

单句文本分类是最常见的自然语言处理任务,需要将输入文本分成不同类别。例如:在情感分类任务SST-2中,需要将影评文本输入文本分类模型中,并将其分成褒义或贬义。
- 建模方法
应用BERT处理单句文本分类任务的模型由输入层、BERT编码层和分类输出层构成。处理过程如下图所示(图源李宏毅老师课件):
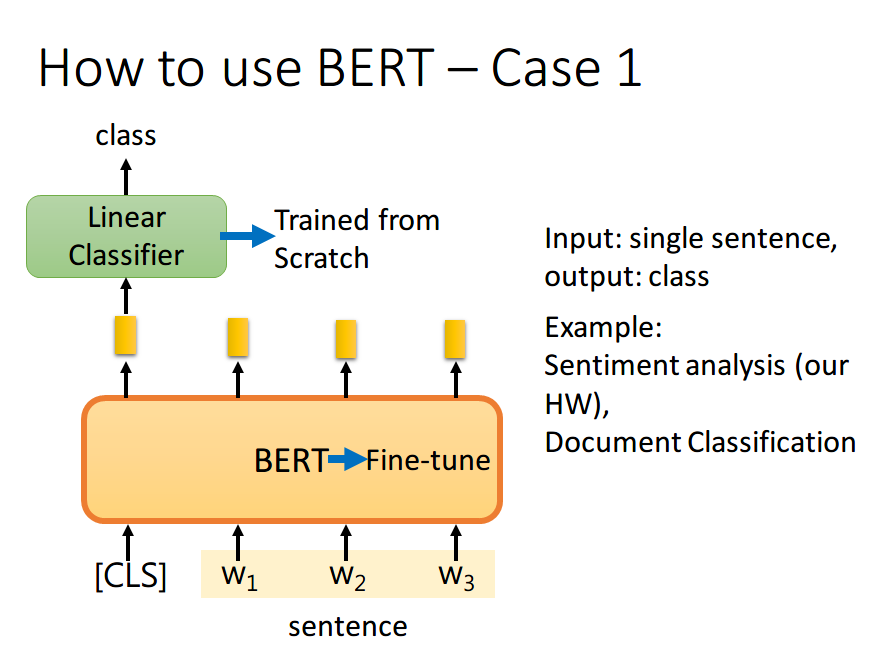

- 首先在句子的开头加一个代表分类的符号[CLS]
- 然后将该位置的output输入到Linear Classifier,进行predict,输出一个分类。
注:整个过程中 Linear Classifier 的参数是需要从头开始学习的,而 BERT 中的参数微调就可以了。
为什么要用[CLS]来进行分类?
因为 BERT 内部是 Transformer,而 Transformer 内部又是 Self-Attention,所以
[CLS]的output肯定含有整句话的完整信息。但是Self-Attention计算的向量,自己本身和自己的值肯定是最相关的。现在假设使用w 1 w_1 w 1 的output做分类,这那么这个output实际上会更加看重w 1 w_1 w 1 ,而w 1 w_1 w 1 又是一个有实际含义的字或者词,这样难免会影响到最终的结果。但是[CLS]是没有任何意义的占位符,所以就算[CLS]的 output 中自己的值占大头也无所谓.
; 2. 代码实现
接下来结合实际代码,介绍BERT在单句文本分类任务中的训练方法。这里以英文情感二分类数据集SST-2为例介绍。
这里主要应用了由HuggingFace开发的transformers包和datasets库进行建模,可以极大地简化数据处理和模型建模过程。
- 导入包和加载训练数据、分词器、预训练模型和评价方法
import numpy as np
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForSequenceClassification,TrainingArguments,Trainer
dataset = load_dataset('glue', 'sst2')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
model = BertForSequenceClassification.from_pretrained('bert-base-cased', return_dict = True)
metric = load_metric('glue', 'sst2')
- 对训练集分词
def tokenize(examples):
return tokenizer(examples['sentence'], truncation=True, padding='max_length')
dataset = dataset.map(tokenize, batched=True)
encoded_dataset = dataset.map(lambda examples:{'labels':examples['label']}, batched=True)
- 将数据集转化为torch.Tensor类型以训练PyTorch模型
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'labels']
encoded_dataset.set_format(type='torch', columns=columns)
- 定义评价指标
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=np.argmax(predictions, axis=1), references=labels)
- 定义训练参数TrainingArguments,默认使用AdamW优化器
args = TrainingArguments(
'ft-sst2',
evaluation_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=2
)
- 定义Trainer,指定模型和训练参数,输入训练集、验证集、分词器和评价函数
trainer = Trainer(
model,
args,
train_dataset =encoded_dataset["train"],
eval_dataset = encoded_dataset["validation"],
tokenizer = tokenizer,
compute_metrics = compute_metrics
- 进行训练
trainer.train()
- 训练完毕后,开始测试
trainer.evaluate()
结果:
{'eval_loss': 0.4584292471408844,
'eval_accuracy': 0.9162844036697247,
'eval_runtime': 25.5729,
'eval_samples_per_second': 34.099,
'epoch': 2.0,
'eval_mem_cpu_alloc_delta': 215077,
'eval_mem_gpu_alloc_delta': 0,
'eval_mem_cpu_peaked_delta': 270242,
'eval_mem_gpu_peaked_delta': 144781312}
参考资料
Original: https://blog.csdn.net/m0_50896529/article/details/121762937
Author: 郑不凡
Title: BERT微调之单句文本分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/542983/
转载文章受原作者版权保护。转载请注明原作者出处!