
方法论
作者提出三种FineTune Bert的方法:1)直接使用下游目标数据集进行FineTune;2)先在目标领域上进一步Pretraining Bert, 再利用目标数据集FineTune; 3)与方法2类似,但加入了Multi-Task FineTune。
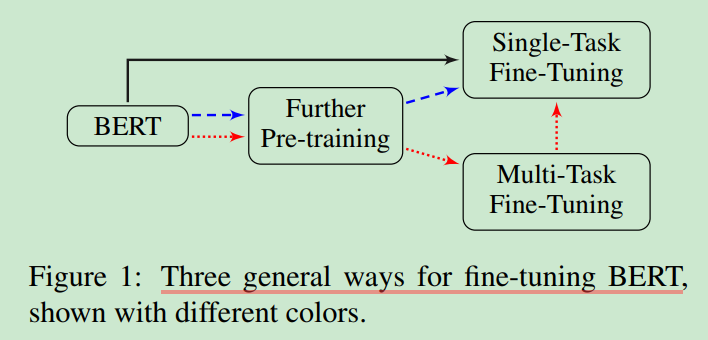

; 进一步预训练
已有很多研究表明,在目标领域进一步预训练预训练模型,能提升预训练模型在下游任务的表现,依据进一步预训练的数据集,可分为三类:1)预训练时,仅能使用下游目标标注数据集;2)预训练时,可以使用目标任务所在领域的大量数据,比如信用分类时,可以使用大量的金融新闻报道;3)通用语料。论文后续实验证明, 进一步的领域预训练是最佳的。
Multi-Task FineTune
MT_DNN已证明 MTL 与 pretraining 技术具有互补性,因此,如果有相关数据集的条件,尽可能进行MT FineTune。
实验结果

长文本分类的处理,取”头+尾”的策略最佳。
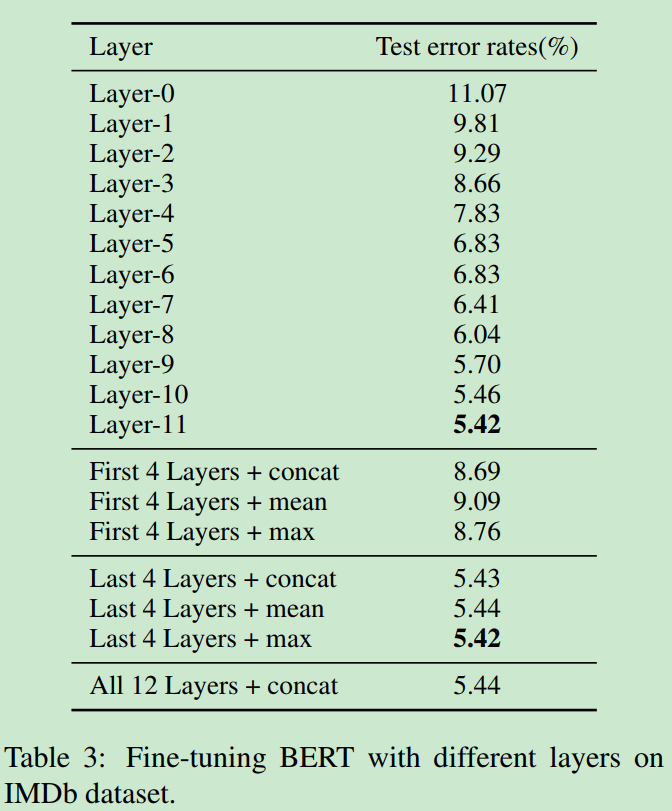
取最后一层的输出特征,效果最佳。
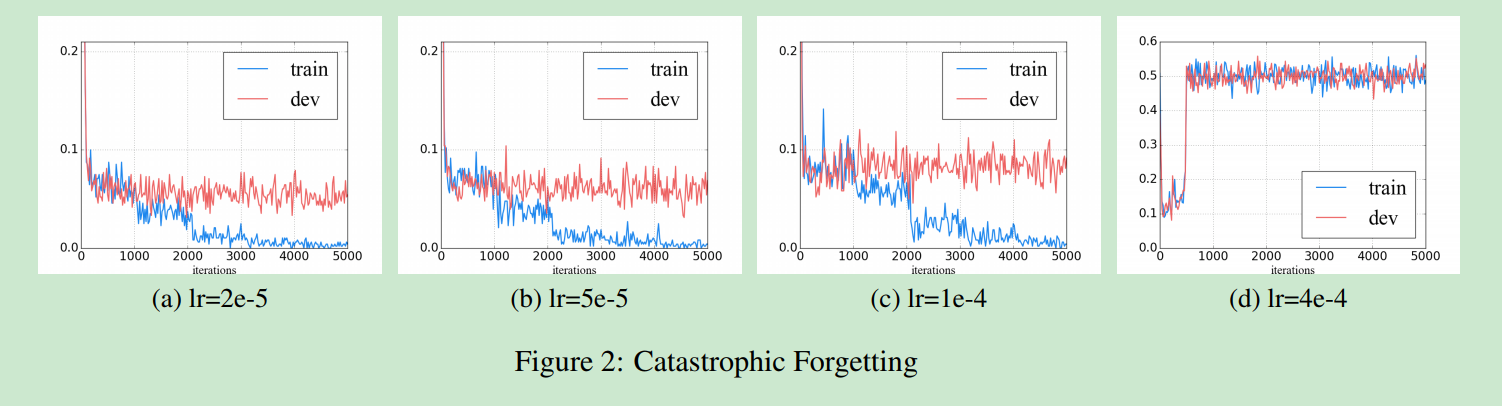
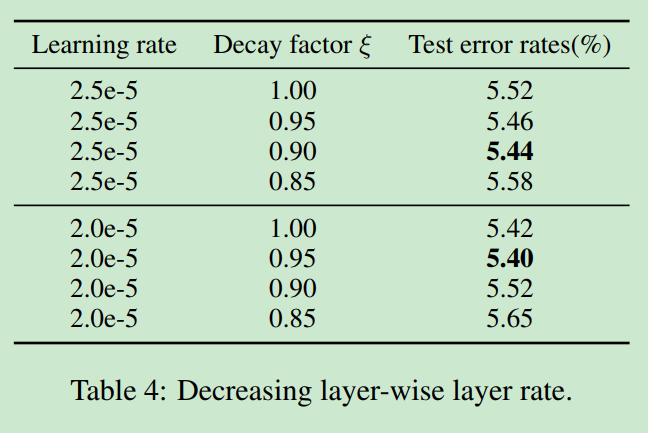
遗忘预训练过程学习到的知识,是迁移学习面临的重要问题。通过优化的学习率策略,可以减低该问题的负面效果。实验结果表面,使用 较低的学习率2e-5,比4e-4更好,注意论文使用了ULMFiT中的 “斜三角学习率” 与 ” 为不同层设置不同学习率“的策略, 层学习率的衰减为0.95。
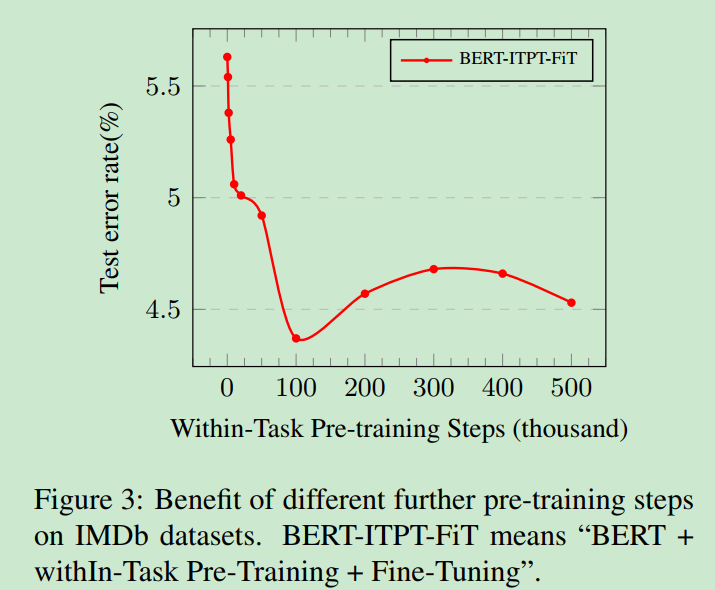
在目标任务的训练集上进一步Pretrain, 经过 100K 步之后,效果最优。

进一步的领域预训练有助于提升效果。
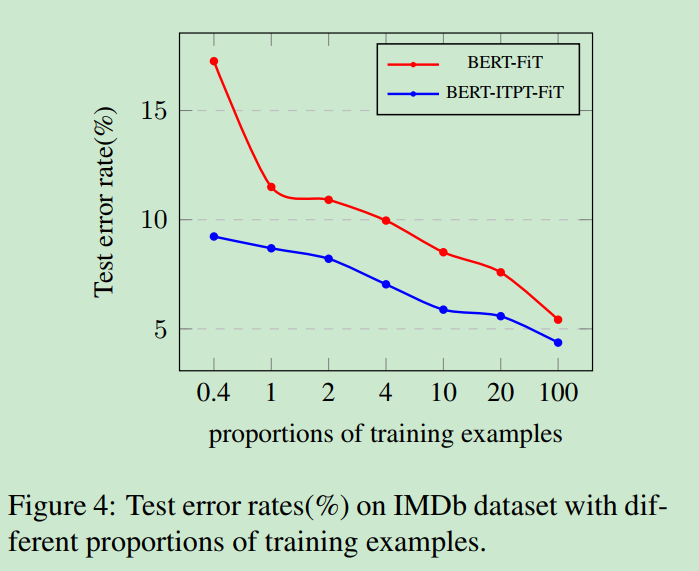
下游任务有 100标注数据表现已较优。
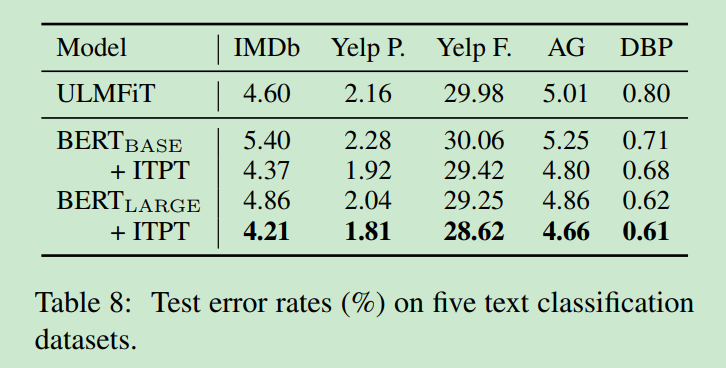
Bert_Large 能进一步提升效果。
Original: https://blog.csdn.net/weixin_44815943/article/details/123897952
Author: 凯子要面包
Title: 《How to Fine-Tune BERT for Text Classification》论文笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544409/
转载文章受原作者版权保护。转载请注明原作者出处!