

点击上方” 小白学视觉“,选择加” 星标“或” 置顶“
重磅干货,第一时间送达


主成分分析简介
主成分分析(PCA)是一种广泛应用于机器学习的降维技术。PCA 通过对大量变量进行某种变换,将这些变量中的信息压缩为较少的变量。变换的应用方式是将线性相关变量变换为不相关变量。相关性告诉我们存在信息冗余,如果可以减少这种冗余,则可以压缩信息。例如,如果变量集中有两个高度相关的变量,那么通过保留这两个变量我们不会获得任何额外信息,因为一个变量几乎可以表示为另一个的线性组合。在这种情况下,PCA 通过平移和旋转原始轴并将数据投影到新轴上,将第二个变量的方差转移到第一个变量上,使用特征值和特征向量确定投影方向。因此,前几个变换后的特征(称为主成分)信息丰富,而最后一个特征主要包含噪声,其中的信息可以忽略不计。这种可转移性使我们能够保留前几个主成分,从而显著减少变量数量,同时将信息损失降至最低。
本文更多地关注图像数据上的实际逐步 PCA 实现,而不是理论上的解释,因为已经有大量的材料可用于此。选择了图像数据而不是表格数据,以便我们可以通过图像可视化更好地理解 PCA 的工作。从技术上讲,图像是像素矩阵,其亮度表示该像素内表面特征的反射率。对于 8 位整数图像,反射率值的范围为 0 到 255。因此,具有零反射率的像素将显示为黑色,值为 255 的像素显示为纯白色,值介于两者之间的像素显示为灰色调。文章中使用了在印度沿海地区拍摄的 Landsat TM 卫星图像。图像被调整为较小的比例以减少 CPU 上的计算负载。该图像集由在蓝色、绿色、红色、近红外 (NIR) 和中红外 (MIR) 电磁光谱范围内捕获的 7 个波段图像组成。
1.加载模块和图像数据
第一步是导入所需的库并加载数据。为了便于使访问和处理,波段图像被堆叠在大小为 850 x 1100 x 7(高 x 宽 x 波段数)的 3d numpy 阵列中。下面显示的彩色图像是红色、绿色和蓝色 (RGB) 波段图像的合成,再现了与我们所看到的相同的视图。
from IPython.display import Image, display
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import cv2
import numpy as np
Read RGB image into an array
img = cv2.imread('band321.jpg')
img_shape = img.shape[:2]
print('image size = ',img_shape)
specify no of bands in the image
n_bands = 7
3 dimensional dummy array with zeros
MB_img = np.zeros((img_shape[0],img_shape[1],n_bands))
stacking up images into the array
for i in range(n_bands):
MB_img[:,:,i] = cv2.imread('band'+str(i+1)+'.jpg',
cv2.IMREAD_GRAYSCALE)
Let's take a look at scene
print('\n\nDispalying colour image of the scene')
plt.figure(figsize=(img_shape[0]/100,img_shape[1]/100))
plt.imshow(img, vmin=0, vmax=255)
plt.axis('off');
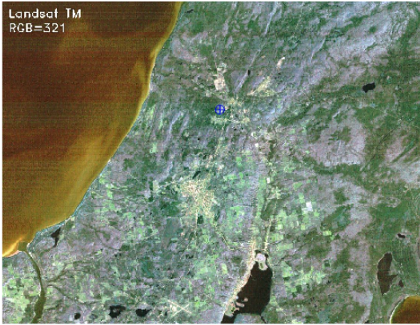
图像场景包括各种地表特征,例如水、建筑面积、森林和农田。
2. 数据探索
让我们看一下不同特征的单个波段图像的反射率,并尝试深入了解波段图像中的特征。
import matplotlib.pyplot as plt
import matplotlib.gridspec as grid
fig,axes = plt.subplots(2,4,figsize=(50,23),sharex='all', sharey='all')
fig.subplots_adjust(wspace=0.1, hspace=0.15)
fig.suptitle('Intensities at Different Bandwidth in the visible and Infra-red spectrum', fontsize=30)
axes = axes.ravel()
for i in range(n_bands):
axes[i].imshow(MB_img[:,:,i],cmap='gray', vmin=0, vmax=255)
axes[i].set_title('band '+str(i+1),fontsize=25)
axes[i].axis('off')
fig.delaxes(axes[-1])

如果我们观察图像,所有波段都捕获了一个或多个表面特征,并且每个特征都在多个波段中被很好地捕获。例如,在波段 2(绿色)和波段 4(近红外)图像中,农田很容易与其他地表特征区分开来,但在其他区域则不易区分。因此,波段之间存在信息冗余,这意味着各波段之间的反射率有一定的相关性,这为我们提供了一个在它们上测试 PCA 的机会。
3. 数据标准化
在应用 PCA 之前,我们必须通过标准化将我们的数据转化为通用格式。这样做的目的是确保变量在内部保持一致,而不管它们的类型如何。例如,如果数据集有两个变量,温度以摄氏度为单位,降雨量以厘米为单位。由于变量范围和单位不同,不建议按原样使用不同的变量,否则数量级不同的变量可能会导致模型对某些变量的偏差。标准化是通过减去均值来使变量居中,然后通过除以标准差使它们达到一个共同的尺度来完成的。由于我们处理的变量(波段图像)相似且具有相同的范围,因此不需要标准化,但仍然可以应用。
我们的变量是图像二维数组,需要转换为一维向量以便于矩阵计算。让我们创建一个大小为 935000 X 7(图像中的像素数 X 波段数)的变量矩阵,并将这些一维向量存储在其中。
Convert 2d band array in 1-d to make them as feature vectors and Standardization
MB_matrix = np.zeros((MB_img[:,:,0].size,n_bands))
for i in range(n_bands):
MB_array = MB_img[:,:,i].flatten() # covert 2d to 1d array
MB_arrayStd = (MB_array - MB_array.mean())/MB_array.std()
MB_matrix[:,i] = MB_arrayStd
MB_matrix.shape;
4. PCA 变换
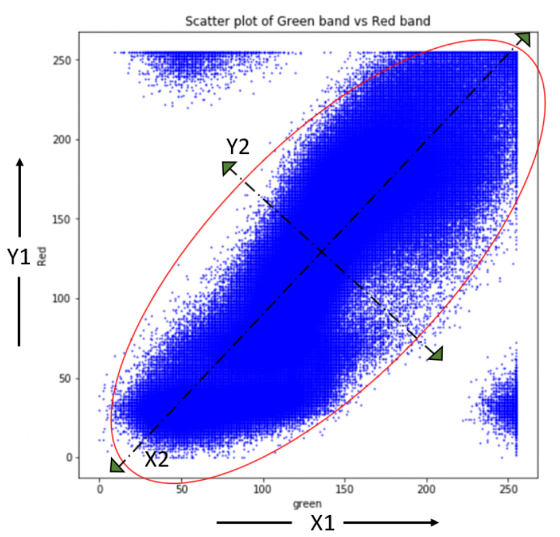
让我们进一步了解 PCA 中发生的轴变换。下面的散点图显示了绿色和红色波段数据之间的相关性。然后使用特征向量确定主分量轴 (X2, Y2),使得沿 X2 方向的方差最大,而与其正交的方向使 Y2 的方差最小。原始轴 (X1, Y1) 现在沿主分量轴 (X2, Y2) 旋转,投影到这些新轴上的数据是主分量。需要注意的是,原始数据中存在的相关性在转换到 (X2, Y2) 空间后被消除,而方差部分从一个变量转移到另一个变量。
5. 特征值和特征向量计算
下一步是计算协方差矩阵的特征向量和对应的特征值
Covariance
np.set_printoptions(precision=3)
cov = np.cov(MB_matrix.transpose())
Eigen Values
EigVal,EigVec = np.linalg.eig(cov)
print("Eigenvalues:\n\n", EigVal,"\n")
特征值:
[5.508 0.796 0.249 0.167 0.088 0.064 0.128]
在这一步中,实现数据压缩和降维。如果我们观察特征值,我们会发现这些值完全不同。这些值为我们提供了特征向量或方向的重要性顺序,即沿着特征向量的轴具有最大的特征值,是最重要的 PC 轴,依此类推。下一步是根据特征值从高到低对特征向量进行排序,按重要性顺序重新排列主成分。我们需要在有序特征向量的方向上转换数据,而有序特征向量又会产生主成分。
Ordering Eigen values and vectors
order = EigVal.argsort()[::-1]
EigVal = EigVal[order]
EigVec = EigVec[:,order]
#Projecting data on Eigen vector directions resulting to Principal Components
PC = np.matmul(MB_matrix,EigVec) #cross product
6. 主成分验证
依赖性检查
我们能够成功地生产主要成分。现在,让我们验证 PC 以检查它们是否能够减少冗余,并检查实现数据压缩的程度。我们将创建散点图来可视化原始波段中的成对关系,并将其与 PC 的成对关系进行比较以测试是否存在依赖性。
Generate Paiplot for original data and transformed PCs
Bandnames = ['Band 1','Band 2','Band 3','Band 4','Band 5','Band 6','Band 7']
a = sns.pairplot(pd.DataFrame(MB_matrix,
columns = Bandnames),
diag_kind='kde',plot_kws={"s": 3})
a.fig.suptitle("Pair plot of Band images")
PCnames = ['PC 1','PC 2','PC 3','PC 4','PC 5','PC 6','PC 7']
b = sns.pairplot(pd.DataFrame(PC,
columns = PCnames),
diag_kind='kde',plot_kws={"s": 3})
b.fig.suptitle("Pair plot of PCs")

波段(左)和 PCs(右)的配对图
让我们看一下配对图,并注意到原始数据中存在的变量之间的相关性在主成分中消失了。因此,PCA 能够显著降低相关性。沿对角线的分布图告诉我们,PCA 也成功地转移了与可压缩性相关的方差。
压缩性检查
#Information Retained by Principal Components
plt.figure(figsize=(8,6))
plt.bar([1,2,3,4,5,6,7],EigVal/sum(EigVal)*100,align='center',width=0.4,
tick_label = ['PC1','PC2','PC3','PC4','PC5','PC6','PC7'])
plt.ylabel('Variance (%)')
plt.title('Information retention');
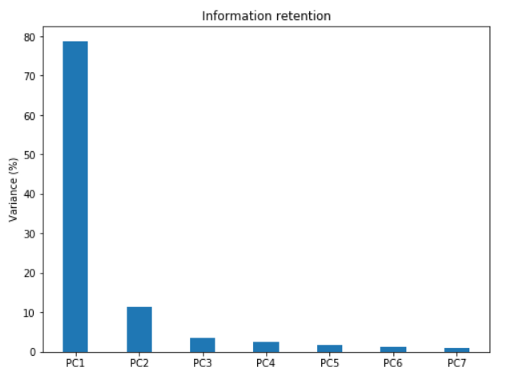
上面绘制的以百分比表示的特征值条形图为我们提供了每个 PC 中保留的信息。请注意,最后一个 PC 的特征值很小且不那么重要,这就是降维的作用所在。如果我们选择保留 93% 信息的前三个相关组件,那么最终数据可以从 7 维减少到 3 维,而不会丢失太多信息。
7. 将 PC 转换回图像
是时候将一维 PC 重塑回原始图像形状并将PCs在 0 到 255 之间进行归一化,这与原始图像范围相同,以使图像可视化成为可能。
Rearranging 1-d arrays to 2-d arrays of image size
PC_2d = np.zeros((img_shape[0],img_shape[1],n_bands))
for i in range(n_bands):
PC_2d[:,:,i] = PC[:,i].reshape(-1,img_shape[1])
normalizing between 0 to 255
PC_2d_Norm = np.zeros((img_shape[0],img_shape[1],n_bands))
for i in range(n_bands):
PC_2d_Norm[:,:,i] = cv2.normalize(PC_2d[:,:,i],
np.zeros(img_shape),0,255 ,cv2.NORM_MINMAX)
让我们直观地确定压缩量。
fig,axes = plt.subplots(2,4,figsize=(50,23),sharex='all',
sharey='all')
fig.subplots_adjust(wspace=0.1, hspace=0.15)
fig.suptitle('Intensities of Principal Components ', fontsize=30)
axes = axes.ravel()
for i in range(n_bands):
axes[i].imshow(PC_2d_Norm[:,:,i],cmap='gray', vmin=0, vmax=255)
axes[i].set_title('PC '+str(i+1),fontsize=25)
axes[i].axis('off')
fig.delaxes(axes[-1])

主成分图像的强度
请注意,前几个 PCs 具有丰富的信息并且很清晰,随着我们接近尾声,PCs 开始丢失信息,而最后几个 PCs 大多包含噪声。我们将保留前三个 PCs 并丢弃其余的。这将有助于通过去除噪声改善数据质量,并通过机器学习算法进行处理,在时间和内存使用方面效率更高。
8. PC 和 RCB 图像比较
Comparsion of RGB and Image produced using first three bands
fig,axes = plt.subplots(1,2,figsize=(50,23),
sharex='all', sharey='all')
fig.subplots_adjust(wspace=0.1, hspace=0.15)
axes[0].imshow(MB_img[:,:,0:3].astype(int))
axes[0].axis('off');
axes[1].imshow(PC_2d_Norm[:,:,:3][:,:,[0,2,1]].astype(int))
axes[1].axis('off');
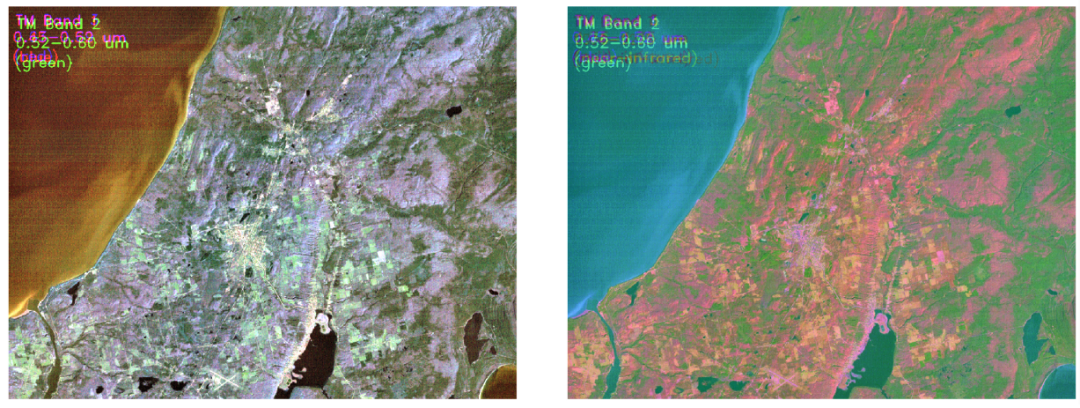
最后,我们使用前三个主成分再现了相同的场景。右边的图像看起来比原始图像 RGB 更丰富多彩,这使得场景中的特征看起来更清晰,更容易区分。例如,由于颜色不同,农田可以更容易地与城市地区区分开来。一些特征在PC图中显得更加图层,而在左侧图像中则难以识别。因此,可以得出结论,PCA 在可压缩性和信息保留方面对我们的图像数据做得很好。
Github代码连接:
https://github.com/Skumarr53/Principal-Component-Analysis-testing-on-Image-data
下载1:OpenCV-Contrib扩展模块中文版教程
在「 小白学视觉」公众号后台回复: 扩展模块中文教程 ,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖 扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「 小白学视觉」公众号后台回复: Python视觉实战项目 ,即可下载包括 图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「 小白学视觉」公众号后台回复: OpenCV实战项目20讲 ,即可下载含有 20个基于 OpenCV实现20个 实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向”,例如:”张三 + 上海交大 + 视觉SLAM”。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。 请勿在群内发送广告,否则会请出群,谢谢理解~


Original: https://blog.csdn.net/qq_42722197/article/details/122315050
Author: 小白学视觉
Title: 主成分分析(PCA):通过图像可视化深入理解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/533545/
转载文章受原作者版权保护。转载请注明原作者出处!