

ElasticSearch 主要用于大数据量的检索,相比于传统的MySQL、Oracle等结构性数据库,具有较快的响应速度,丰富的查询种类,健全的响应设置,自定义权重等诸多优点
安装ES
参考文档 https://www.elastic.co/guide/en/elasticsearch/reference/7.16/docker.html ,注意,如果遇到容器启动一段时间后闪退这种情况,可能是由于服务器的内存较小或分配给docker容器的内存较小,可以通过 ES_JAVA_OPTS 参数来设置ES容器的最大内存,下面通过 ES_JAVA_OPTS=”-Xms256m -Xmx256m” 限制ES容器的启动内存和最大内存都为256M。
docker network create elastic
docker run -itd --name some-elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms256m -Xmx256m" --name some-elasticsearch elasticsearch:7.16.1
访问http://ip:9200 可以获取版本相关的描述信息说明ES容器正常启动了。
安装Kibana
Kibana是官方提供的对ES的可视化分析界面。
docker run -d --name some-kibana --net elastic -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://some-elasticsearch:9200" kibana:7.16.1
访问http://ip:5601 可以正常进入Kibana,说明kibana容器启动成功。
点击Kibana操作界面中的 Management -> DevTools 进入控制台,进行后续的API测试。

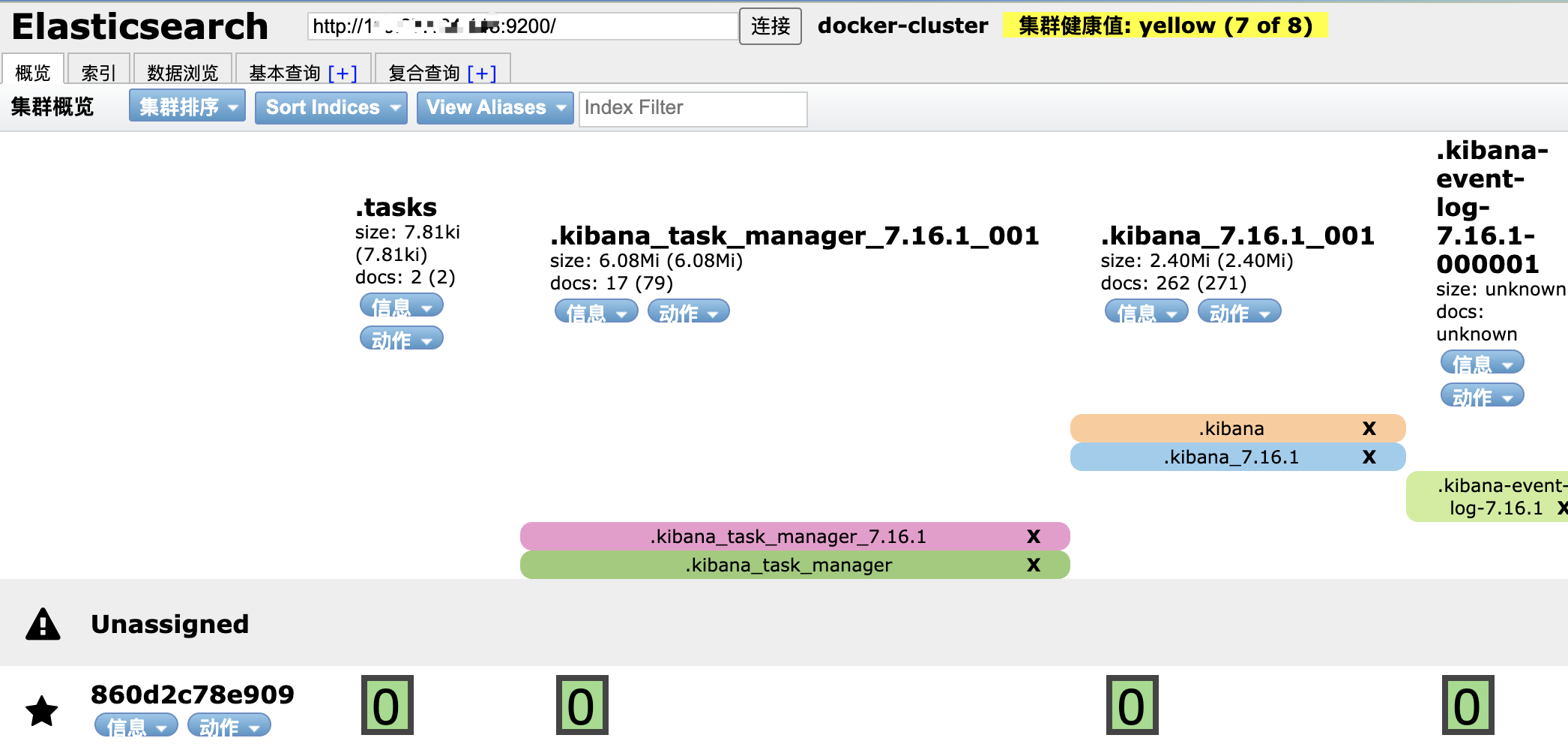
安装Elasticsearch-head
Elasticsearch-head 提供了对ES的可视化操作界面
docker run -d -p 9100:9100 --name some-es-head mobz/elasticsearch-head:5
访问 http://ip:9100 可以正常进入,说明Elasticsearch-head容器启动成功,若访问后提示 集群健康值:未连接,可以进入容器,找到对应的 elasticsearch.yml文件,添加下面两行配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
ElasticSearch 常用REST API
Elasticsearch提供了restful风格的接口,在对ES中的数据进行CRUD时,也可以通过postman、curl这样的接口工具进行调试
获取ES首页的基本信息
GET /
获取索引列表
GET _cat/indices
删除索引,删除名称为blogs的索引
DELETE /blogs
基本查询,查看文档列表,获取文档第一条开始的前20条数据
GET /blogs/_search
{
"query": {
"match_all": {}
},
"size": 20,
"from": 0
}
新增文档,文档对应的索引不存在时会自动创建,文档ID不指定会自动生成,这里也可以用PUT方法
POST /索引名称/_doc/文档ID(不指定时系统自动创建)
POST /blogs/_doc/1
{
"content": "更新字段、更新数据",
"title": "新增测试"
}
修改文档,和新增文档操作类似,只需要带上文档ID,就可以修改文档的字段和内容
POST /索引名称/_doc/文档ID
我们可以把上面新增时候的content字段去掉,并修改title的值
POST /blogs/_doc/1
{
"title": "修改测试"
}
根据文档ID进行搜索,在blogs索引中查询ID为1的文档
GET /blogs/_doc/1
删除文档,删除ID为1的文档
DELETE /blogs/_doc/1
文档查询,返回的数据只包含 特定字段,查询blogs索引中的文档数据,并返回文档中对应的 title
GET /blogs/_search
{
"query": {
"match_all": {}
},
"_source": ["title"]
}
文档查询,根据文档中的 字段进行搜索,并返回 高亮的数据,默认被高亮的词是通过 em 标签括起来的,Elasticsearch可以支持自定义高亮的标签,比如下面通过 h1 来定义整个返回字段的高亮情况。
GET /blogs/_search
{
"query": {
"match": {
"title": "新增"
}
},
"highlight": {
"fields": {
"title": {}
},
"pre_tags": [""],
"post_tags": [""]
}
}
Java Client
ES支持Java、Go、PHP等,客户端列表查看https://www.elastic.co/guide/en/elasticsearch/client/index.html ,本文使用的es客户端版本为
7.12.1参考文档 https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/7.12/index.html
在pom.xml中新增ES和json的相关依赖
org.elasticsearch
elasticsearch
7.12.1
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.12.1
通过以下单元测试可以对elasticsearch中的索引、文档进行CURD的操作,也可以通过远程调用的方法来实现对Elasticsearch的操作。
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.RequestLine;
import org.apache.http.util.EntityUtils;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.*;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Function;
public class ElasticSearch {
/**
* 无参请求,针对不同请求修改 Request中的请求方法、endpoint
* 可根据文档的ID进行搜索、支持文档删除
* @throws IOException
*/
@Test
public void requestNoArgs() throws IOException {
RestHighLevelClient highLevelClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
Request request = new Request("GET", "_cat/indices"); // 获取索引列表
Response response = highLevelClient.getLowLevelClient().performRequest(request);
System.out.println("==================================");
System.out.println(EntityUtils.toString(response.getEntity()));
System.out.println("==================================");
highLevelClient.close();
}
/**
* 文档新增、修改
* @throws IOException
*/
@Test
public void docAddOrUpdate() throws IOException {
RestHighLevelClient highLevelClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
IndexRequest request = new IndexRequest("blogs", "_doc", "2"); // 指定ID新增文档
Map map = new HashMap<>();
map.put("title", "title-新增-修改");
request.source(map);
IndexResponse response = highLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println("==================================");
System.out.println(response.toString());
System.out.println("==================================");
highLevelClient.close();
}
/**
* 文档修改、不支持文档新增
* @throws IOException
*/
@Test
public void docUpdate() throws IOException {
RestHighLevelClient highLevelClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
UpdateRequest request = new UpdateRequest("blogs", "1");
Map map = new HashMap<>();
map.put("title", "title");
request.doc(map);
UpdateResponse response = highLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println("==================================");
System.out.println(response.toString());
System.out.println("==================================");
highLevelClient.close();
}
/**
* 文档查询,指定查询条件
* @throws IOException
*/
@Test
public void docQuery() throws IOException {
RestHighLevelClient highLevelClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
// 在sourceBuilder中可以构造高亮、分页等查询条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(3);
// searchRequest()
SearchRequest request = new SearchRequest("blogs");
request.source(sourceBuilder);
// search()
SearchResponse response = highLevelClient.search(request, RequestOptions.DEFAULT);
System.out.println("==================================");
System.out.println(response.toString());
System.out.println("==================================");
highLevelClient.close();
}
}
SpringBoot 整合Elasticsearch
springboot启动器中对Elasticsearch进行了封装可以快速使用,核心参考文档:https://docs.spring.io/spring-data/elasticsearch/docs/4.2.5/reference/html 参考文档 2:https://docs.spring.io/spring-boot/docs/2.5.5/reference/htmlsingle/#features.nosql.elasticsearch
在pom.xml中导入相关的maven依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
在application.properties 中配置es的服务地址、账号、密码
spring.elasticsearch.rest.uris=localhost:9200
创建索引的映射对象,这里考虑续用上述的blogs
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Document(indexName = "blogs")
public class Blogs {
@Id
private Integer id;
private String title;
private String content;
@Override
public String toString() {
return "Blogs{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
// 记得添加相应的get set 方法
}
创建测试类,测试索引、文档的相关操作
import cn.getcharzp.pojo.Blogs;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.client.reactive.DefaultReactiveElasticsearchClient;
import org.springframework.data.elasticsearch.core.*;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.Query;
import org.springframework.data.elasticsearch.core.query.UpdateQuery;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.test.context.junit4.SpringRunner;
import java.beans.Statement;
import java.util.AbstractQueue;
@SpringBootTest
@RunWith(SpringRunner.class)
public class SpringbootElasticSearch {
@Autowired
private ElasticsearchRestTemplate template;
/**
* 根据文档ID获取文档详情
*/
@Test
public void getDocById() {
Blogs blogs = template.get("1", Blogs.class);
System.out.println(blogs);
}
/**
* 使用indexOps对指定索引进行创建、判断其是否存在
*/
@Test
public void theIndexOps() {
System.out.println(template.indexOps(Blogs.class).exists()); // 判断索引是否存在
System.out.println(template.indexOps(Blogs.class).create()); // 创建索引,如果索引存在会抛出异常
}
/**
* 使用search查询文档列表
* 通过 NativeSearchQueryBuilder 来指定查询的条件
* 通过 withQuery 来指定查询的条件
* 通过 withHighlightBuilder 来指定文档的高亮
* 通过 withPageable 来指定查询的页数
*/
@Test
public void searchDocs() {
Query query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("title", "xx"))
.withHighlightBuilder(new HighlightBuilder().field("title"))
.withPageable(PageRequest.of(0, 10))
.build();
SearchHits blogs = template.search(query, Blogs.class);
for (SearchHit blog : blogs) {
System.out.println(blog);
}
}
/**
* 通过 save 对文档进行保存和修改
* 指定了ID后就可以对文档进行修改
*/
@Test
public void saveDoc() {
template.save(new Blogs("iGRi030BotkAozMpjg80", "title 3 x修改", "content 3 修改"));
}
/**
* 使用 delete 删除文档
*/
@Test
public void deleteDoc() {
System.out.println(template.delete("1", Blogs.class));
}
}
同时,还支持类似于JPA的方式对文档进行CRUD的操作,只需要继承 ElasticsearchRepository这个接口,详细资料参考文档:https://docs.spring.io/spring-data/elasticsearch/docs/4.2.5/reference/html/#elasticsearch.repositories
Original: https://www.cnblogs.com/GetcharZp/p/15709415.html
Author: GetcharZp
Title: 基于Docker安装ElasticSearch及基本使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/535018/
转载文章受原作者版权保护。转载请注明原作者出处!