
1. Transformer
transformer有很多种形式,Transformer,Universal Transformer,Transformer XL,GPT,BERT,ERNIE,XLNet,MT-DNN。一下子全讲了那我估计人没了,决定还是学网络,用到一个就填一个坑,今天先说一下Transformer。
Transformer 是一种新的、基于 attention 机制来实现的特征提取器,可用于代替 CNN 和 RNN 来提取序列的特征。
同时相比于LSTM,GRU这种循环神经网络结构,Transformer可以直接补货序列中的长距离依赖关系,并且模型的并行程度高,可以减少训练时间。
2. Transformer的网络结构
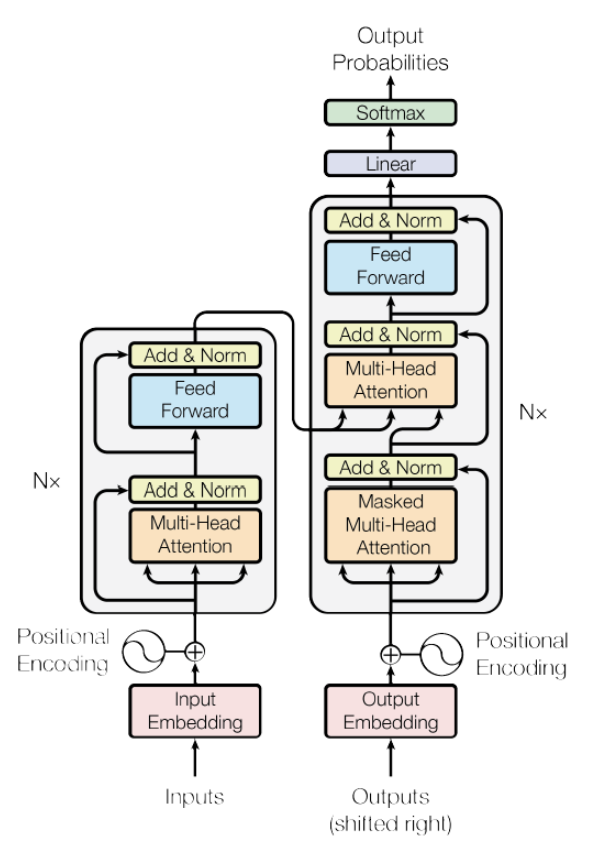

这个就是今天Transformer的主要结构了,里面包括了一个编码器,一个解码器。同样我们针对编码器和解码器一个一个看里面有什么结构以及每一个结构的运算方式,还有最终走一遍流程来达到学习Transformer的效果。
3. Input Embedding
由于transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给transformer, 才能识别出语言中的顺序关系
首先我们先对每一个词都做一个Embedding,我们定义为Embedding后的输出size叫 Embedding Size,然后假如我们有一个句子,叫”今天天气不错”,有六个字符,经过INput Embedding Layer后,我们会得到一个 6 * Embedding Size 的矩阵。这个矩阵的每一行都代表一个字符。
假如我们的 Embedding Size 的维度是512,于是我们会有一个6*512的矩阵
然后要做一个 Positional Encoding 的操作,这是为什么呢?就是这一小节的黑体字提到了,得带有位置信息,才知道顺序关系呀。于是我们用以下的公式去做计算
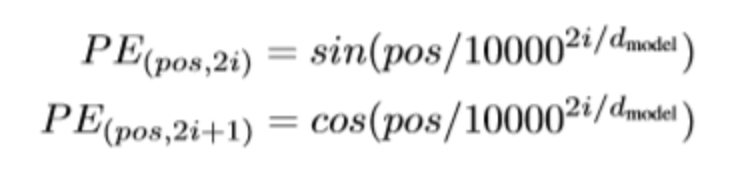
这里的i究竟是指什么意思呢?我们先知道一个背景,现在我们手上已经有每一个词对应的EMbedding向量了,拼接成一个 6 * Embedding Size 的矩阵,然后我们为了获得位置关系,相采用上面说的公式,去计算一个位置信息,这里是这样,每一个词都会对应的到一个位置向量,也就是我们最后会得到一个 6* Embedding Size的位置信息矩阵。具体的i,指的是当前的下标,所以我们计算下标对应的值是成双成对地计算出来的。
最后,我们将两个6 * 512 的矩阵对应位置直接相加,也就是Embedding矩阵和位置信息矩阵的对应下标元素直接相加就好了。
得到的结果还是一个 6* 512 的矩阵,但是这个剧震已经融合了Embedding信息和位置信息了。我们管这个矩阵叫Xembedding_pos
4. Multi-Head Attention
这一小节要引用强哥的图了
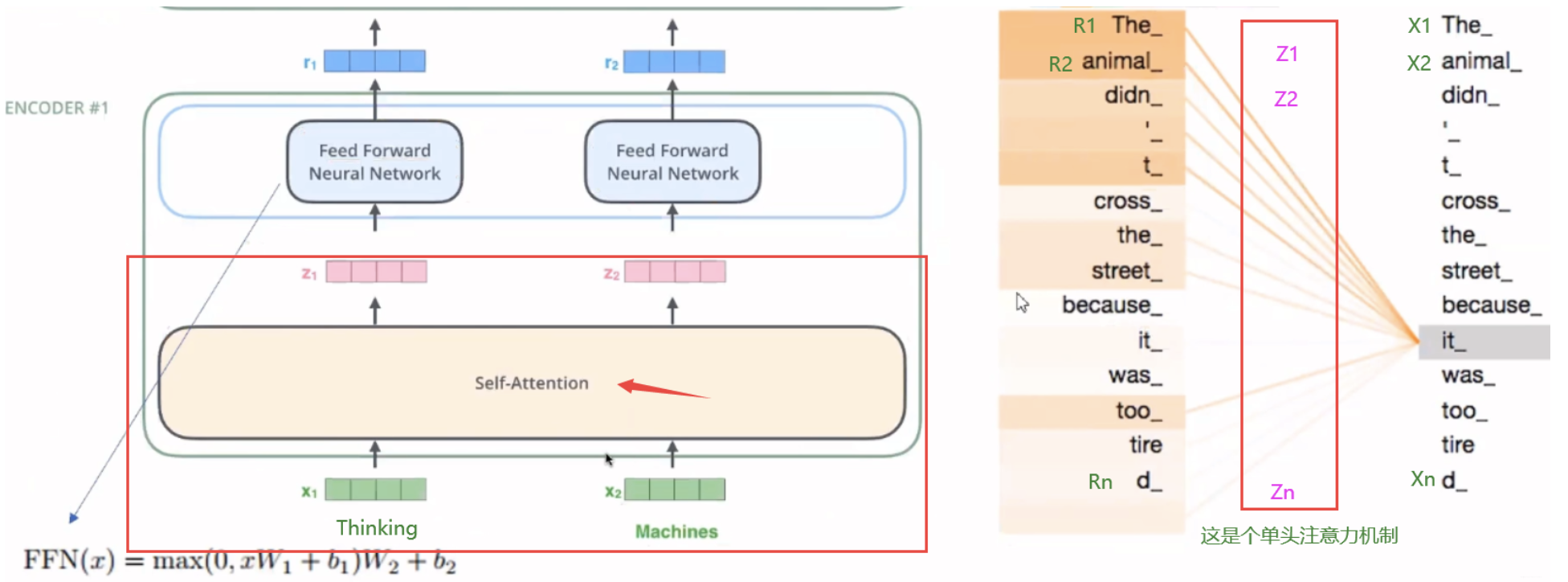
这里用图(例子)的话来做分析 The animal didn’t cross the street, because it was too tired.
我们看 It 这个词最后得到的R矩阵(里面有R1,R2,…,Rn)里面,可以看到
和 和 It 最相关。
每一个字经过和It计算后 组织起来会对应一个R矩阵, 这个R矩阵就是表示这个字与其他字之间某个角度上的关联性信息,这叫做单头注意力机制。从上面这个图来看,颜色最深就是说明最有关系了,也就是 It 表示的是The animal
上看是弹头的,下面看多头的

左边这个是两头的注意力机制,上面说到这个橙色的这个注意力反映了It这个词指代的信息。 而这个绿色的这个注意力,反应了It这个词的状态信息,可以看到It经过这个绿色的注意力机制后,tired 这个词与 It 关联最大,就是说It,映射过去,会更关注 tired 这个词,因为这个正好是它的一个状态。 它累了。
右边就是一个字It,用了多头的注意力机制的情况了,他就是把每个头(角度)中关系最大的的给表示出来了,所以这下应该可以理解多头注意力机制究竟是在干嘛了。 每个字经过多头注意力机制之后会得到一个R矩阵,这个R矩阵表示这个字与其他字在N个角度上(比如指代,状态…)的一个关联信息,这个角度就是用多个头的注意力矩阵体现的。
我们把多头理解为从多个方向(角度)去学习/认识这个It的单词。
上面的这个做法,我们怎么实现呢?我们用三个矩阵去做处理,分别是Q,K,V矩阵,这里用一个强哥的图来做一下直观的解释:
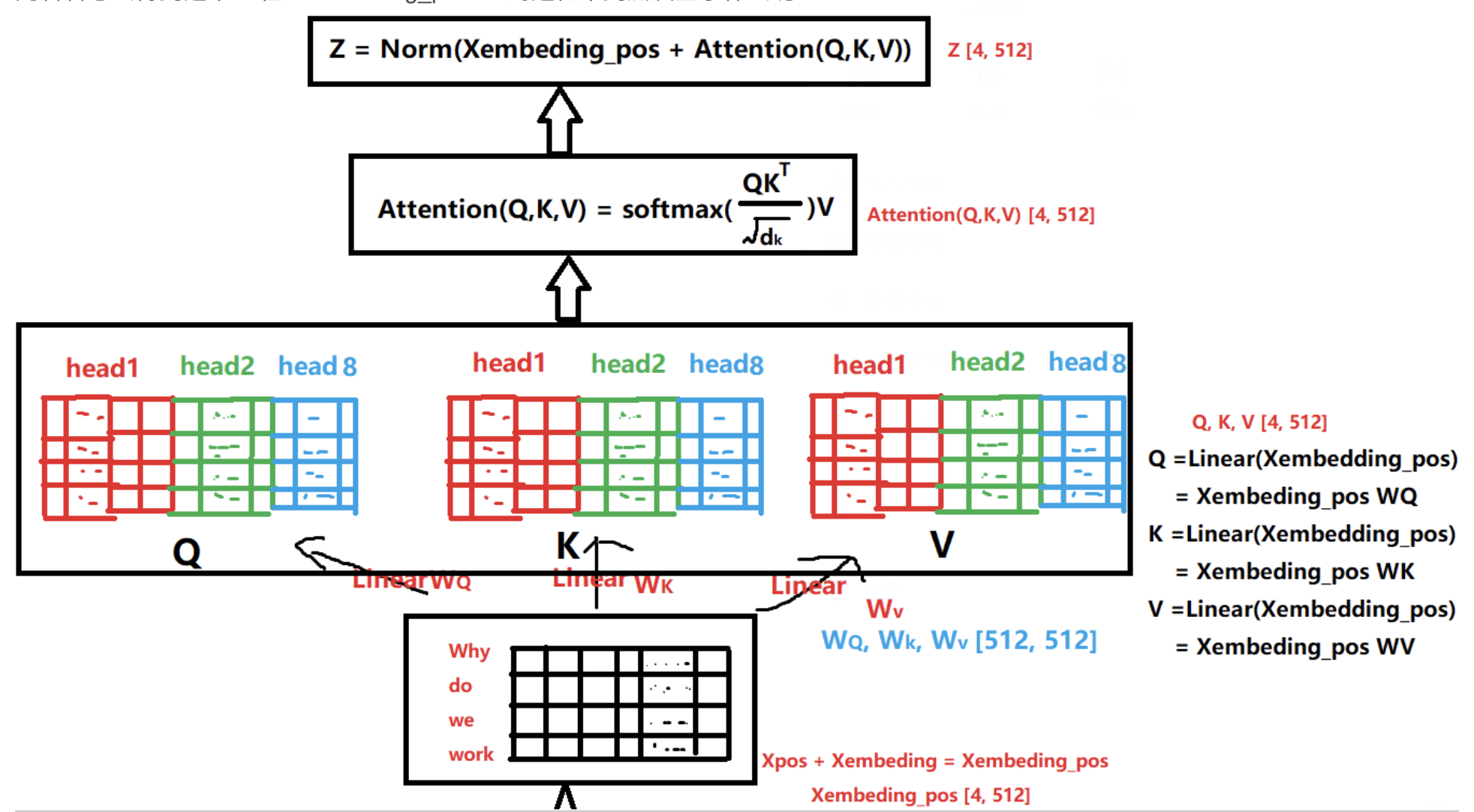
你看强哥里面的 《why do we work 》其实就是我们自己例子《今天天气不错》,然后我们分别经过三个全连接层,得到了Q,K,V矩阵。其中假如我们现在有八个头(角度)来解释每一个词语,Embedding维度继续是512,然后有6个词。我们先看Q矩阵,我们经过Linear的全连接里面的
矩阵,然后输出也是一个 6 * 512 的矩阵,这里面有512列,这512列就包括八个角度的R矩阵,所以就是相当于我们算完了一个角度,就把每一个head(角度)给横向拼接起来。每一个head(角度)的矩阵是 6 * (512/8)。 最后拼接起来就是一个 6 * 512 的Q矩阵了。
随后,K和V矩阵都是这么计算出来,那么QKV矩阵都是代表什么意思呀?
Q表示Query,K表示Key,V表示Value。之所以引入了这三个矩阵,是借鉴了搜索查询的思想,比如我们有一些信息是键值对(key->value)的形式存到了数据库,(5G->华为,4G->诺基亚), 比如我们输入的Query是5G, 那么去搜索的时候,会对比一下Query和Key, 把与Query最相似的那个Key对应的值返回给我们。 这里是同样的思想,我们最后想要的Attention,就是V的一个线性组合,只不过根据Q和K的相似性加了一个权重并softmax了一下而已。
好,现在我们知道了QKV的作用,那怎么表示出 借鉴了搜索查询的思想呀?还有最后的V的一个线性组合,根据Q和K的相似性加了一个权重,再softmax映射出权重, 再把这个权重反乘到各自词语的embedding身上,再加权求和,就相当于融于了其他词的相关信息。下面来看看呀
怎么得到
和的相似度呢? 我们想到了点积运算, 我们还记得点积运算的几何意义吗?两个向量越相似,点积结果就越大。
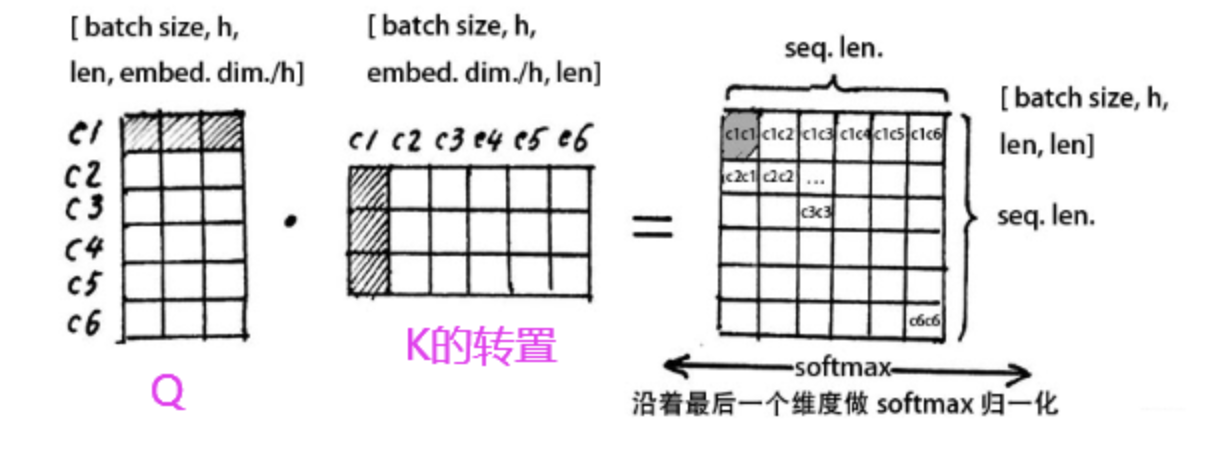
这里的Q的每一行,读代表了每一个字的第一个角度(head)麻,我们就理解为一个字代表的特征,然后和K的转至进行相乘(也就是和每一个列都做点积运算)从而得到了,Q里面的一个字和其他每一个字的相似度了,得出的矩阵就是head1角度的注意力矩阵。
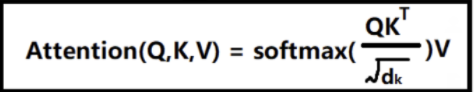
然后看前面两张图,发现除了一个根号dk,这里上网查了别的解释:
这里再解释下为啥会
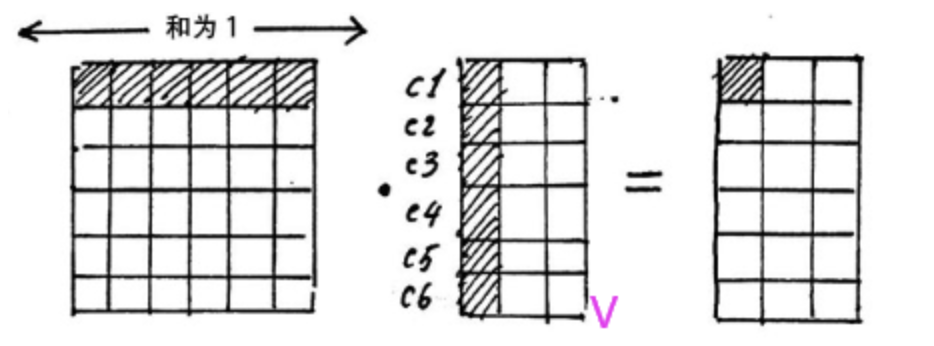
然后怎么做softmax呢?
这时候,我们从注意力矩阵取出一行(和为1), 然后依次点乘V的列(包含了所有字的信息),因为矩阵V的每一行代表着每一个字向量的数学表达,这样操作,得到的正是注意力权重进行数学表达的加权线性组合,从而使每个字向量都含有当前句子的所有字向量的信息。这样就得到了新的X_attention(这个X_attention中每一个字都含有其他字的信息)。
用X_attention加上之前的Xembedding_pos得到残差连接,再经过一个LayerNormlization操作(也就是图中的Norm操作)就可以得到Z。
LayerNormlization的作用是把神经网络中隐藏层归一化为标准正态分布,起到加快训练速度,加速收敛的作用。具体操作是以行为单位,每一行减去每一行的均值然后除以每一行的标准差。
5. Feed Forward
我们上面通过多头注意力机制得到了Z,下面就是把Z再做两层线性变换,然后relu激活就得到最后的R矩阵了。
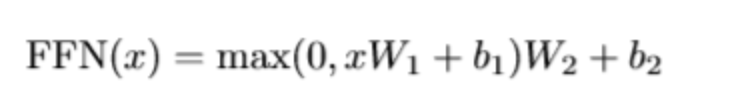
6. 继续做ADD & Norm操作
这里的ADD操作是其实是拿做Feed Forward前得到的Z,以及做完Feed Forward后得到的R矩阵进行一个Add操作,对应元素直接相加。
然后Norm操作还是上面提到的Layer Normlization,
是这一行的均值,是这一行的标准差用每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值。
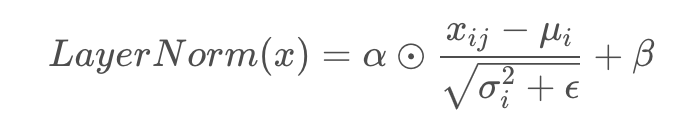
其中细节如下:之后引入两个可训练参数α , β来弥补归一化的过程中损失掉的信息, 注意⊙ 表示元素相乘而不是点积, 我们一般初始化α为全1,而β为0.
以上,是我们对一句话做Transformer的操作,我们在实际使用的时候,肯定不是一句话一句话地输入,而是把多句话放在一个batch里面,于是,里面有一些细节要做出适当的更改。
-
输入来的维度一般是[batch_size, seq_len, embedding_dim], 而 Transformer块的个数一般也是多个,这里的多个理解为 第一块的输出作为第二块的输入,然后再操作。论文里面是用的6个块进行的堆叠。
-
因为如果有多句话的时候,句子都不一定一样长,而我们的seqlen肯定是以最长的那个为标准,不够长的句子一般用0来补充到最大长度,这个过程叫做padding。
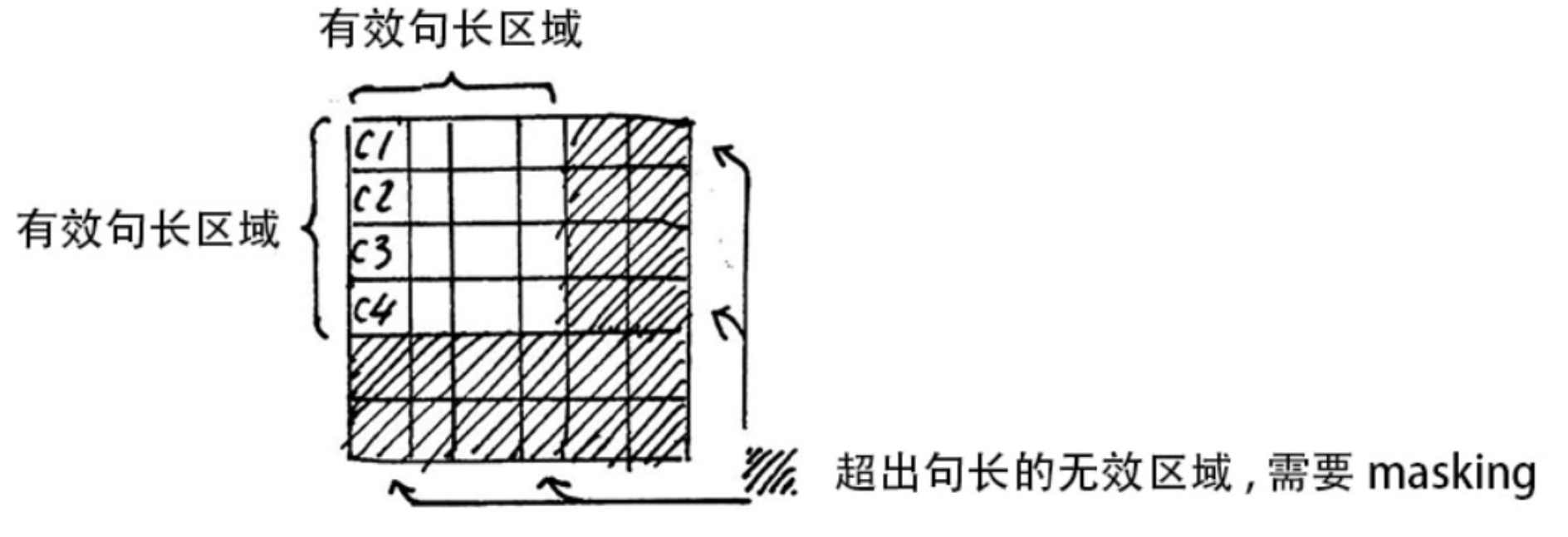
padding的部分就参与了softmax运算, 就等于是让无效的部分参与了运算, 会产生很大隐患, 这时就需要做一个mask让这些无效区域不参与运算, 我们一般给无效区域加一个很大的负数的偏置。这样使得无效区域经过softmax计算之后还几乎为0,这样就避免了无效区域参与计算.
这就做完了Transformaer的编码部分了,输入来的维度一般是[batch_size, seq_len, embedding_dim], 而 Transformer块的个数一般也是多个,这里的多个理解为 第一块的输出作为第二块的输入,然后再操作就好了,论文里面是用的6个块进行的堆叠。
Original: https://blog.csdn.net/Francis_s/article/details/121506967
Author: Francis_s
Title: 推荐系统 之 Transformer
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/542977/
转载文章受原作者版权保护。转载请注明原作者出处!