

JAVA 对象头分析及Synchronized锁
对象内存布局
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头( Header)、实例数据( Instance Data)和对齐填充( Padding)。
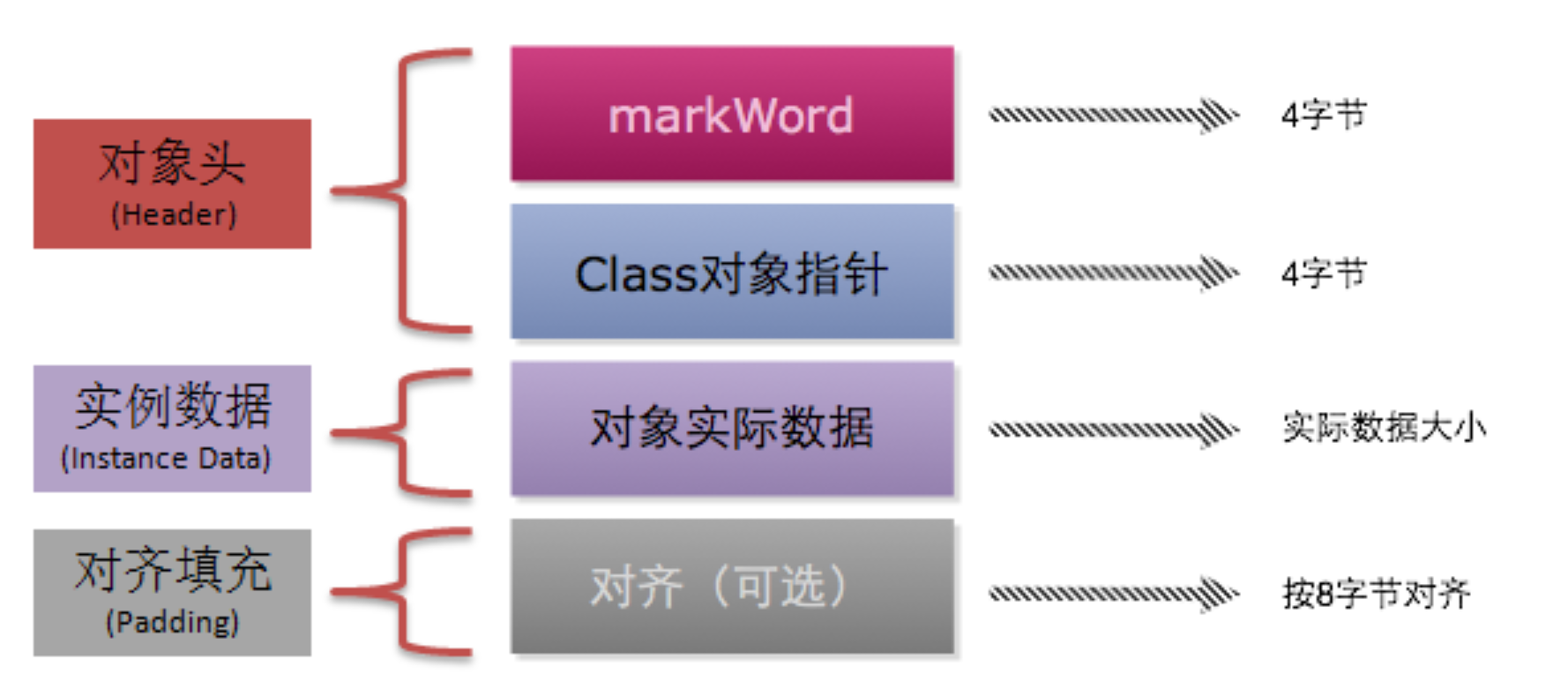

从上面的这张图里面可以看出,对象在内存中的结构主要包含以下几个部分:
Mark Word(标记字段):对象的Mark Word部分占4个字节,其内容是一系列的标记位,比如轻量级锁的标记位,偏向锁标记位等等。Klass Pointer(Class对象指针):Class对象指针的大小也是4个字节,其指向的位置是对象对应的Class对象(其对应的元数据对象)的内存地址- 对象实际数据:这里面包括了对象的所有成员变量,其大小由各个成员变量的大小决定,比如:
byte和boolean是1个字节,short和char是2个字节,int和float是4个字节,long和double是8个字节,reference是4个字节 - 对齐:最后一部分是对齐填充的字节,按
8个字节填充。
对象头详情
对象头包括两部分: Mark Word 和 类型指针。
标记字段(Mark Word)
MarkWord用于存储对象自身的运行时数据, 如哈希码( HashCode)、 GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
这部分数据的长度在 32位和 64位的虚拟机(暂不考虑开启 压缩指针的场景)中分别为 32个和 64个bits。
对象需要存储的运行时数据很多,其实已经超出了 32、 64位 Bitmap结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个 非固定的数据结构以便在极小的空间内存储尽量多的信息,它会 根据对象的状态复用自己的存储空间。
例如在 32位的 HotSpot虚拟机中对象未被锁定的状态下, Mark Word的 32个 bits空间中的 25bits用于存储对象哈希码( HashCode), 4bits用于存储对象分代年龄, 2bits用于存储锁标志位, 1bit固定为0,在其他状态(轻量级锁定、重量级锁定、 GC标记、可偏向)下对象的存储内容如下表所示。
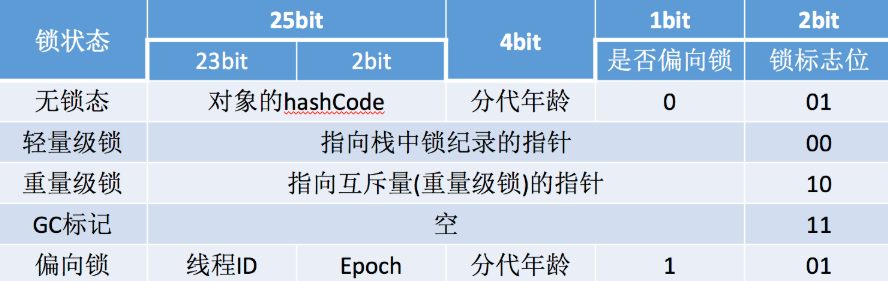
32位标记字段详情
|-------------------------------------------------------|--------------------|
| Mark Word (32 bits) | State |
|-------------------------------------------------------|--------------------|
| identity_hashcode:25 | age:4 | biased_lock:1 | lock:2 | Normal |
|-------------------------------------------------------|--------------------|
| thread:23 | epoch:2 | age:4 | biased_lock:1 | lock:2 | Biased |
|-------------------------------------------------------|--------------------|
| ptr_to_lock_record:30 | lock:2 | Lightweight Locked |
|-------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:30 | lock:2 | Heavyweight Locked |
|-------------------------------------------------------|--------------------|
| | lock:2 | Marked for GC |
|-------------------------------------------------------|--------------------|
lock:2位的锁状态标记位,由于希望用尽可能少的二进制位表示尽可能多的信息,所以设置了lock标记。biased_lock:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。age:4位的Java对象年龄。在GC中,如果对象在Survivor区复制一次,年龄增加1。当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。 由于age只有4位,所以最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。identity_hashcode:25位的对象标识Hash码,采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。当对象被锁定时,该值会移动到管程Monitor中。thread:持有偏向锁的线程ID。epoch:偏向时间戳。ptr_to_lock_record:指向栈中锁记录的指针。ptr_to_heavyweight_monitor:指向管程Monitor的指针。
64位标记字段详情
|------------------------------------------------------------------------------|--------------------|
| Mark Word (64 bits) | State |
|------------------------------------------------------------------------------|--------------------|
| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | Normal |
|------------------------------------------------------------------------------|--------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | Biased |
|------------------------------------------------------------------------------|--------------------|
| ptr_to_lock_record:62 | lock:2 | Lightweight Locked |
|------------------------------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:62 | lock:2 | Heavyweight Locked |
|------------------------------------------------------------------------------|--------------------|
| | lock:2 | Marked for GC |
|------------------------------------------------------------------------------|--------------------|
类型指针(Klass Word)
类型指针指向对象的类元数据,虚拟机通过这个指针确定该对象是哪个类的实例。
这一部分用于存储对象的类型指针,该指针指向它的类元数据, JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为 JVM的一个字大小,即 32位的 JVM为 32位, 64位的 JVM为 64位。
如果应用的对象过多,使用 64位的指针将浪费大量内存,统计而言, 64位的 JVM将会比32位的 JVM多耗费 50%的内存。为了节约内存可以使用选项 +UseCompressedOops开启指针压缩,其中, oop即 ordinary object pointer普通对象指针。开启该选项后,下列指针将压缩至 32位:
- 每个
Class的属性指针(即静态变量) - 每个对象的属性指针(即对象变量)
- 普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针 JVM不会优化,比如指向 PermGen的 Class对象指针(JDK8中指向元空间的 Class对象指针)、本地变量、堆栈元素、入参、返回值和 NULL指针等。
数组长度(Array Length)
如果对象是一个数组,那么对象头还需要有额外的空间用于存储数组的长度。
这部分数据的长度也随着 JVM架构的不同而不同: 32位的JVM上,长度为 32位; 64位 JVM则为 64位。
64位JVM如果开启 +UseCompressedOops选项, 该区域长度也将由64位压缩至32位。
使用JOL来分析java的对象布局
JOL简介
JOL的全称是 Java Object Layout。是一个用来分析 JVM中 Object布局的小工具。包括 Object在内存中的占用情况,实例对象的引用情况等等。
JOL可以在代码中使用,也可以独立的以命令行中运行。命令行的我这里就不具体介绍了,今天主要讲解怎么在代码中使用 JOL。
使用JOL需要添加 maven依赖:
<dependency>
<groupid>org.openjdk.jol</groupid>
<artifactid>jol-core</artifactid>
<version>0.14</version>
</dependency>
查看分析vm信息
查看 jdk版本
λ java -version
java version "1.8.0_271"
Java(TM) SE Runtime Environment (build 1.8.0_271-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
通过 JOL查看 jvm信息
public class ObjectHeadTest {
public static void main(String[] args) {
//查看字节序
System.out.println(ByteOrder.nativeOrder());
//打印当前jvm信息
System.out.println("======================================");
System.out.println(VM.current().details());
}
}
输出:
LITTLE_ENDIAN
======================================
Running 64-bit HotSpot VM.
Using compressed oop with 3-bit shift.
Using compressed klass with 3-bit shift.
Objects are 8 bytes aligned.
Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
上面的输出中,我们可以看到: Objects are 8 bytes aligned,这意味着所有的对象分配的字节都是8的整数倍。
可以从上面的 LITTLE_ENDIAN发现,内存中字节序使用的是小端模式。
- 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
- 小端字节序:低位字节在前,高位字节在后,即以
0x1122形式储存。
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
查看分析基本类型对象布局
分析String类型
System.out.println(ClassLayout.parseClass(String.class).toPrintable());
输出:
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 char[] String.value N/A
16 4 int String.hash N/A
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
先解释下各个字段的含义
OFFSET是偏移量,也就是到这个字段位置所占用的byte数,SIZE是后面类型的大小,TYPE是Class中定义的类型,DESCRIPTION是类型的描述,VALUE是TYPE在内存中的值。
分析上面的输出,我们可以得出, String类中占用空间的有5部分,第一部分是对象头,占12个字节,第二部分是 char数组,占用4个字节,第三部分是 int表示的 hash值,占4个字节 ,总共20个字节。但是 JVM中对象内存的分配必须是8字节的整数倍,所以要补全4字节,最后 String类的总大小是24字节。
分析Long类型
System.out.println(ClassLayout.parseClass(Long.class).toPrintable());
输出:
java.lang.Long object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 (alignment/padding gap)
16 8 long Long.value N/A
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
可以看到1个 Long对象是占24个字节的,但是其中真正存储 long的 value只占8个字节。
分析Long实例对象
System.out.println(ClassLayout.parseInstance(Long.MAX_VALUE).toPrintable());
输出:
java.lang.Long object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 23 00 f8 (00000101 00100011 00000000 11111000) (-134208763)
12 4 (alignment/padding gap)
16 8 long Long.value 9223372036854775807
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
可以看出,对象实例的布局跟类型差不多
分析数组实例对象
public static void main(String[] args) {
//查看字节序
List<string> arr = Lists.newArrayList();
arr.add("111");
arr.add("222");
System.out.println(ClassLayout.parseInstance(arr).toPrintable());
System.out.println("======================================");
String[] strArr = {"0","1","2","3","4","5","6","7","8","9","10"};
System.out.println(ClassLayout.parseInstance(strArr).toPrintable());
}
</string>
输出:
java.util.ArrayList object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 7e 2f 00 f8 (01111110 00101111 00000000 11111000) (-134205570)
12 4 int AbstractList.modCount 2
16 4 int ArrayList.size 2
20 4 java.lang.Object[] ArrayList.elementData [(object), (object), null, null, null, null, null, null, null, null]
Instance size: 24 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
======================================
[Ljava.lang.String; object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 37 00 f8 (01000011 00110111 00000000 11111000) (-134203581)
12 4 (object header) 0b 00 00 00 (00001011 00000000 00000000 00000000) (11)
16 44 java.lang.String String;.<elements> N/A
60 4 (loss due to the next object alignment)
Instance size: 64 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
</elements>
可以发现 arr是一个对象,对象头长度为 12bits,实例数据长度为 12bits,分别是3个属性,每个字符串为 4bits
数组 strArr是一个列表,对象头长度为 16bits,可以看到最后一个object header的二进制数据为 1011,转换成十进制是 11,实例数据长度为 44bits,每个字符串为 4bits
上面都是字符串 String,所有长度为 4bits,如果改成其他类型,长度也会跟着变动,比如改成Long,就是变成每个 8bits
分析HashMap外部引用
HashMap hashMap= new HashMap();
hashMap.put("flydean","www.flydean.com");
System.out.println(GraphLayout.parseInstance(hashMap).toPrintable());
输出:
java.util.HashMap@7106e68ed object externals:
ADDRESS SIZE TYPE PATH VALUE
76bbcc048 48 java.util.HashMap (object)
76bbcc078 24 java.lang.String .table[14].key (object)
76bbcc090 32 [C .table[14].key.value [f, l, y, d, e, a, n]
76bbcc0b0 24 java.lang.String .table[14].value (object)
76bbcc0c8 48 [C .table[14].value.value [w, w, w, ., f, l, y, d, e, a, n, ., c, o, m]
76bbcc0f8 80 [Ljava.util.HashMap$Node; .table [null, null, null, null, null, null, null, null, null, null, null, null, null, null, (object), null]
76bbcc148 32 java.util.HashMap$Node .table[14] (object)
Addresses are stable after 1 tries.
从结果我们可以看到 HashMap本身是占用 48字节的,它里面又引用了占用 24字节的 key和 value。
使用 JOL可以分析 java类和对象,这个对于我们对 JVM和 java源代码的理解和实现都是非常有帮助的。
查看自定义类与实例的对象布局
public class ObjectHeadTest {
private int intValue = 0;
public Integer intValue2 = 999;
private short s1=256;
private Short s2=new Short("2222");
private long l1=222222222222222L;
private Long l2 = new Long(222222222222222L);
public boolean isT = false;
public Boolean isT2 = true;
public byte b1=-128;
public Byte b2=127;
public char c1='a';
public Character c2 = Character.MAX_VALUE;
private float f1=22.22f;
private Float f2=new Float("222.222");
private double d1=22.222d;
private Double d2 = new Double("2222.2222");
private BigDecimal bigDecimal = BigDecimal.ONE;
private String aa = "asdfasdfasdfasdfds";
public static void main(String[] args) {
ObjectHeadTest object = new ObjectHeadTest();
//打印hashcode
System.out.println(object.hashCode());
//打印hashcode二进制
System.out.println(Integer.toBinaryString(object.hashCode()));
//打印hashcode十六进制
System.out.println(Integer.toHexString(object.hashCode()));
//查看字节序
System.out.println("======================================");
System.out.println(ClassLayout.parseClass(ObjectHeadTest.class).toPrintable());
System.out.println("======================================");
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
输出:
396873410
10111101001111100111011000010
17a7cec2
======================================
com.qhong.basic.jol.ObjectHeadTest object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int ObjectHeadTest.intValue N/A
16 8 long ObjectHeadTest.l1 N/A
24 8 double ObjectHeadTest.d1 N/A
32 4 float ObjectHeadTest.f1 N/A
36 2 short ObjectHeadTest.s1 N/A
38 2 char ObjectHeadTest.c1 N/A
40 1 boolean ObjectHeadTest.isT N/A
41 1 byte ObjectHeadTest.b1 N/A
42 2 (alignment/padding gap)
44 4 java.lang.Integer ObjectHeadTest.intValue2 N/A
48 4 java.lang.Short ObjectHeadTest.s2 N/A
52 4 java.lang.Long ObjectHeadTest.l2 N/A
56 4 java.lang.Boolean ObjectHeadTest.isT2 N/A
60 4 java.lang.Byte ObjectHeadTest.b2 N/A
64 4 java.lang.Character ObjectHeadTest.c2 N/A
68 4 java.lang.Float ObjectHeadTest.f2 N/A
72 4 java.lang.Double ObjectHeadTest.d2 N/A
76 4 java.math.BigDecimal ObjectHeadTest.bigDecimal N/A
80 4 java.lang.String ObjectHeadTest.aa N/A
84 4 (loss due to the next object alignment)
Instance size: 88 bytes
Space losses: 2 bytes internal + 4 bytes external = 6 bytes total
======================================
com.qhong.basic.jol.ObjectHeadTest object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 c2 ce a7 (00000001 11000010 11001110 10100111) (-1479622143)
4 4 (object header) 17 00 00 00 (00010111 00000000 00000000 00000000) (23)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 int ObjectHeadTest.intValue 0
16 8 long ObjectHeadTest.l1 222222222222222
24 8 double ObjectHeadTest.d1 22.222
32 4 float ObjectHeadTest.f1 22.22
36 2 short ObjectHeadTest.s1 256
38 2 char ObjectHeadTest.c1 a
40 1 boolean ObjectHeadTest.isT false
41 1 byte ObjectHeadTest.b1 -128
42 2 (alignment/padding gap)
44 4 java.lang.Integer ObjectHeadTest.intValue2 999
48 4 java.lang.Short ObjectHeadTest.s2 2222
52 4 java.lang.Long ObjectHeadTest.l2 222222222222222
56 4 java.lang.Boolean ObjectHeadTest.isT2 true
60 4 java.lang.Byte ObjectHeadTest.b2 127
64 4 java.lang.Character ObjectHeadTest.c2 �
68 4 java.lang.Float ObjectHeadTest.f2 222.222
72 4 java.lang.Double ObjectHeadTest.d2 2222.2222
76 4 java.math.BigDecimal ObjectHeadTest.bigDecimal (object)
80 4 java.lang.String ObjectHeadTest.aa (object)
84 4 (loss due to the next object alignment)
Instance size: 88 bytes
Space losses: 2 bytes internal + 4 bytes external = 6 bytes total
分析对象头
从上面的 vm信息可以得出,该内存中的字节序为小端模式
hashcode的二进制位 10111101001111100111011000010
拆分开来应该是 10111 10100111 11001110 11000010
转换成 16进制 17 a7 ce c2
64位的 Mark Word中的布局为
unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2
按上述的展示为:
00 00 00 | 17 a7 ce c2| 01
反过来就是
01 | c2 ce a7 17 | 00 00 00
Synchronized三种锁
Java对象的锁状态一共有四种,级别从低到高依次为: 无锁(01) -> 偏向锁(01) -> 轻量级锁(00) -> 重量级锁(10).
但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级。
JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过 -XX:-UseBiasedLocking来禁用偏向锁。
要注意锁的升级目的是为了 提高锁的获取效率和释放效率。
偏向锁
引入偏向锁的主要原因是,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁(会涉及到一些 CAS操作,耗时)的代价而引入偏向锁。
引入的主要目的是,为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径。因为 轻量级锁的获取及释放依赖多次CAS原子指令,而 偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的 CAS原子指令的性能消耗)。
偏向锁的核心思想是,如果一个线程获得了锁,那么锁就进入偏向模式,此时 Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提升程序的性能。所以,对于没有锁竞争的场合,偏向锁有很好的优化效果,毕竟极有可能连续多次是同一个线程申请相同的锁。
但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
获取锁
- 检测
Mark Word是否为可偏向状态,即是否为偏向锁1,锁标识位为01; - 若为可偏向状态,则测试线程
ID是否为当前线程ID,如果是,则执行步骤(5),否则执行步骤(3); - 如果线程
ID不为当前线程ID,则 通过CAS操作竞争锁,替换ThreadID,竞争成功,则将Mark Word的线程ID替换为当前线程ID,否则执行线程(4); - 通过
CAS竞争锁失败,证明当前存在多线程竞争情况,尝试撤销偏向锁,当到达全局安全点,获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码块; - 执行同步代码块
释放锁
偏向锁的释放采用了一种只有竞争才会释放锁的机制,线程是不会主动去释放偏向锁,需要等待其他线程来竞争。偏向锁的撤销需要等待 全局安全点(这个时间点是上没有正在执行的代码)。其步骤如下:
- 暂停拥有偏向锁的线程,判断锁对象是否还处于被锁定状态;
- 撤销偏向锁,恢复到 无锁状态(01)或者轻量级锁(00)的状态;如果获得偏向锁的线程未活动或已退出同步代码块,直接将锁对象头设置为无锁状态如果为未退出同步代码块,就将获取偏向锁的线程挂起,偏向锁升级为轻量级锁,然后被挂起的线程再继续执行代码块.
那么轻量级锁和偏向锁的使用场景为:
轻量级锁是为了在 线程交替执行同步块时提高性能,
偏向锁则是在 只有一个线程执行同步块时进一步提高性能。
偏向锁流程图

偏向锁只在置换Thread ID的时候依赖了一次CAS原子指令,线程的进入,退出都不再通过CAS来加锁解锁
流程代码
if (锁的标记位 == 01) {
if (偏向标记是1){
是偏向锁且可偏向
boolean CAS操作结果 = CAS操作替换偏向线程的ID为当前线程
if ( CAS操作结果 == 成功){
当前线程获得锁
执行同步代码块
} else {
CAS操作失败
开始【偏向锁的撤销】{
等到全局安全点
var 状态 = 检查原来持有锁的线程的状态
if (状态 == terminated || 已经退出同步代码区)
原线程释放锁
当前线程获得锁
else if (状态 == runnable && 未退出同步代码区){
执行【偏向锁膨胀到轻量级锁】的过程{
原持有锁的线程栈幁分配锁记录、替换MarkWord并指向对象地址、执行同步代码块、CAS操作释放锁
当前线程执行轻量级锁的抢锁过程{
CAS自旋
if (自旋一定次数还没有获取锁){
膨胀到重量级锁
}
}
}
}
}
}
}else {
goto line 4 执行CAS操作
}
}else {
不是偏向锁
}
轻量级锁
引入轻量级锁的主要原因是,对绝大部分的锁,在整个同步周期内都不存在竞争,可能是交替获取锁然后执行。(与偏向锁的区别是,引入偏向锁是假设同一个锁都是由同一线程多次获得,而轻量级锁是假设同一个锁是由n个线程交替获得;相同点是都是假设不存在多线程竞争)
引入轻量级锁的主要目的是,在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗(多指时间消耗)。
触发轻量级锁的条件是 当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,此时 Mark Word的结构也变为轻量级锁的结构。 如果存在多个线程同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。
获取锁
- 判断当前对象是否处于无锁状态
(hashcode、0、01),若是,则JVM首先将在当前线程的 栈帧中建立一个名为锁记录 (Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝(官方把这份拷贝加了一个Displaced前缀,即 Displaced Mark Word);否则执行步骤(3); JVM利用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,,并将Lock Record里的owner指针指向对象的Mark Word。如果成功表示竞争到锁,则将锁标志位变成00(表示此对象处于轻量级锁状态),执行同步操作;如果失败则执行步骤(3);- 判断当前对象的
Mark Word是否指向当前线程的栈帧,如果是则表示当前线程已经持有当前对象的锁,则直接执行同步代码块;否则自旋尝试获取,自旋到一定的次数,只能说明该锁对象已经被其他线程抢占了,这时轻量级锁需要膨胀为重量级锁,锁标志位变成10,后面等待的线程将会进入阻塞状态;
释放锁
轻量级锁的释放也是通过 CAS操作来进行的,主要步骤如下:
-
使用
CAS将锁对象头的Mark Word替换为线程 栈帧中复制的Lock Record. -
替换成功,线程离开同步代码块
- 替换失败,说明有其他线程尝试获取该锁,锁已经膨胀为重量级锁,同时唤醒
Monitor entry set中被挂起的线程。
轻量级锁流程图
获取锁:

释放锁:
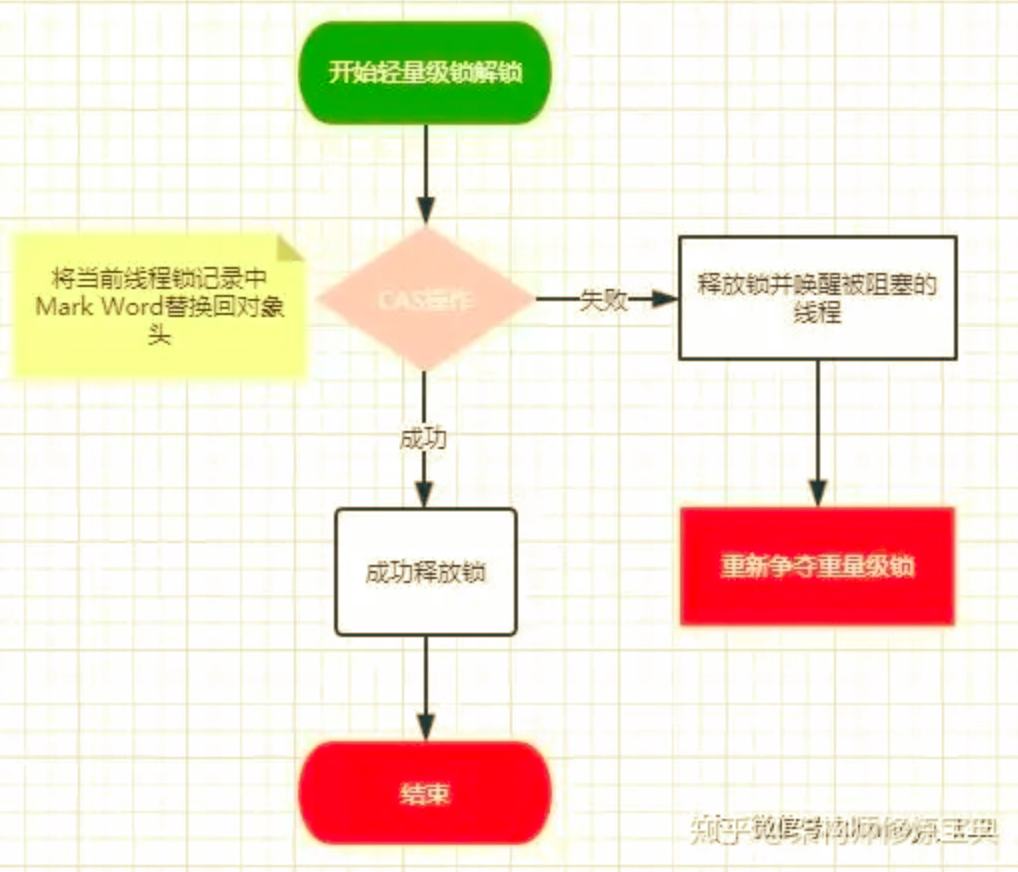
当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁.
流程代码
if (锁的标记位 == 00) {
是轻量级锁
执行轻量级锁的抢占{
当前线程的栈幁中 分配 【锁记录】,【锁记录】由两个部分构成,【displaced Markword】 和 【onwer指针】
把锁对象的【对象头】中的【Markword】拷贝到锁记录中的【displaced Markword】中
onwer指针 指向 该锁对象
CAS修改锁对象的对象头,使其中的【指向线程锁记录的指针】 这一字段指向当前线程
if (CAS操作成功){
当前线程持有锁
}else{
CAS操作失败
CAS自旋
if (自旋超过一定次数还没有成功){
升级为重量级锁{
改变Markword
挂起当前线程
}
}
}
}
}else {
不是轻量级锁
}
重量级锁
重量级锁依赖对象内部的 monitor锁来实现,而 monitor又依赖操作系统的 MutexLock(互斥锁)
Mutex变量的值为 1,表示互斥锁空闲,这个时候某个线程调用lock可以获得锁,而 Mutex的值为 0表示互斥锁已经被其他线程获得,其他线程调用 lock只能挂起等待
获取锁时,锁对象的 Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。
我们经常看见的 synchronized就是非常典型的重量级锁,通过指令 moniter enter 加锁, moniter exit解锁。
为什么重量级锁开销比较大
原因是当系统检查到是重量级锁之后,会把等待想要获取锁的线程阻塞,被阻塞的线程不会消耗 CPU,但是阻塞或者唤醒一个线程,都需要通过操作系统来实现,也就是相当于从用户态转化到内核态,而转化状态是需要消耗时间的
内置锁(ObjectMonitor)
Monitor可以理解为一个同步工具或一种同步机制,通常被描述为一个对象。每一个 Java对象就有一把看不见的锁,称为内部锁或者 Monitor锁。
通常所说的对象的内置锁,是对象头 Mark Word中的重量级锁指针指向的 monitor对象,该对象是在 HotSpot底层 C++语言编写的(openjdk里面看),简单看一下代码:
//结构体如下
ObjectMonitor::ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; //线程的重入次数
_object = NULL;
_owner = NULL; //标识拥有该monitor的线程
_WaitSet = NULL; //等待线程组成的双向循环链表,_WaitSet是第一个节点
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; //多线程竞争锁进入时的单向链表
FreeNext = NULL ;
_EntryList = NULL ; //_owner从该双向循环链表中唤醒线程结点,_EntryList是第一个节点
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
ObjectMonitor队列之间的关系转换可以用下图表示:
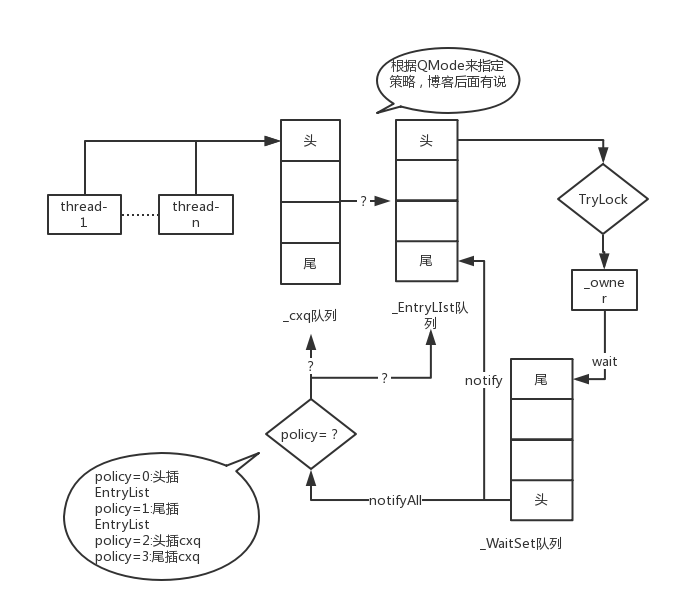
对象内置锁ObjectMonitor流程 :
- 所有期待获得锁的线程,在锁已经被其它线程拥有的时候,这些期待获得锁的线程就进入了对象锁的
entry set区域。 - 所有曾经获得过锁,但是由于其它必要条件不满足而需要
wait的时候,线程就进入了对象锁的wait set区域 。 - 在
wait set区域的线程获得Notify/notifyAll通知的时候,随机的一个Thread(Notify)或者是全部的Thread(NotifyALL)从对象锁的wait set区域进入了entry set中。 - 在当前拥有锁的线程释放掉锁的时候,处于该对象锁的
entryset区域的线程都会抢占该锁,但是只能有任意的一个Thread能取得该锁,而其他线程依然在entry set中等待下次来抢占到锁之后再执行。
既然提到了 _waitSet和 _EntryList(_cxq队列后面会说),那就看一下底层的 wait和 notify方法
wait方法的实现过程:
//1.调用ObjectSynchronizer::wait方法
void ObjectSynchronizer::wait(Handle obj, jlong millis, TRAPS) {
/*省略 */
//2.获得Object的monitor对象(即内置锁)
ObjectMonitor* monitor = ObjectSynchronizer::inflate(THREAD, obj());
DTRACE_MONITOR_WAIT_PROBE(monitor, obj(), THREAD, millis);
//3.调用monitor的wait方法
monitor->wait(millis, true, THREAD);
/*省略*/
}
//4.在wait方法中调用addWaiter方法
inline void ObjectMonitor::AddWaiter(ObjectWaiter* node) {
/*省略*/
if (_WaitSet == NULL) {
//_WaitSet为null,就初始化_waitSet
_WaitSet = node;
node->_prev = node;
node->_next = node;
} else {
//否则就尾插
ObjectWaiter* head = _WaitSet ;
ObjectWaiter* tail = head->_prev;
assert(tail->_next == head, "invariant check");
tail->_next = node;
head->_prev = node;
node->_next = head;
node->_prev = tail;
}
}
//5.然后在ObjectMonitor::exit释放锁,接着 thread_ParkEvent->park 也就是wait
总结:通过object获得内置锁(objectMonitor),通过内置锁将Thread封装成OjectWaiter对象,然后addWaiter将它插入以_waitSet为首结点的等待线程链表中去,最后释放锁。
notify方法的底层实现
//1.调用ObjectSynchronizer::notify方法
void ObjectSynchronizer::notify(Handle obj, TRAPS) {
/*省略*/
//2.调用ObjectSynchronizer::inflate方法
ObjectSynchronizer::inflate(THREAD, obj())->notify(THREAD);
}
//3.通过inflate方法得到ObjectMonitor对象
ObjectMonitor * ATTR ObjectSynchronizer::inflate (Thread * Self, oop object) {
/*省略*/
if (mark->has_monitor()) {
ObjectMonitor * inf = mark->monitor() ;
assert (inf->header()->is_neutral(), "invariant");
assert (inf->object() == object, "invariant") ;
assert (ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is inva;lid");
return inf
}
/*省略*/
}
//4.调用ObjectMonitor的notify方法
void ObjectMonitor::notify(TRAPS) {
/*省略*/
//5.调用DequeueWaiter方法移出_waiterSet第一个结点
ObjectWaiter * iterator = DequeueWaiter() ;
//6.后面省略是将上面DequeueWaiter尾插入_EntrySet的操作
/**省略*/
}
总结:通过 object获得内置锁 (objectMonitor),调用内置锁的 notify方法,通过 _waitset结点移出等待链表中的首结点,将它置于_ EntrySet中去,等待获取锁。注意: notifyAll根据 policy不同可能移入_ EntryList或者 _cxq队列中,此处不详谈。
JVM中对锁的优化
jdk1.6对锁的实现引入了大量的优化,如 自旋锁、 适应性自旋锁、 锁消除、 锁粗化、 偏向锁、 轻量级锁等技术来减少锁操作的开销。
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
自旋锁
线程的阻塞和唤醒需要 CPU 从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁。
何谓自旋锁?
所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放锁。怎么等待呢?执行一段无意义的循环即可(自旋)。
自旋等待不能替代阻塞,虽然它可以避免线程切换带来的开销,但是它占用了处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。所以说,自旋等待的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
自旋锁在 JDK 1.4.2中引入,默认关闭,但是可以使用 -XX:+UseSpinning开开启,在 JDK1.6中默认开启。同时自旋的默认次数为 10次,可以通过参数 -XX:PreBlockSpin来调整;
如果通过参数 -XX:preBlockSpin来调整自旋锁的自旋次数,会带来诸多不便。假如我将参数调整为 10,但是系统很多线程都是等你刚刚退出的时候就释放了锁(假如你多自旋一两次就可以获取锁),你是不是很尴尬。于是 JDK1.6引入自适应的自旋锁,让虚拟机会变得越来越聪明。
自适应自旋锁
JDK 1.6引入了更加聪明的自旋锁,即自适应自旋锁。
所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在 同一个锁上的自旋时间及锁的拥有者的状态来决定。它怎么做呢?
线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
锁消除
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下, JVM 检测到不可能存在共享数据竞争,这是 JVM 会对这些同步锁进行锁消除。锁消除的依据是逃逸分析的数据支持。
如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是对于我们程序员来说这还不清楚么?我们会在明明知道不存在数据竞争的代码块前加上同步吗?但是有时候程序并不是我们所想的那样?我们虽然没有显示使用锁,但是我们在使用一些 JDK的内置 API时,如 StringBuffer、 Vector、 HashTable等,这个时候会存在隐形的加锁操作。比如 StringBuffer的 append()方法, Vector的 add()方法:
public void vectorTest(){
Vector<string> vector = new Vector<string>();
for(int i = 0 ; i < 10 ; i++){
vector.add(i + "");
}
System.out.println(vector);
}
</string></string>
在运行这段代码时, JVM可以明显检测到变量 vector没有逃逸出方法 vectorTest()之外,所以 JVM可以大胆地将 vector内部的加锁操作消除。
锁粗化
我们知道在使用同步锁的时候,需要让同步块的作用范围尽可能小—仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
在大多数的情况下,上述观点是正确的。但是如果一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,所以引入锁粗话的概念。
锁粗话概念比较好理解,就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。如上面实例: vector每次 add的时候都需要加锁操作, JVM检测到对同一个对象( vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到 for循环之外。
synchronized原理图

问题
java8中,偏向锁可以绕过轻量级锁,直接升级到重量级锁吗?
Java 8 中的偏向锁依然不能绕过轻量级锁,直接升级到重量级锁。
在 Java 8 中,对象锁的状态和 Java 5/6/7 中基本保持不变,都有无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。当一个线程第一次访问一个对象时,它会自动获得偏向锁。如果其他线程也想访问这个对象,那么偏向锁就会升级为轻量级锁。如果轻量级锁失败(比如竞争激烈),那么锁就会升级为重量级锁。
Java 8 中对偏向锁的优化主要是针对偏向锁的撤销机制。在 Java 5/6/7 中,当有其他线程尝试获取偏向锁时,会立即撤销偏向锁,并升级为轻量级锁。这种撤销机制会造成一定的性能开销。而在 Java 8 中,当有其他线程尝试获取偏向锁时,并不会立即撤销偏向锁,而是先让这个线程自旋几次,看看能否获取偏向锁。如果自旋成功,则继续使用偏向锁;如果自旋失败,则再进行撤销和升级的操作。这种优化可以减少撤销和升级的操作,从而提高性能。
总之, Java 8 中的偏向锁依然不能绕过轻量级锁,直接升级到重量级锁,但是对于偏向锁的撤销机制进行了优化,减少了性能开销。
参考
终于我用JOL打破了你对java对象的所有想象 | 程序那些事
死磕 Java 并发 – 深入分析 synchronized 的实现原理
Original: https://www.cnblogs.com/hongdada/p/14087177.html
Author: hongdada
Title: JAVA 对象头分析及Synchronized锁
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/537481/
转载文章受原作者版权保护。转载请注明原作者出处!