

在jdk1.5+的环境下,如下4条语句,讨论互相==比较的输出结果
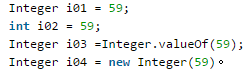


int i02=59; // 这是一个基本类型,存储在栈中。
Integer i01=59; // 调用 Integer 的 valueOf 方法,自动装箱。使用享元模式,看值是否在 [-128,127],且 IntegerCache 中是否存在此对象,如果存在,则直接返回引用,否则创建一个新的对象。因程序初次运行,没有 59 ,所以直接创建了一个新的对象
Integer i03 =Integer.valueOf(59); // 因为 IntegerCache 中已经存在此对象,所以,直接返回引用。
Integer i04 = new Integer(59) ; // 直接创建一个新的对象。
System. out .println(i01== i02); // i01 是 Integer 对象, i02 是 int ,这里比较的不是地址,而是值。 Integer 会自动拆箱成 int ,然后进行值的比较。所以为真。
System. out .println(i01== i03); // 因为 i03 返回的是 i01 的引用,所以,为真。
System. out .println(i03==i04); // 因为 i04 是重新创建的对象,所以 i03,i04 是指向不同的对象,因此比较结果为假。
System. out .println(i02== i04); // 因为 i02 是基本类型,所以此时 i04 会自动拆箱,进行值比较,所以,结果为真。
解析
具体参考:
用命令行: java xxx a b c 方式运行以下代码的结果是?
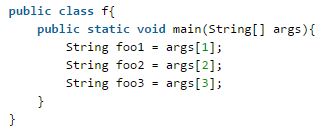
这里java xxx a b c 表示运行java字节码文件xxx,参数为 a b c,因为只输入了三个参数,且args是数组下标从0开始,而程序中使用到agrs[3]显然数组越界。抛出数组越界异常。
解析
下面代码的输出结果是?
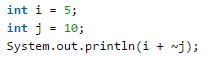
需要知道计算机用补码存储数值
10的原码:0000 0000 | 0000 0000 | 0000 0000 | 00001010
~10: 1111111111111111,1111111111110101 变为负数,下面求该负数的补码:
~10反码:10000000000000000,0000000000001010 符号位不变,其余位取反
~10补码:10000000000000000,0000000000001011,等于 -11
下面记住公式
-n=~n+1可推出 ~n = -n-1
解析
下面代码的输出结果是?
System.out.println(2.00 - 1.10);
可能认为该程序打印0.90,但是编译器如何才能知道你想要打印小数点后两位小数呢?
实际它打印的是0.8999999999999999。问题在于1.1 这个数字不能被精确表示成为一个double,因此它被表示成为最接近它的double 值。该程序从2 中减去的就是这个值。更一般地说,问题在于并不是所有的小数都可以用二进制浮点数来精确表示的。如果你正在用的是JDK 5.0 或更新的版本,那么可以使用类似c的方式,Java的printf 工具来订正该程序:
System.out.printf("%.2f%n",2.00 - 1.10);
这条语句打印的是正确的结果,但是这并不表示它就是对底层问题的通用解决方案:它使用的仍旧是二进制浮点数的double 运算。浮点运算在一个范围很广的值域上提供了很好的近似,但是它通常不能产生精确的结果。二进制浮点对于货币计算是非常不适合的,因为它不可能将0.1,或者10的其它任何次负幂精确表示为一个长度有限的二进制小数。
解决该问题的一种方式是使用某种整数类型,例如int 或long,并且以分为单位来执行计算。注意这样做请确保该整数类型大到足够表示在程序中你将要用到的所有值。对本题int 就足够了。下面是用int 以分为单位表示货币值后重写的println 语句:
System.out.println((200 - 110) + "cents");
解决该问题的另一种方式是使用执行精确小数运算的BigDecimal工具类。它还可以通过 JDBC 与 SQL DECIMAL 类型进行互操作。这里要注意: 一定要用 BigDecimal(String) 构造器,而不用BigDecimal(double)。后一个构造器将用它的参数的"精确"值来创建一个实例:new BigDecimal(.1)将返回一个表示0.100000000000000055511151231257827021181583404541015625 的BigDecimal。通过正确使用BigDecimal,程序就可以打印出我们所期望的结果0.90:
import java.math.BigDecimal;
public class Change1{
public static void main(String args[]){
System.out.println(new BigDecimal("2.00").subtract(new BigDecimal("1.10")));
}
}
这个版本并不是十分地完美,因为Java 并没有为BigDecimal 提供任何语言上的支持。使用BigDecimal 的计算很有可能比那些使用原始类型的计算要慢一些,对某些大量使用小数计算的程序来说,这可能会成为问题。总之, 在需要精确答案的地方,要避免使用float 和double,对于货币计算,要使用int、long 或BigDecimal。
解析
浮点数表示可以参考
下面代码的输出结果是?
final long MICROS_PER_DAY = 24 * 60 * 60 * 1000 * 1000;
final long MILLIS_PER_DAY = 24 * 60 * 60 * 1000;
System.out.println(MICROS_PER_DAY / MILLIS_PER_DAY);
除数和被除数都是long 类型的,long 类型大到了可以很容易地保存这两个乘积而不产生溢出。因此,看起来程序打印的必定是1000。
问题在于常数 MICROS_PER_DAY 的计算"确实"溢出了。尽管计算的结果能安全放入long 中,并且其空间还有富余,但是这个结果并不适合放入int 中。这个计算完全是以int 运算来执行的,并且只有在运算完成之后,其结果才被提升到long,而此时已经太迟了,计算已经溢出。
从int提升到long是一种拓宽原始类型转换(widening primitive conversion),它保留了(不正确的)数值。这个值之后被MILLIS_PER_DAY 整除,而MILLIS_PER_DAY 的计算是正确的,因为它适合int 运算。这样整除的结果就得到了5(前者返回的是一个小了200 倍的数值)。
那么为什么计算会是以int运算来执行的呢?
因为所有乘在一起的因子都是默认int数值。将两个int 数值相乘时,将得到另一个int 数值,这是Java 的语言特性,通过使用long 常量来替代int 常量作为每一个乘积的第一个因子,我们就可以修改这个程序。这样做可以强制表达式中所有的后续计算都用long 来完成。尽管这么做只在MICROS_PER_DAY 表达式中是必需的,但是在两个乘积中都这么做是一种很好的方式。相似地使用long 作为乘积的"第一个"数值也并不总是必需的,但是这么做也是一种很好的形式。在两个计算中都以long数值开始可以很清楚地表明它们都不会溢出。下面的程序将打印1000:
final long MICROS_PER_DAY = 24L * 60 * 60 * 1000 * 1000;
final long MILLIS_PER_DAY = 24L * 60 * 60 * 1000;
System.out.println(MICROS_PER_DAY/MILLIS_PER_DAY);
小结:当操作很大的数字时,千万要提防溢出。即使用来保存结果的变量已显得足够大,也并不意味着要产生结果的计算具有正确的类型。当拿不准时,就使用long 运算来执行整个计算。
解析
下面代码的输出结果是?
System.out.println(12345 + 5432l);
表面上看,这是一个很简单的题,打印66666。
实际上,当运行该程序时,它打印的是17777。仔细看 + 操作符的两个操作数,我们是将一个int 类型的12345 加到了 long 类型的5432l 上。请注意左操作数开头的数字1 和右操作数结尾的小写字母l 之间的细微差异。数字1 的水平笔划 和 垂直笔划 之间是一个锐角,而与此相对照的是,小写字母 l 是一个直角。
这个写法确实已经引起了混乱,这里有一个教训:在 long 型字面常量中,一定要用大写的L,千万不要用小写的l。这样就可以完全避免混乱。
System.out.println(12345 + 5432L);
类似的,要避免使用单独的一个 l 字母作为变量名。因为很难通过观察来判断它到底是 l 还是数字 1。属于编程不规范。
System.out.println(1);
总之,小写字母 l 和数字1 在大多数字体中几乎是一样的。为避免程序的读者对二者产生混淆,千万不要使用小写的 l 来作为 long 型字面常量的结尾或是作为变量名。Java 从C 编程语言中继承良多,包括long 型字面常量的语法。也许当初允许用小写的 l 来编写long 型字面常量本身就是一个错误。
解析
下面代码的输出结果是?
System.out.println(Long.toHexString(0x100000000L + 0xcafebabe));
`
看起来应该打印1cafebabe。毕竟这是十六进制数字10000000016 与cafebabe16 的和。该程序使用的是long 型运算,它可以支持16位十六进制数,因此运算溢出是不可能的。
然而,运行该程序,发现它打印出来的是cafebabe,并没有任何前导的1。这个输出表示的是正确结果的低32 位,但是不知何故,第33 位丢失了。看起来程序好像执行的是int 型运算而不是long 型运算。
注意:十进制字面常量具有一个很好的属性,即所有的十进制字面常量都是正的,而十六进制或是八进制字面常量并不具备这个属性。要想书写一个负的十进制常量,可以使用一元取反操作符(-减号)连接一个十进制字面常量。以这种方式,十进制书写任何int 或long 型的数值,不管它是正的还是负的,并且负的十进制常数可以很明确地用一个减号符号来标识。
十六进制和八进制字面常量并不是这么回事,它们可以具有正的以及负的数值。如果十六进制和八进制字面常量的最高位被置位了,那么它们就是负数。在这个程序中,数字0xcafebabe是一个int 常量,它的最高位被置位了,所以它是一个负数。它等于十进制数值-889275714。
该程序执行的这个加法是一种”混合类型的计算(mixed-type computation):左操作数是long 类型的,而右操作数是int 类型的。为了执行该计算,Java 将int 类型的数值用拓宽原始类型转换提升为一个long 类型,然后对两个long 类型数值相加。因为int 是一个有符号的整数类型,所以它将负的int 类型的数值提升为一个在数值上相等的long 类型数值。这个加法的右操作数0xcafebabe 被提升为了long 类型的数值0xffffffffcafebabeL。这个数值之后被加到了左操作数0x100000000L 上。当作为int 类型来被审视时,经过符号扩展之后的右操作数的高32 位是-1,而左操作数的高32 位是1,将这两个数值相加就得到了0,这也就解释了为什么在程序输出中前导1 丢失了。下面所示是用手写的加法实现。(在加法上面的数字是进位)
1111111
0xf f f f f f f f c a f e b a b eL
+ 0x00000001 0 0 00 0 0 0 0L
ceil: 向上取整数。返回double类型—–vt. 装天花板;
例如:Math.ceil(5.6) = 6.0
Original: https://www.cnblogs.com/kubixuesheng/p/5974404.html
Author: dashuai的博客
Title: Core Java 总结(数据类型,表达式问题)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/537020/
转载文章受原作者版权保护。转载请注明原作者出处!