

使用未标记辅助语言的跨语言依存句法分析
- 摘要
- 1简介
* - 2 Training Language-agnostic Encoders(训练与语言无关的编码器)
- 2.1 结构
- 2.2 训练
– - 3 Experiments and Analysis
* - 3.1 结果与分析
– - 4 Related Work
- 5 结论
摘要
跨语言迁移学习已成为对抗低资源语言注释资源不可用的重要武器。 跨语言迁移的基本技术之一是 以词嵌入或上下文编码的形式学习与语言无关的表示。在这项工作中,我们建议 利用来自辅助语言的未注释句子来帮助学习与语言无关的表示。具体来说,我们探索了用于学习上下文编码器的对抗性训练,这些编码器产生跨语言的不变表示,以促进跨语言迁移。
我们对跨语言依赖解析进行了实验,我们在源语言上训练依赖解析器并将其转换为广泛的目标语言。对 28 种目标语言的实验表明, 对抗训练在几种不同的设置下显着提高了整体迁移性能。我们进行了仔细的分析,以评估对抗性训练产生的与语言无关的表征。
1简介
跨语言迁移,即从一种语言学习的模式被迁移到另一种语言,已成为提高世界语言自然语言处理 (NLP) 工具质量和覆盖率的重要技术。该技术已广泛应用于许多应用中,包括词性 (POS) 标记 (Kim et al., 2017)、依赖解析 (Ma and Xia, 2014)、命名实体识别 (Xie et al., 2018) 、实体链接(Sil 等人,2018 年)、共指解析(Kundu 等人,2018 年)和问答(Joty 等人,2017 年)。 由于跨语言迁移学习,低资源语言应用程序取得了显着的改进。
在本文中,我们研究了依赖解析的跨语言迁移。依赖解析器包括 (1) 将输入文本序列转换为潜在表示的编码器(这里没读懂!!)和 (2) 生成相应解析树的解码算法。 在跨语言迁移中,最近的方法假设来自不同语言的输入通过多语言词嵌入或多语言上下文化词向量对齐到相同的嵌入空间,这样在源语言上训练的解析器可以迁移到目标语言。然而,在源语言上训练解析器时,编码器不仅学习嵌入句子,而且还带有语言特定的属性,例如词序类型学。因此,当解析器被转移到具有不同语言属性的语言时,解析器会受到影响。受此启发,我们研究 如何训练编码器以生成可以跨多种语言传输的与语言无关的表示。
什么叫多语言上下文化词向量
2、
Dependency Parser参考这两篇文章
(看完大概了解了一些)
1、 Dependency Parser研究进展及主流方法
2、自然语言处理:依存句法解析(Dependency Parsing)
3、 句法分析:依存分析(Dependency Parsing)
我们建议利用一种或多种辅助语言的未标记句子来训练编码器,该编码器学习与语言无关的句子上下文表示,以促进跨语言迁移。为了利用未标记的辅助语言语料库,我们采 用了编码器的对抗训练(Goodfellow et al., 2014)和一个分类器, 该分类器从编码器产生的编码表示中预测输入句子的语言身份。对抗训练鼓励编码器产生语言不变的表示,使得语言分类器无法预测正确的语言身份。(对抗训练使得编码器将不同语言编码成差别不大的向量,让分类器预测不出来)由于 编码器是在源语言和所有语言的对抗损失联合训练的损失,我们假设它将学习捕获特定于任务的特征以及适用于许多语言的通用结构模式,因此有更好的可转移性。
为了验证所提出的方法,我们在英语(源语言)上训练的神经依赖解析器上进行了实验,并在有或没有来自辅助语言的未标记数据的帮助下,将它们直接转移到28种目标语言。我们选择依赖解析作为主要任务,因为它是NLP的核心应用之一,而通用依赖的开发(Nivre等人,2016)提供了跨语言的一致注释,使我们能够在广泛的语言中研究迁移学习。为了解决以下研究问题,进行了彻底的实验和分析:
- 用对抗训练训练的编码器是否会生成与语言无关的表示? (就是只要是一个意思就嵌入到相同位置)
- 与语言无关的表示是否改进了跨语言迁移?
实验结果表明,该方法始终优于强基线解析器(Ahmad et al.,2019),在两种语言中具有显著的优势。此外,我们还进行实验,用不同类型的输入表示和编码器来巩固我们的发现。我们的实验代码是公开的,以促进未来的研究。
2 Training Language-agnostic Encoders(训练与语言无关的编码器)
我们以对抗的方式训练依赖关系解析器的编码器,以避免捕获特定于语言的信息(就是防止只学习一种或几种语言的特征信息)。特别是,我们介绍了一个语言识别任务,其中 分类器根据输入句子的编码表示预测其语言标识(这里指的应该就是什么语言)(id)。 然后对编码器进行训练,使分类器无法预测语言id, 而解析器-解码器则根据编码的表示准确预测解析树(就是语言结构)。我们假设这样的编码器会有更好的跨语言传输能力(我这里解释成学习到的是语言含义的表示,而不单单是某种语言结构的表面字符含义)。我们模型的整体架构如图1所示。下面,我们将详细介绍模型和培训方法。
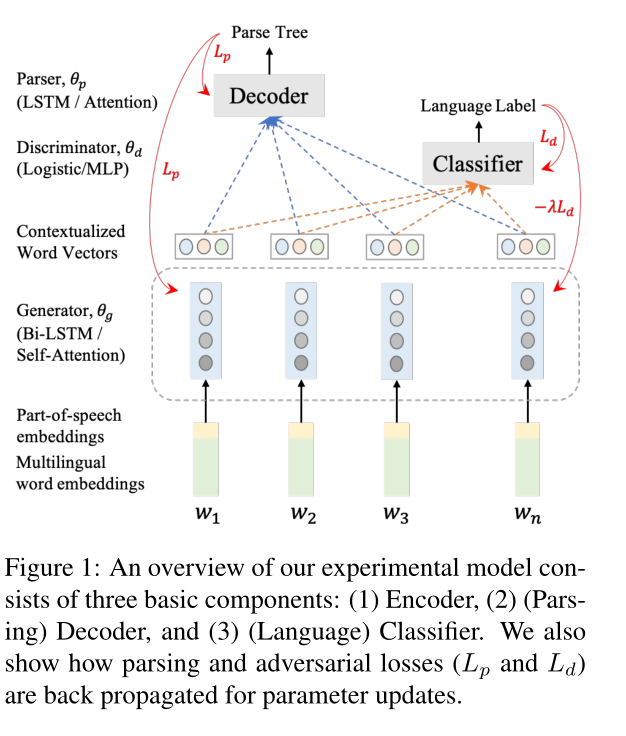

(还没看懂啥意思)
图1:我们的实验模型由三个基本组件组成:(1)编码器,(2)(解析)解码器和(3)(语言)分类器。我们还展示了解析和对抗性损失(Lp和Ld)是如何在参数更新时反向传播的。
最下面是词性嵌入和多语言单词嵌入。在往上是生成器,再往上是多语言上下文化单词向量,再往上是鉴别器和解析器。
; 2.1 结构
我们的模型由三个基本组件组成,(1)通用编码器,(2)用于解析的解码器,(3)用于语言识别的分类器。
编码器学习为输入句子(一个单词序列)生成语境化表示(感觉就是不单单是单词的向量表示,而是这个单词在这个语境中的表示,大概可以解释为一个单词可能有n多个意思,但是这个单词在这句话里面表示这个意思),并将其输入解码器和分类器,以预测该句子的依赖结构(dependency parsers)和语言标识(id)。
编码器和解码器共同形成解析模型,我们考虑了来自 (Ahmad et al., 2019) 的两个备选方案:”SelfAtt-Graph”和”RNN-Stack”。 “SelfAtt-Graph”解析器由修改后的自注意编码器(Shaw et al., 2018)和基于图的深度双仿射解码器(Dozat and Manning, 2017)组成(这个还没看这俩是是啥),而”RNN-Stack”解析器是由基于循环神经网络 (RNN) 的编码器和堆栈指针解码器组成 (Ma et al., 2018)。(图中的倒数第二行)
我们在编码器顶部堆叠一个分类器(线性分类器或多层感知器(MLP(就是最简单的神经网络)))来执行语言识别任务。识别任务可以被定义为单词或句子级别的分类任务。对于句子级分类,我们对编码器生成的上下文词表示应用平均池化,以形成输入序列的固定长度表示,然后将其馈送给分类器。对于词级分类,我们分别对每个标记执行语言分类。

更新encoder的参数(生成器)
更新decoder的参数
更新完上面的两个参数以后,从源语言和未标记的辅助语言更新参数以后,然后更新分类器(鉴别器)的参数 (这里从源语言和辅助语言更新的参数用在哪里了??不知道)
计算损失,更新编码器和解码器(用来生成parse tree的)(parse tree的意义在哪里)的参数
在这项工作中,按照对抗性学习文献中的术语,我们可以互换地将编码器称为生成器 G,将分类器称为鉴别器 D。
2.2 训练
算法 1 描述了训练过程。我们有 两种类型的损失函数:用于解析任务的 Lp 和用于语言识别任务的 Ld。 对于前者,我们像在解析器的常规训练中一样更新编码器和解码器。对于后者,我们采用对抗训练来更新编码器和分类器。我们将在下面介绍详细的培训计划。
2.2.1 Parsing
为了训练解析器,我们对这两种类型的解析器采用了交叉熵目标,如 (Dozat and Manning, 2017; Ma et al., 2018)。编码器和解码器联合训练以优化给定句子 (x) 的依赖树 (y) 的概率:
L p = − log p ( y ∣ x ) {L_p} = – \log p(y|x)L p =−lo g p (y ∣x )
树的概率可以进一步分解成用于基于图的解析器的每个token(M)的个头判决(h(M))的概率的乘积,或者用于基于转换的解析器的每个转变步骤判决的概率(Ti)的乘积:(这一段其实没太懂耶)
每个token(M)的头部输出(h(M))对于图的解析
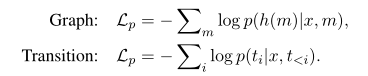
; 2.2.2 Language Identification
我们的目标是在依赖解析模型中训练上下文编码器,使其尽可能少地编码语言特定的特征,这可能有助于跨语言传输。 为了实现我们的目标,我们通过使用未标记的辅助语言语料库来利用对抗性训练。
设置 :我们采用基本的生成对抗网络(GAN)进行对抗训练。我们假设 X a 和 X b 分别是源语言句子和辅助语言句子的语料库。判别器充当二元分类器,用于区分源语言和辅助语言。(意思就是我输入两种语言,然后编码,传给判别器让判别器来鉴定,要让判别器鉴定不出来两种语言编码以后的差距并且parse tree的表达还要准确)对于判别器的训练,根据原始分类损失更新权重:
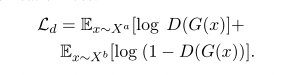
对于依赖解析的训练,生成器 G 与解析器协作,但相对于判别器充当对手。因此,通过最小化损失函数来更新生成器权重(θg),
L = L p − λ L d L = {L_p} – \lambda {L_d}L =L p −λL d
其中λ用于缩放鉴别器损失(Ld)。通过这种方式,生成器被引导构建与语言无关的表示,以便在有助于解析任务的同时欺骗鉴别器。同时,可以引导解析器更多地依赖与语言无关的特性。
Alternatives(替代性选择) : 我们还考虑了对抗性训练的两种替代技术:梯度反转 (GR) (Ganin et al., 2016) 和 Wasserstein GAN (WGAN) (Arjovsky et al., 2017)。与基于 GAN 的训练相反,在 GR 设置中,判别器充当预测输入句子语言身份的多类分类器,我们使用多类交叉熵损失。我们还研究了 Arjovsky 等人提出的 Wasserstein GAN (WGAN)。 (2017)提高基于GAN的学习的稳定性。其损失函数如下所示。
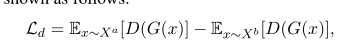
这里的注释与GAN设置中的注释类似
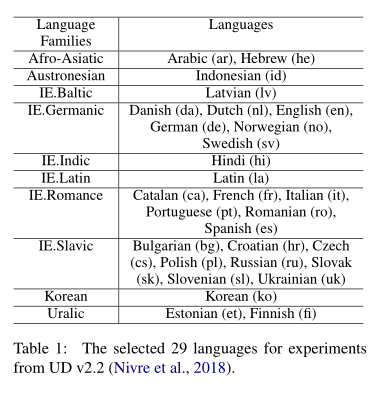
3 Experiments and Analysis
在这一部分中,我们从不同的角度讨论了我们对跨语言依赖句法分析迁移的实验和分析,并展示了对抗性训练的优势。
Settings. 在我们的实验中,我们研究了 SingleSource句法迁移,其中一个句法分析模型在一种源语言上训练,并直接应用于目标语言。如表1所示,我们使用29种语言对通用依赖(UD)Treebank(v2.2)(Nivre等人,2018年)进行了实验。我们使用”SelfAtt-Graph”和”RNN-Stack”解析器的公开实现4。(2019)显示,对于遥远的目标语言,”SelfAtt-Graph”解析器捕获的特定语言信息较少,并且性能优于”RNN-Stack”解析器。因此,我们 在大多数实验中使用”SelfAttGraph”解析器。
此外, Bert(MBERT)的多语言变体(Devlin等人,2019)在跨语言任务中表现良好(Wu和Dredze,2019),并且远远超过在多语言单词嵌入方面训练的模型。因此,我们考虑同时进行多语种单词嵌入和mBERT的实验。我们使用对齐的多语言词嵌入(Smith 等人,2017 年;Bojanowski 等人,2017 年)具有 300 个维度或多语言 BERT6(Devlin 等人,2019 年)提供的具有 768 个维度的上下文化词表示作为词表示。
此外,我们 使用 Gold 通用 POS 标签来形成输入表示。我们在训练期间冻结单词表示,以避免破坏多语言表示对齐的风险。
具体参数设置
我们选择六种辅助语言8(法语、葡萄牙语、西班牙语、俄语、德语和拉丁语)通过对抗训练进行无监督的语言适应。我们在源语言验证集的 [0.1, 0.01, 0.001] 范围内调整缩放参数λ,并以最佳值报告测试性能。对于梯度反转(GR)和基于 GAN 的对抗性目标,我们使用 Adam(Kingma 和 Ba,2015)来优化判别器参数,对于 WGAN,我们使用 RMSProp(Tieleman 和 Hinton,2012)。 Adam 和 RMSProp 的学习率分别设置为 0.001 和 0.00005。我们分别使用多语言 BERT 和多语言词嵌入训练了 400 和 500 个 epoch 的解析模型。我们在 [50, 100, 150] 的范围内调整参数 I(如算法 1 所示)。
Language Test
使用来自辅助语言的未标记数据对抗性地训练上下文编码器的目标是 鼓励编码器捕获更多与语言无关的表示和更少与语言相关的特征。为了测试上下文编码器在对抗训练后是否保留语言信息,我们在固定的上下文编码器之上训练了一个带有 softmax 的多层感知器 (MLP) 来执行 7 路 分类任务。9 如果上下文编码器在语言中表现更好测试,它表明编码器保留了语言特定的信息。
3.1 结果与分析
表 2 显示了”SelfAtt-Graph”解析器在仅使用英语(en,baseline)、英语与法语(enfr)和英语与俄语(en-ru)进行训练时的主要迁移结果。结果表明, 带有辅助语言识别任务的对抗性训练有利于跨语言迁移,而源语言的性能下降很小。 当采用多语言嵌入时,性能显着提高,分别使用法语和俄语作为辅助语言时,29 种语言的 UAS 分别为 0.48 和 0.61。当采用更丰富的多语言表示技术(如 mBERT)时,对抗性训练仍然可以提高跨语言迁移性能(分别使用法语和俄语,在 29 种语言上分别提高 0.21 和 0.54 UAS)。
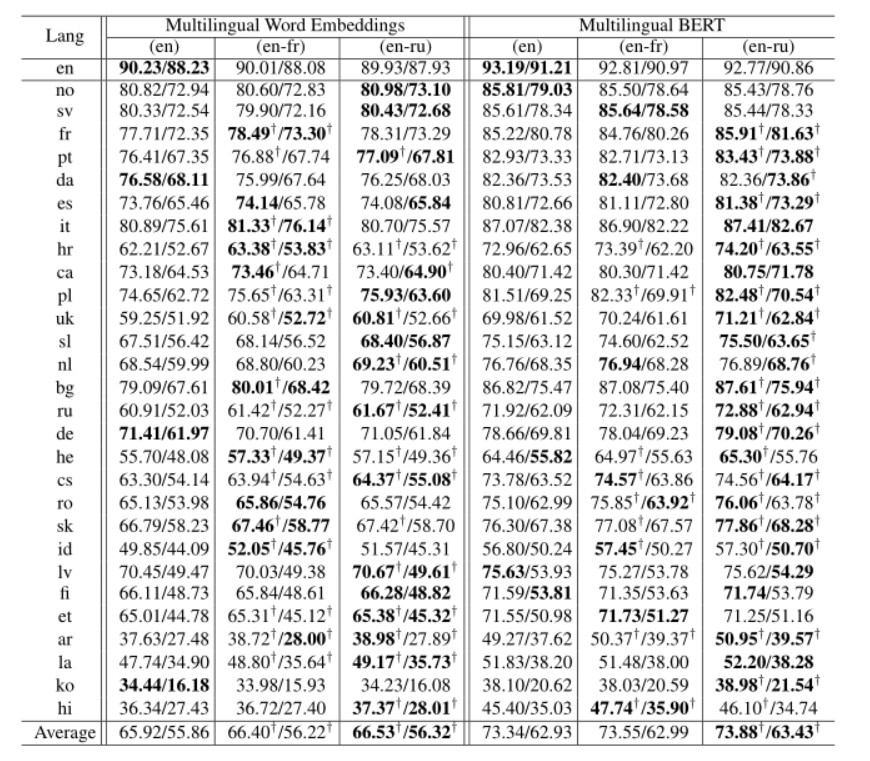
表 2:SelfAtt-Graph 解析器 (Ahmad et al., 2019) 在测试集上的跨语言迁移性能(UAS%/LAS%,不包括标点符号)。在第 1 列中,语言按与英语的词序距离排序。 (en-fr) 和 (en-ru) 表示源-辅助语言对。’†’ 表示对抗性训练的模型结果在统计上显着优于仅在源上训练的模型(通过排列检验,p < 0.05)语言(英文)。结果表明,使用未标记的辅助语言语料库显着提高了跨语言迁移性能。
接下来,我们在”RNN-Stack”解析器上应用对抗性训练,并在表 3 中显示结果。与”SelfAtt-Graph”解析器类似,”RNN-Stack”解析器在 unsu 的跨语言迁移方面取得了显着改进- 有监督的语言适应。我们将在下面讨论我们的详细实验分析。
; 3.1.1 对抗训练的影响
为了了解不同对抗训练类型和目标的影响,我们将对抗训练应用于单词和句子级别的梯度反转 (GR)、GAN 和 WGAN 目标。我们在表 4 中提供了不同对抗训练设置的平均跨语言迁移性能。在对抗性训练目标中,我们观察到在大多数情况下,GAN 目标的性能优于 GR 和 WGAN 目标。我们的发现与 Adel 等人的相反。 (2018 年)据报道,遗传资源是更好的目标。
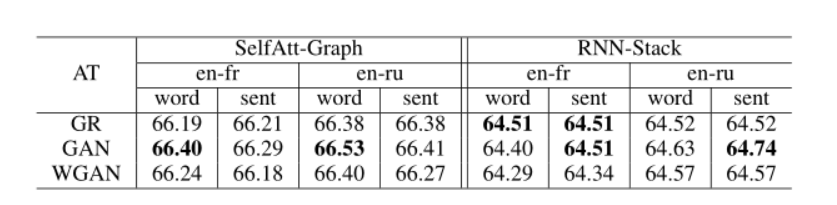
表 4:使用不同对抗训练目标和设置的测试集上的平均跨语言迁移性能(UAS%,不包括标点符号)。这些实验使用多语言词嵌入。
为了进一步调查,我们对通过这两个目标训练的编码器进行语言测试。我们发现基于 GR 的训练编码器在语言识别任务上的表现始终优于基于 GAN 的编码器,这表明通过基于 GAN 的训练,编码器变得更加与语言无关。在 GAN 和 WGAN 之间的比较中,我们注意到基于 GAN 的训练始终表现更好。
比较单词和句子级别的对抗训练,我们观察到在单词级别预测语言身份对于”SelfAtt-Graph”模型稍微有用一些,而句子级别的对抗训练导致”RNN-堆栈”模型。没有明确的优势战略。
此外,我们研究了使用线性分类器或多层感知器(MLP)作为判别器的效果,发现编码器和线性分类器之间的交互导致了改进。
3.1.2 Adversarial v.s. Multi-task Training(对抗性与对抗性多任务训练)
在第 3.1.1 节中,我们研究了通过使用辅助语言和对抗性训练来学习与语言无关的表示的效果。
利用辅助语言语料库的另一种方法是 通过多任务学习在表示中编码特定于语言的信息。在多任务学习 (MTL)(后续再去看看多任务学习,MTL) 设置中,模型观察到与对抗训练 (AT) 模型相同数量的数据(标记和未标记)。 MTL 和 AT 模型之间的唯一区别是,在 MTL 模型中,鼓励上下文编码器捕获与语言相关的特征,而在 AT 模型中,它们被训练来编码与语言无关的特征。
使用 多任务学习与对抗性训练进行比较的实验结果如表 5 所示。有趣的是,尽管 MTL 目标听起来与对抗性学习相矛盾,但它 对跨语言解析有积极影响,因为表示是通过一定的额外学习来学习的来自新(未标记)数据的信息。使用 MTL,我们有时会观察到基线解析器的改进,如†符号所示,而 AT 模型的性能始终优于基线和 MTL 模型(如表 5 中的第 2-5 列所示)。 解析性能的比较并没有揭示上下文编码器是否学会了编码与语言无关的特征或相关特征。
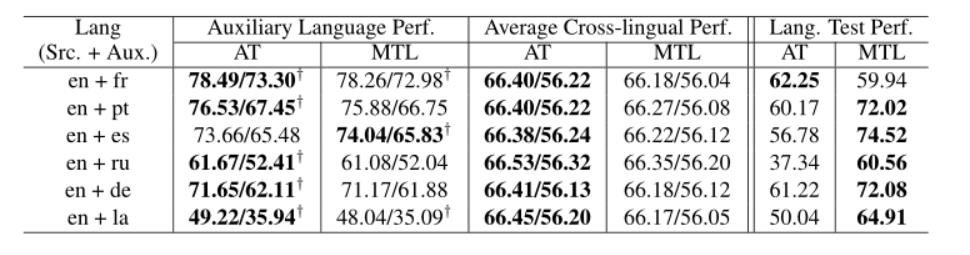
表 5:上下文编码器的对抗训练 (AT) 和多任务学习 (MTL) 之间的比较。第 2-5 列展示了辅助语言的解析性能(UAS%/LAS%,不包括标点符号)和 29 种语言的平均值。第 6-7 列显示语言标签预测测试的准确度 (%)。 “†”表示性能高于基线性能(如表 2 的第 2 列所示)。
因此,我们使用 MTL 和 AT(基于 GAN)编码器进行语言测试,结果如表 5 第 6-7 列所示。结果表明,MTL 编码器的性能始终优于 AT 编码器,这验证了我们的假设,即对抗性训练激励上下文编码器编码与语言无关的特征。
; 3.1.3 Impact of Auxiliary Languages(辅助语言的影响)
为了通过对抗性训练分析辅助语言在跨语言迁移中的影响,我们通过将源语言(英语)与六种不同的语言(跨越日耳曼语、罗曼语、斯拉夫语和拉丁语系)配对来进行实验。辅助语言。表 6 显示了平均跨语言迁移性能,结果表明俄语 (ru) 和德语 (de) 是辅助语言的更好候选者。
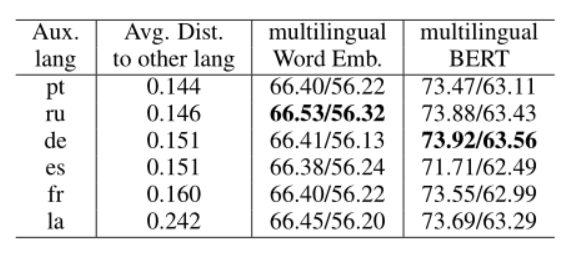
表 6:当不同语言在对抗训练中充当辅助语言时,使用 SelfAtt-Graph 解析器在测试集上的平均跨语言迁移性能(UAS%/LAS%,无标点符号)。
然后,我们更深入地研究辅助语言的影响,试图了解辅助语言是否特别有利于与它们更接近或来自同一家族的目标语言。直观地说,我们会 假设当辅助语言与所有目标语言的平均距离较小时,跨语言迁移性能会更好。然而,从表 6 中的结果来看,我们 没有看到这样的模式。例如,在我们测试的辅助语言中,葡萄牙语(pt)与其他语言的平均距离最小,但它不是更好的辅助语言之一。
我们进一步放大了每个语言家族的跨语言迁移改进,如表 7 所示。我们 假设辅助语言对同一家族中的目标语言更有帮助。实验结果与我们的预期适度相关。具体来说,日耳曼家庭从使用德语(de)作为辅助语言中受益最大;类似的斯拉夫语系以俄语(ru)作为辅助语言(虽然德语作为辅助语言带来了类似的改进)。 Romance 家族是一个例外,因为它从使用法语(fr)作为辅助语言中受益最少。这可能是由于法语对英语过于封闭,因此不太适合用作辅助语言。
4 Related Work
Unsupervised Cross-lingual Parsing.(无监督跨语言解析) : 在过去的几年中研究了依赖解析的无监督跨语言迁移,这里,”无监督迁移”是指将仅在源语言上训练的解析模型直接迁移到目标语言的设置。在这项工作中,我们放宽了设置,允许来自源语言以外的一种或多种辅助(辅助)语言的未标记数据。这一背景在以前的一些著作中已经被探索过了。Cohen等人的研究成果。(2011)学习使用未注释的目标数据作为源语言语法分析器的线性内插的生成性目标语言语法分析器。Täackström等人。(2013)采用未标记的目标语言数据和一种可以通过歧义标记结合多种知识来源的学习方法进行迁移句法分析。相比之下,我们利用未标记的辅助语言数据来学习与语言无关的语境表征,以促进跨语言迁移。
Multilingual Representation Learning.(多语种表征学习) : 无监督跨语言句法分析的基础是我们可以将不同语言的表示对齐到同一个空间中,至少在单词层面上是这样。双语或多语种单词嵌入的最新发展为我们提供了这样的共享表示。
我们请读者参考Ruder等人的调查。(2017)和Glavaˇs等人。(2019)详见。其主要思想是,我们可以在源语言嵌入的基础上训练一个模型,该模型与目标语言嵌入对齐到同一空间,因此所有的模型参数都可以直接在不同语言之间共享。
在转移到目标语言期间,我们只需将源语言嵌入替换为目标语言嵌入。这一想法进一步扩展到学习多语言上下文化词表示,例如,多语言 BERT(Devlin 等人,2019 年)已被证明对许多跨语言迁移任务非常有效(Wu 和 Dredze,2019 年)。在这项工作中,我们表明,即使编码器是在多语言 BERT 之上训练的,也可以通过未标记的辅助语言调整上下文编码器来实现进一步的改进。
Adversarial Training.(对抗训练) : 通过生成对抗网络 (GAN) 进行对抗训练的概念(Goodfellow et al., 2014; Szegedy et al., 2014; Goodfellow et al., 2015)最初被引入用于图像分类的计算机视觉中,并在改进模型方面取得了巨大成功具有扰动的输入图像的鲁棒性。后来提出了 GAN 的许多变体(Arjovsky 等人,2017;Gulrajani 等人,2017)以提高其训练稳定性。在 NLP 中,对抗性训练首先用于域适应(Ganin et al., 2016)。从那时起,对抗性训练开始在 NLP 社区中受到越来越多的关注,并应用于许多 NLP 应用程序,包括词性 (POS) 标记 (Gui et al., 2017; Yasunaga et al., 2018)、依赖解析 ( Sato et al., 2017)、关系提取 (Wu et al., 2017)、文本分类 (Miyato et al., 2017; Liu et al., 2017; Chen and Cardie, 2018)、对话生成 (Li et al., 2018) , 2017)。
在跨语言 NLP 任务的背景下,最近的许多工作都采用了对抗性训练,例如序列标记 (Adel et al., 2018)、文本分类 (Xu and Yang, 2017; Chen et al., 2018)、词嵌入归纳 (Zhang et al., 2017; Lample et al., 2018)、关系分类 (Zou et al., 2018)、意见挖掘 (Wang and Pan, 2018) 和问题-问题相似度重新排序 (Joty et al., 2017)。然而,现有的方法只考虑使用目标语言作为辅助语言。目前尚不清楚通过先前提出的方法学习的语言不变表示是否可以在各种看不见的语言上表现良好。据我们所知,我们是第一个研究语言不可知表示对广泛语言的影响的人。
5 结论
在本文中,我们研究了用于跨语言迁移的学习语言不变上下文编码器。具体来说,我们利用来自辅助语言和对抗训练的未标记句子来诱导与语言无关的编码器,以提高跨语言依赖解析的性能。使用英语作为源语言和六种外语作为辅助语言的实验和分析不仅显示了跨语言依赖解析的改进,而且还证明了上下文编码器通过对抗训练成功地学会了不捕获语言依赖的特征。未来,我们计划研究对抗性训练对多源迁移到解析和其他跨语言 NLP 应用程序的有效性。
Original: https://blog.csdn.net/missgrass/article/details/124045309
Author: 帅帅梁
Title: 论文笔记:Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544868/
转载文章受原作者版权保护。转载请注明原作者出处!