

使用掩码语言建模 (MLM) 目标的英语语言预训练模型。它在 本文中进行了介绍,并在此存储库中首次发布 。这个模型是不加壳的:它在英语和英语之间没有区别。
型号说明
BERT 是一种以自我监督的方式在大量英语数据语料库上进行预训练的变形金刚模型。这意味着它仅在原始文本上进行了预训练,没有人以任何方式标记它们(这就是它可以使用大量公开可用数据的原因),并通过自动过程从这些文本生成输入和标签。更准确地说,它经过预训练有两个目标:
- 掩蔽语言建模(MLM):取一个句子,模型随机掩蔽输入中 15% 的单词,然后通过模型运行整个被掩蔽的句子,并且必须预测被掩蔽的单词。这不同于通常一个接一个地看到单词的传统循环神经网络 (RNN),也不同于像 GPT 这样在内部掩盖未来标记的自回归模型。它允许模型学习句子的双向表示。
- 下一句预测 (NSP):模型在预训练期间将两个蒙面句子作为输入连接起来。有时它们对应于原文中相邻的句子,有时则不是。然后,该模型必须预测这两个句子是否相互跟随。
通过这种方式,模型学习了英语语言的内部表示,然后可用于提取对下游任务有用的特征:例如,如果您有一个标记句子的数据集,您可以使用 BERT 生成的特征训练标准分类器模型作为输入。
预期用途和限制
您可以将原始模型用于掩码语言建模或下一句预测,但它主要用于在下游任务上进行微调。查看模型中心以查找您感兴趣的任务的微调版本。
请注意,此模型主要针对使用整个句子(可能被屏蔽)做出决策的任务进行微调,例如序列分类、标记分类或问答。对于诸如文本生成之类的任务,您应该查看 GPT2 之类的模型。
如何使用
您可以将此模型直接用于掩码语言建模的管道:
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Hello I'm a [MASK] model.")
以下是如何使用此模型在 PyTorch 中获取给定文本的特征:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
限制和偏见
即使用于该模型的训练数据可以被描述为相当中性,该模型也可能有偏差的预测
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("The man worked as a [MASK].")
unmasker("The woman worked as a [MASK].")
这种偏差也会影响该模型的所有微调版本。
训练数据
BERT 模型在 BookCorpus 上进行了预训练, BookCorpus是一个由 11,038 本书和英文维基百科(不包括列表、表格和标题)组成的数据集。
培训程序
预处理
使用 WordPiece 和 30,000 的词汇量对文本进行小写和标记化。模型的输入则为:
[CLS] Sentence A [SEP] Sentence B [SEP]
以 0.5 的概率,句子 A 和句子 B 对应于原始语料库中的两个连续句子,而在其他情况下,它是语料库中的另一个随机句子。请注意,这里认为的句子是连续的文本跨度,通常比单个句子长。唯一的限制是包含两个”句子”的结果的总长度小于 512 个标记。
每个句子的掩蔽过程的详细信息如下:
- 15% 的令牌被屏蔽。
-
在 80% 的情况下,被屏蔽的标记被替换为[MASK].
-
在 10% 的情况下,被掩码的标记被替换为随机标记(不同),与它们替换的标记不同。
- 在剩下的 10% 的情况下,被屏蔽的令牌保持原样。
预训练
该模型在 Pod 配置中的 4 个云 TPU(总共 16 个 TPU 芯片)上进行了 100 万步训练,批量大小为 256。序列长度限制为 90% 的步长为 128 个标记,其余 10% 的步长为 512 个。使用的优化器是 Adam,学习率为 1e-4,b1=0.9\beta_{1} = 0.9和b2=0.999\beta_{2} = 0.999,权重衰减为 0.01,学习率预热 10,000 步,之后学习率线性衰减。
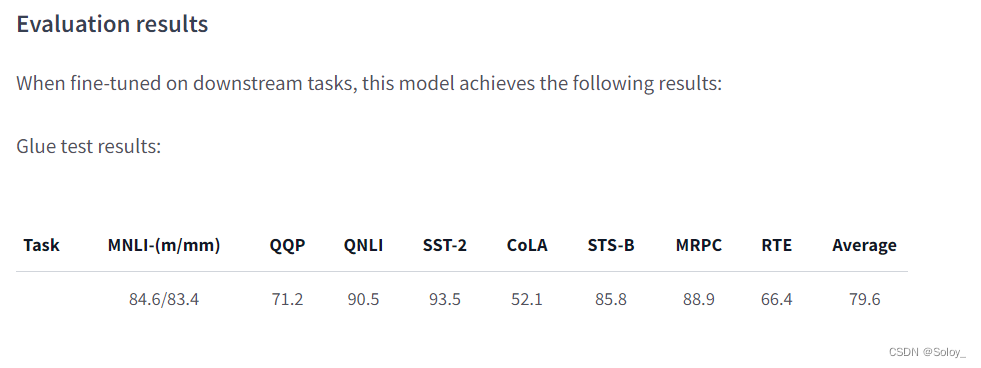

Original: https://blog.csdn.net/sikh_0529/article/details/126627630
Author: Sonhhxg_柒
Title: BERT 基础模型(无壳)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/542595/
转载文章受原作者版权保护。转载请注明原作者出处!