

【论文笔记】An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale(Vision Transformer, ViT)
- 文章题目:An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
- 作者:Dosovitskiy, A., Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, M. Dehghani, Matthias Minderer, Georg Heigold, S. Gelly, Jakob Uszkoreit and N. Houlsby
- 时间:2020
- 来源:ICLR 2021 / ArXiv
- paper:http://arxiv.org/pdf/2010.11929v1
- code:https://github.com/google-research/vision_transformer , https://github.com/lucidrains/vit-pytorch , https://github.com/likelyzhao/vit-pytorch
- 引用:Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al (2020). An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.ArXiv, abs/2010.11929.
感性认识
- 研究的基本问题
将Transformer直接应用于图像领域,进行图像分类任务,而不修改Transformer架构,也不使用CNN。 - 主要想法
将image分割成大小一致的patch,对应于NLP中的token,再将其进行嵌入表示,成为Transformer的输入。在patch前加入一个class表示,对应全局信息(图片分类),进行最终的预测。 - 结果与结论
在中规模数据上,表现一般。在大规模数据集预训练下,表现优异。且节省训练开销。 - 不足与展望
1.无法保留图像的二维结构信息(局部特性,归纳偏置),要依靠大量数据来弥补。
2.预训练与微调的开销问题。如何更有效利用自监督的预训练。
3.将transformer应用于cv中的其他领域。
理性认识
1. 摘要(abstract)
尽管Transformer架构已经在自然语言处理领域大杀特杀,但是在计算机视觉领域只有有限的应用。在视觉领域中,注意力机制要么与卷积网络结合使用,要么在保持整体结构不变的情况下,替换卷积网络的某些组件。我们证明了, 对CNN的依赖不是必要的,在图象识别任务中,在图像块(image patches)的序列上应用纯粹的Transformer模型也可以表现得很好。当使用大量数据进行预训练,再迁移到多个中小型图象识别基准库后,ViT得到了优异的结果,相比于最先进(SOTA)的卷积网络,而训练所需要的计算资源更少。
2. 引言(INTRODUCTION)
基于Self-attention的架构,特别是Transformer,已经成为自然语言处理(NLP)的不二选择。其主要方法是在一个大型文本语料库上进行预训练,然后在一个较小的特定于任务的数据集上进行微调。得益于Transformer的计算效率和可扩展性,它可以训练具有超过100B的参数的超大模型。而且随着模型和数据集的增长,性能仍然没有饱和的迹象。
当然,在计算机视觉中,卷积仍然占主导地位。受NLP成功的启发,许多工作尝试将Self-attention融合进cnn架构,甚至一些人使用Self-attention替换卷积。后一种模型虽然理论上有效,但还没有在现代硬件加速器上得到有效扩展。因此,在大规模图像识别中,经典的ResNet(残差网络)式结构仍然是最先进的。
受NLP中Transformer成功的启发,我们尝试 将一个标准Transformer直接应用到图像上,尽可能少的修改。为此,我们 将图像分割成小块,并将这些块转化为线性嵌入序列,作为Transformer的输入。图像块(image patches)就相当于NLP任务中的单词(token)来做处理。并以有监督的方式训练图像分类模型。
当在中等规模的数据集(如ImageNet)上进行训练时,模型的准确率比同等规模的resnet低几个百分点。这一看似令人沮丧的结果是意料之中的: Transformer缺乏cnn所固有的一些归纳偏置(inductive biases),如平移不变性(translation equivariance)和局部性(locality),因此在数据量不足的情况下训练时不能很好地泛化。
然而,如果在更大的数据集(1400 -300万张图像)上训练模型,情况就会发生变化。我们发现大规模的训练可以克服归纳偏置(inductive biases)。当ViT在足够的规模上进行预先训练,并迁移到具有较少数据量的任务时,可以获得出色的结果。
3.相关工作
Transformer是由Vaswani等人提出,应用于机器翻译,并已成为许多自然语言处理任务中最先进的方法。基于Transformer的大型模型通常在大型语料库上进行预先训练,然后针对当前的任务进行微调。
单纯地对图像进行Self-attention需要每两个像素计算attention。这是像素的平方倍的开销。为了将Transformer应用到图像中,尝试许多近似方法。Parmar等人对每个query像素只在局部邻域计算Self-attention,而非全局。这种局部多头点积Self-attention块可以完全替代卷积。其他的,稀疏Transformer采用可扩展的近似全局Self-attention,以适用于图像。计算attentio的另一种方法是将其应用于不同大小的块中,在极端情况下,仅沿着单个轴。这些专门的注意力架构在计算机视觉任务中表现出了很好的效果,但需要复杂的工程设计。
最为相关的是Cordonnier等人的模型,该模型从输入图像中提取大小为2 × 2的小块,并在之上使用完全的Self-attention。这个模型与ViT非常相似,但我们的工作进一步证明,大规模的预培训可以使香草Transformer与最先进的cnn竞争(甚至更好)。此外,Cordonnier 使用的是2 × 2像素的小块,这使得该模型仅适用于小分辨率的图像,而我们也可以处理中等分辨率的图像。
最近的另一种相关模型是image GPT (iGPT),它在降低图像分辨率和颜色空间后,对图像像素使用Transformer。该模型以无监督的方式作为生成模型进行训练,然后可以对结果表示进行微调或线性探测以提高分类性能,在ImageNet上达到72%的最大精度。
4.方法(Method)
在模型设计中,尽可能地遵循原Transformer结构。这样做的优点是可扩展性和易实现——几乎可以开箱即用。
4.1 VIT
结构图:
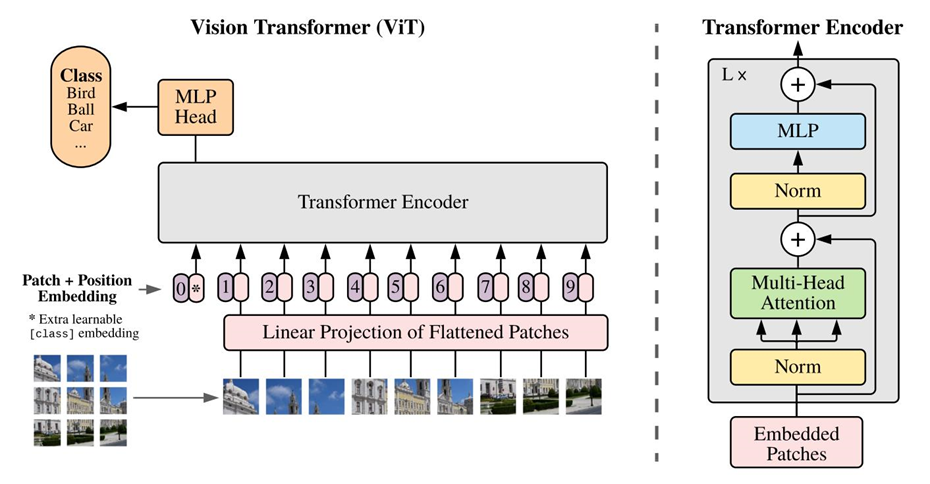

标准的接受token的一维嵌入向量作为输入。为了处理二维数据,要进行reshape。
原始图像输入:(H,W)是图片分辨率,C是通道数 x ∈ R H × W × C \text{x\ }\in \ \mathbb{R}^{H\times W\times C}x ∈R H ×W ×Creshape(分割patch):P是patch的大小,N是patch的个数x ∈ R N × ( P 2 ⋅ C ) , N = H W / P 2 \text{x\ }\in \ \mathbb{R}^{N\times \left( P^2\cdot C \right)} , N=HW/P^2 x ∈R N ×(P 2 ⋅C ),N =H W /P 2flatten(拍平,映射成Transformer接受的固定大小D,映射E是可学习的):z 0 = [ x c l a s s ; x p 1 E ; x p 2 E ; ⋯ ; x p N E ] + E p o s , E ∈ R ( P 2 ⋅ C ) × D , E p o s ∈ R ( N + 1 ) × D \mathbf{z}0=\left[ \mathbf{x}{class};\mathbf{x}{p}^{1}\mathbf{E;x}{p}^{2}\mathbf{E;}\cdots ;\mathbf{x}{p}^{N}\mathbf{E} \right] +\mathbf{E}{pos}\ ,\ \mathbf{E}\in \mathbb{R}^{\left( P^2\cdot C \right) \times D},\ \mathbf{E}_{pos}\in \mathbb{R}^{\left( N+1 \right) \times D}z 0 =[x c l a s s ;x p 1 E ;x p 2 E ;⋯;x p N E ]+E p o s ,E ∈R (P 2 ⋅C )×D ,E p o s ∈R (N +1 )×D映射后的结果称为 patch embeddings。
在patch前面添加一个可学习的xclass,代表着图片的标签信息(全局信息)
归纳偏置(Inductive bias):vit比cnn有更少的特定于图像的归纳偏置。在cnn中,局部性、二维邻域结构和平移不变性贯穿整个模型的每一层。在ViT中,只有MLP层是局部和平移等变的,而Self-attention是全局的。二维邻域结构使用地非常少:在模型开始时,将图像切割成小块,并在微调时对不同分辨率的图像进行位置嵌入调整。除此之外,初始化时的位置嵌入不包含块的二维位置信息,所有块之间的空间关系都需要从头学习。
混合结构(Hybrid Architecture):输入序列可以由CNN的feature map组成,从而替代原始图像块。在这个混合模型中,将patch embedding 应用于从CNN feature map中提取的patches。作为一种特殊情况,patches的尺寸可以是1×1,即简单地将feature map平坦化,并映射到Transformer的尺寸即可得到输入序列。如上所述添加分类输入嵌入和位置嵌入。
; 4.2 微调和更高的分辨率 (FINE-TUNING AND HIGHER RESOLUTION)
通常,在大型数据集上预训练ViT,并微调到(较小的)下游任务。为此,我们 去掉预先训练的预测头,并附加一个零初始化的D*K前馈层,其中K是下游类的数量。在输入高分辨率的图像时,我们保持了相同的patch大小,从而得到了更大的有效序列长度。视觉转换器可以处理任意序列长度(达到内存限制),然而,预先训练的位置嵌入不再有意义。因此,我们根据预先训练好的位置嵌入在原始图像中的位置,对其进行二维插值。分辨率调整和块提取是唯一一处人工将图像二维结构的归纳偏置注入vit的地方。
5.实验(EXPERIMENTS)
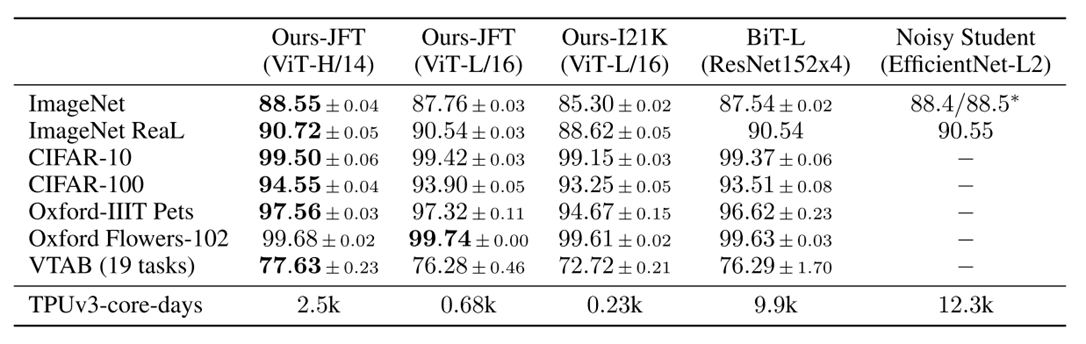
评估了ResNet、Vision Transformer (ViT)和hybrid的学习能力。为了了解每个模型的数据需求,对不同大小的数据集进行了预训练,并评估了许多基准任务。在考虑模型预训练的计算成本时,ViT表现得非常好,以较低的预训练成本在大多数识别基准上达到了最先进的水平。
5.1 setup
数据集(datasets):各种大小的数据集以及测试基准。
模型变体(Model Variants):基于BERT配置VIT,各种大小的VIT(base,large,huge),patch的大小P也是可调的,P越大,序列长度越小。P越小,长度越长,计算开销越大。
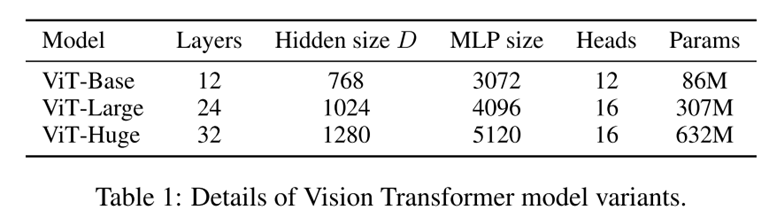
训练和微调(Training & Fine-tuning.):模型的参数配置,见附录。
; 5.2 与SOTA比
6.结论(CONCLUSION)
探讨了Transformer在图像识别中的直接应用。与之前在计算机视觉中使用Self-attention的工作不同,除了初始的patch提取步骤,我们不引入图像特有的归纳偏差到架构中。相反,我们将图像解释为一系列块,并使用NLP中使用的标准Transformer编码器来处理它。这种简单但可扩展的策略,在与大型数据集的预训练相结合时,效果惊人地好。因此,视觉Transformer 在许多图像分类数据集上匹配或超过了最先进的水平,同时相对低成本地进行预训练。
虽然这些初步结果令人鼓舞,但仍然存在许多挑战。一种是将ViT应用于其他计算机视觉任务,如检测和分割。我们的研究结果,以及Carion等人(2020年)的研究结果,表明了这种方法的前景。另一个挑战是继续探索自监督的预训练方法。我们的初步实验表明,自监督的预训练有所改善,但自监督的预训练与大规模监督的预训练之间仍有很大的差距。最后,进一步扩展ViT可能会提高性能。
小尾巴
1.归纳偏置
2.自监督预训练
3.像素级别的图像应用
重点相关论文
1.Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
Transformer 的提出,祖师爷
2.Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
BERT 模型,这篇论文中大量的设计来自BERT,如xclass标志位,自监督预训练等
3.Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between selfattention and convolutional layers. In ICLR, 2020.
像素级,小块级别的attention,和vit很一致
4.Mark Chen, Alec Radford, Rewon Child, Jeff Wu, and Heewoo Jun. Generative pretraining from pixels. In ICML, 2020a.
像素级别,使用Transformer的图像生成模型
参考列表
1.https://blog.csdn.net/weixin_38443388/article/details/113059350
2.https://zhuanlan.zhihu.com/p/336911305
3.https://blog.csdn.net/qq_16236875/article/details/108964948
4.https://zhuanlan.zhihu.com/p/273652295
5.https://blog.csdn.net/weixin_44106928/article/details/110268312
6.https://blog.csdn.net/moxibingdao/article/details/109127507
7.http://www.360doc.com/content/21/0126/16/73546223_959052179.shtml
8.http://www.360doc.com/content/21/0116/16/32196507_957302113.shtml
9.https://zhuanlan.zhihu.com/p/266311690
10.https://openreview.net/forum?id=YicbFdNTTy
Original: https://blog.csdn.net/qq_44055705/article/details/113825863
Author: 1000110011111101010100101111101
Title: 【论文笔记】An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale (ViT)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/542995/
转载文章受原作者版权保护。转载请注明原作者出处!