

导读:本文是”数据拾光者”专栏的第四十四篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇从理论到实践介绍了Facebook开源的FastText模型,对于想了解FastText模型并且应用到线上文本分类任务中的小伙伴可能有所帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者


摘要:本篇从理论到实践介绍了Facebook开源的FastText模型。首先介绍了背景,由于工作需要对当前语音助手红线模型进行优化,而当前模型使用的是FastText模型;然后从理论方面重点介绍了FastText模型,主要用于词向量训练和文本分类任务中,因为速度快和不错的效果所以广泛应用在工业界。FastText模型结构简单,将词向量和n-gram特征作为模型输入,进行求和取平均即可得到语义向量特征,最后接一个softmax进行分类;最后从源码实践的角度介绍了FastText文本分类流程。对于想了解FastText模型并且应用到线上文本分类任务中的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:

01
背景介绍
还是按照老规矩介绍下背景,因为最近接手了语音助手红线项目,需要对用户违法涉政的服务请求进行过滤,从任务类型来看就是文本分类任务,目前线上模型主要使用的是FastText模型,所以需要详细了解下。当前语音助手红线模型具体方案如下图所示:

图1 语音助手红线模型具体方案
如上图所示,用户请求会首先通过关键词匹配服务,根据不同的词表进行不同的处理。如果匹配到白名单词表,则直接通过请求;如果匹配到红线词表则直接进行拦截,这里红线词表主要是违法和涉政相关的;如果匹配到违法和涉政召回关键词,则会进入RedModel模型;其他用户请求还会同时进入RecallModel和GlobalModel两个模型,两者都是基于FastText模型构建的。RecallModel是一个分类任务,主要有违法、涉政和其他三类,主要用于召回红线数据。而GlobalModel则主要是识别一些辱骂、低俗等类别数据。如果RecallModel模型识别为违法和涉政的,则会和匹配到违法和涉政召回关键词的请求一起进入RedModel模型,这里两者是或的关系。RedModel是基于RoBerta模型构建的在线分类服务,当RedModel识别为红线数据则进行拦截,否则输出GlobalModel模型的分类结果并进行相应处理。这里RecallModel和GlobalModel使用FastText一个主要原因是用户请求量级超大,线上满足实时性要求,并且兼顾一定的模型效果。而RedModel使用RoBERTa模型主要原因是经过RecallModel之后量级已经很少了,需要更好的模型效果。本篇重点介绍FastText模型。
02
详解FastText
2.1 为什么要学习FastText
FastText是Facebook公司2016年开源的项目, 主要用于构建词向量和文本分类。 FastText最大的优点是又快又好,因为本身结构非常简单,只有一层浅层网络,所以模型训练和线上预测的速度非常快,在普通的CPU上也能达到分钟级别的训练速度。不仅如此,在很多分类任务的标准数据集上模型效果也很不错。正因为速度非常快,并且模型效果还不错,所以在工业界应用范围很广。
2.2 FastText两个功能
FastText主要用于训练词向量和文本分类任务,下面会分别进行详细说明。
2.2.1 训练词向量
FastText一个主要功能是训练词向量,这和word2vec非常相似,有趣的是FastText的主要作者之一就是word2vec的作者,所以说它俩是一脉相承。相比于word2vec来说, FastText主要添加了subwords特性。这里详细介绍下subwords特性, subwords是字母粒度的n-gram。以英文举例,I love NLP。英文会根据空格进行分词,这里会切分成i、love和NLP三个词,词粒度的n-gram(这里假如n为2)则会得到i-love和love-NLP,对于单词love来说字母粒度的n-gram则可以得到l-o、o-v、v-e。 字母粒度的n-gram特征可以很好的丰富词表示的层次,对于一些未知词可以根据字母粒度的n-gram特征进行更好的表示。
2.2.2 文本分类
FastText还可以用于文本分类任务,模型结构和word2vec的CBOW非常相似:
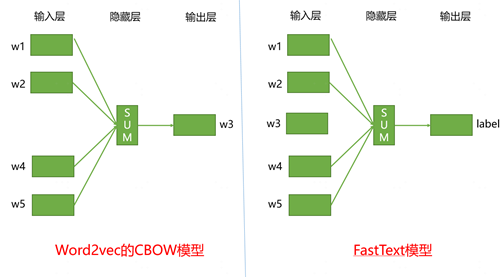
图2 FastText和Word2ve的CBOW模型结构图
从上图可以看出,FastText和word2vec的CBOW模型结构基本上是一样的,区别在于word2vec的CBOW模型是根据w3周围的w1、w2、w4和w5来预测w3,属于无监督学习模型,而FastText则根据整句的词w1-w5来预测标签,属于有监督学习任务。 FastText将得到的词向量和其他特征相加后取均值作为句向量特征,然后接softmax层进行分类预测。
如果只是将词向量特征相加后取均值作为句向量特征,则和其他词袋模型没啥区别,很难识别以下情况,比如两句话Wilson love Taylor和Taylor love Wilson通过词向量特征相加后取均值得到的句向量是完全一样的,但是语义可能完全不同。这时候需要加入语序特征的信息。 FastText模型不仅会加入词向量特征,还会加入n-gram特征,下图是”Wilson love Taylor”这句话在FastText模型的输入特征图:

图3 FastText模型输入特征图
如上图所示,FastText模型的输入主要包括两部分特征,第一块是词向量特征w1、w2和w3,第二块是n-gram特征w12和w23(这里n设置为2)。将这两部分特征相加之后取均值就得到这句话语义向量特征,也就是h=(w1+w2+w3+w12+w23)/5。拿到语义向量特征之后就可以通过softmax函数进行分类。 因为n-gram特征量级远比词向量级大,所以不会全部存储n-gram特征,这里主要通过Hash桶的方式进行存储。将所有的n-gram特征分配到对应的Hash桶中,不仅可以使查询的效率为O(1),而且可以控制内存消耗,但是可能存在不同的n-gram特征分配到同一个桶中,引起hash冲突,但是当桶的数量设置较大可以有效降低hash冲突。
2.3 FastText优化项
FastText采用了word2vec的优化流程:基于层次的softmax和负采样。当文本分类的类别很多时通过层次的softmax可以有效提升模型的训练速度。关于层次的softmax和负采样流程感兴趣的小伙伴可以详细了解下,这也是我在参加校招面试中最喜欢问的问题。
小结下,FastText主要可以用于训练词向量和文本分类任务中,因为只有一层隐藏层,所以模型的训练和速度非常快,同时由于模型效果较好,所以广泛应用在工业界中。
03
源码实践FastText文本分类任务
上一节主要介绍了FastText的理论知识,下面则主要从源码实践的角度介绍FastText。因为我们的项目主要是用FastText进行文本分类任务,下面则主要介绍文本分类源码实践。
3.1 导入FastText包
通过pip导入FastText包:pip install fasttext。
这里分享个诀窍,之前经常用清华源导入python包,发现有些包没有或者导入速度很慢,最近使用 豆瓣源很好用,推荐小伙伴使用下。
3.2 模型训练和存储流程
下面是FastText模型进行文本分类任务训练和存储的代码,训练函数train_supervised相关参数讲解已经添加在源码注释中了:
import fasttext.FastText as fasttext
classifier = fasttext.train_supervised(
input=train_cut_path, # 训练集文件路径,中文需要进行分词
label="__label__", #标签前缀
lr=0.01, # 学习率
dim=300, # 词向量维度
ws=5, # 内容窗口大小
epoch=5, # 训练轮数
loss="softmax", # 使用的损失函数
minCount=2, # 最小词频数
wordNgrams=4 # 词n-gram的长度
)
classifier.save_model(modelpath)
3.3 模型预测流程
下面是FastText模型预测源码,对于中文来说cut_text是经过分词的文本,k是topk概率的类别,设置为-1时返回所有类别。
predict_result =classifier.predict(cut_text, k=-1)
04
总结及反思
本篇从理论到实践介绍了Facebook开源的FastText模型。首先介绍了背景,由于工作需要对当前语音助手红线模型进行优化,而当前模型使用的是FastText模型;然后从理论方面重点介绍了FastText模型,主要用于词向量训练和文本分类任务中,因为速度快和不错的效果所以广泛应用在工业界。FastText模型结构简单,将词向量和n-gram特征作为模型输入,进行求和取平均即可得到语义向量特征,最后接一个softmax进行分类;最后从源码实践的角度介绍了FastText文本分类流程。对于想了解FastText模型并且应用到线上文本分类任务中的小伙伴可能有所帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。
Original: https://blog.csdn.net/abc50319/article/details/121200363
Author: 数据拾光者
Title: 广告行业中那些趣事系列44:NLP不可不学的FastText模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544822/
转载文章受原作者版权保护。转载请注明原作者出处!