氏国籍
现在我们已经概述了RNN的基本属性,并实现了ElmanRNN,接下来让我们将它应用到任务中。我们将考虑第四章中的姓氏分类任务,将字符序列(姓氏)分类到起源的国籍。
6.2.1 SurnameDataset数据集
本例中的数据集是之前在第四章中介绍过的姓氏数据集。每个数据点由姓氏和相应的国籍表示,我们不会讨论过多细节,你可以回顾之前的章节来获取相关信息。
在本例中,就像”示例:使用 CNN 对姓氏进行分类”一节一样,我们将每个姓氏视作字符序列。和前面一样,我们会实现一个数据集类,如下例(6-2)所示,它返回向量化的姓氏和表示其国籍的整数。此外,返回的是序列的长度,它用于下游计算,以知道序列中的最终向量的位置。我们已经很熟悉正式训练开始前的流程了——实现Dataset、Vectorizer和Vocabulary。
示例 6-2:实现SurnameDataset类
class SurnameDataset(Dataset):
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dictionary holding the data point's:
features (x_data)
label (y_target)
feature length (x_length)
"""
row = self._target_df.iloc[index]
surname_vector, vec_length = \
self._vectorizer.vectorize(row.surname, self._max_seq_length)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_data': surname_vector,
'y_target': nationality_index,
'x_length': vec_length}
6.2.2 向量化数据结构
向量化管道的第一阶段是将姓氏中的每个字符token映射到一个唯一的整数,要做到这点,我们使用之前在”示例:使用预训练嵌入用于文档分类的迁移学习”一节介绍过的SequenceVocabulary数据结构。回想一下,这个数据结构不仅将推文中的单词映射到整数,而且还使用了四个特殊用途的token:UNK token、MASK token、BEGIN-SEQUENCE token和END-SEQUENCE token。前两个token对语言数据至关重要:UNK用于输入中词汇表不存在对应单词的情况,而MASK允许处理可变长度的输入。后面两个token为模型提供了句子边界特征,并分别作为前缀和后缀追加到序列中。我们建议回顾一下”示例:使用预训练嵌入用于文档分类的迁移学习”一节的内容,以获得关于SequenceVocabulary的更多信息。
整个向量化过程由SurnameVectorizer管理,它使用SequenceVocabulary来管理姓氏字符和整数之间的映射。
示例 6-3:姓氏的vectorizer
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def vectorize(self, surname, vector_length=-1):
"""
Args:
title (str): the string of characters
vector_length (int): an argument for forcing the length of index vector
"""
indices = [self.char_vocab.begin_seq_index]
indices.extend(self.char_vocab.lookup_token(token)
for token in surname)
indices.append(self.char_vocab.end_seq_index)
if vector_length < 0:
vector_length = len(indices)
out_vector = np.zeros(vector_length, dtype=np.int64)
out_vector[:len(indices)] = indices
out_vector[len(indices):] = self.char_vocab.mask_index
return out_vector, len(indices)
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
char_vocab = SequenceVocabulary()
nationality_vocab = Vocabulary()
for index, row in surname_df.iterrows():
for char in row.surname:
char_vocab.add_token(char)
nationality_vocab.add_token(row.nationality)
return cls(char_vocab, nationality_vocab)
6.2.3 SurnameClassifier模型
SurnameClassifier模型由嵌入层、ElmanRNN和Linear层组成。我们假设模型的输入是在它们被SequenceVocabulary映射到整数之后作为一组整数来表示的token。模型首先使用嵌入层嵌入整数,然后利用 RNN 计算序列表示向量,这些向量表示姓氏中每个字符的隐藏状态。由于我们的目标是对每个姓氏进行分类,因此提取每个姓氏中最终字符位置对应的向量会被提取出来。可以这样理解:最终的向量是传递整个序列输入的结果,因此它是姓氏的汇总向量。这些汇总向量通过Linear层计算预测向量。预测向量被用于训练损失,或者我们可以使用softmax函数创建姓氏的概率分布。
模型的参数是:嵌入的大小、嵌入的数量、类的数量以及RNN的隐藏状态大小。其中两个参数——嵌入的数量和类的数量——是由数据决定的。剩下的超参数是嵌入的大小和隐藏状态的大小。我们通常最好从一些小的、可以快速训练以验证模型是否有效的东西开始:
示例 6-4:使用Elman RNN实现SurnameClassifier模型
class SurnameClassifier(nn.Module):
""" An RNN to extract features & a MLP to classify """
def __init__(self, embedding_size, num_embeddings, num_classes,
rnn_hidden_size, batch_first=True, padding_idx=0):
"""
Args:
embedding_size (int): The size of the character embeddings
num_embeddings (int): The number of characters to embed
num_classes (int): The size of the prediction vector
Note: the number of nationalities
rnn_hidden_size (int): The size of the RNN's hidden state
batch_first (bool): Informs whether the input tensors will
have batch or the sequence on the 0th dimension
padding_idx (int): The index for the tensor padding;
see torch.nn.Embedding
"""
super(SurnameClassifier, self).__init__()
self.emb = nn.Embedding(num_embeddings=num_embeddings,
embedding_dim=embedding_size,
padding_idx=padding_idx)
self.rnn = ElmanRNN(input_size=embedding_size,
hidden_size=rnn_hidden_size,
batch_first=batch_first)
self.fc1 = nn.Linear(in_features=rnn_hidden_size,
out_features=rnn_hidden_size)
self.fc2 = nn.Linear(in_features=rnn_hidden_size,
out_features=num_classes)
def forward(self, x_in, x_lengths=None, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
x_lengths (torch.Tensor): the lengths of each sequence in the batch.
They are used to find the final vector of each sequence
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
out (torch.Tensor); out.shape = (batch, num_classes)
"""
x_embedded = self.emb(x_in)
y_out = self.rnn(x_embedded)
if x_lengths is not None:
y_out = column_gather(y_out, x_lengths)
else:
y_out = y_out[:, -1, :]
y_out = F.dropout(y_out, 0.5)
y_out = F.relu(self.fc1(y_out))
y_out = F.dropout(y_out, 0.5)
y_out = self.fc2(y_out)
if apply_softmax:
y_out = F.softmax(y_out, dim=1)
return y_out
你会注意到forward()函数需要序列的长度,这些长度用于检索张量中每个序列的最终向量,该向量由RNN返回,函数名为column_gather(),如下例(6-5)所示。该函数迭代batch行索引,并检索位于序列相应长度所指示位置的向量。
示例 6-5:使用column_gather()在每个序列中获取最终向量
def column_gather(y_out, x_lengths):
'''Get a specific vector from each batch datapoint in y_out.
Args:
y_out (torch.FloatTensor, torch.cuda.FloatTensor)
shape: (batch, sequence, feature)
x_lengths (torch.LongTensor, torch.cuda.LongTensor)
shape: (batch,)
Returns:
y_out (torch.FloatTensor, torch.cuda.FloatTensor)
shape: (batch, feature)
'''
x_lengths = x_lengths.long().detach().cpu().numpy() - 1
out = []
for batch_index, column_index in enumerate(x_lengths):
out.append(y_out[batch_index, column_index])
return torch.stack(out)
6.2.4 训练例程和结果
训练程序遵循标准公式:对于单批数据,应用模型并计算预测向量;利用CrossEntropyLoss()和真值来计算损失值;使用损失值和优化器来计算梯度并使用这些梯度更新模型的权重;对训练数据中的每批重复此操作;对验证数据进行类似的处理,但要将模型设置为eval模式,以防止在验证数据上进行反向传播。验证数据仅用于对模型的执行情况给出一个不太偏颇的感觉。在指定数量的周期内重复此例程。代码请参见补充资料。我们鼓励你使用超参数了解它们对性能的影响以及影响程度,最好能制表以对比结果。我们还会为该任务编写合适的基线模型,不过是留作练习。在”SurnameClassifier模型”一节中实现的模型是通用的,并不局限于字符。模型中的嵌入层可以映射离散项序列中的任意离散项,例如,一个句子是一系列单词。我们鼓励你在其他序列分类任务(如句子分类)中使用下例(6-6)中的代码:
示例 6-6:基于 RNN 的SurnameClassifier的参数
args = Namespace(
# Data and path information
surname_csv="data/surnames/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch6/surname_classification",
# Model hyper parameter
char_embedding_size=100,
rnn_hidden_size=64,
# Training hyper parameter
num_epochs=100,
learning_rate=1e-3,
batch_size=64,
seed=1337,
early_stopping_criteria=5,
# ... Runtime options not shown for space
)
6.3 总结
在本章中,我们介绍了对于序列建模的RNN的使用,并完成了最简单的一种循环网络,即 Elman RNN。我们知道了序列建模的目标是学习序列的表示(即向量)。根据任务的不同,可以以不同的方式使用这种学习过的表示。我们思考了一个示例任务,它涉及到将这种隐藏状态表示分类为许多类中的一个。姓氏分类任务展示了一个使用RNN在子词级别捕获信息的示例。

Original: https://blog.csdn.net/qq_43045873/article/details/121200073
Author: 数据与智能
Title: 「PyTorch自然语言处理系列」6. 自然语言处理的序列模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545018/
转载文章受原作者版权保护。转载请注明原作者出处!