

原文链接:https://arxiv.org/pdf/2003.04092v1.pdf
代码链接:GitHub – ZitongYu/CDCN: Central Difference Convolutional Networks (CVPR’20)
摘要
人脸反欺骗 (FAS) 在人脸识别系统中起着至关重要的作用。大多数SOTA的FAS方法:(1) 依赖于堆叠卷积和特定网络设计,这在描述详细的细粒度信息方面很弱,并且在环境变化时很容易失效;(2) 更喜欢使用长序列作为输入来提取动态特征,这使得它们难以部署到需要快速响应的场景中。因此,作者提出了一种基于中心差分卷积 (CDC) 的新型快速FAS方法,该方法能够通过聚合强度和梯度信息来抓取详细信息。使用 CDC 构建的网络称为中心差分卷积网络 (CDCN),它能够提供更强大的建模能力。此外,在专门设计的 CDC 搜索空间上,利用神经架构搜索 (NAS) 来发现更强大的网络结构 (CDCN++),该网络结构可以与多尺度注意力融合模块 (MAFM) 组合以进一步提高性能。作者在六个基准数据集上进行了综合实验,结果表明:(1) 所提出的方法不仅在数据集内测试上取得了优异的性能;(2) 它在跨数据集上也有很好的泛化能力测试。
引言
人脸识别因其便利性而被广泛应用于许多交互式人工智能系统中。然而,仅仅将打印的图像或视频呈现给生物识别传感器可能会欺骗人脸识别系统。为了可靠地使用人脸识别系统,FAS 方法对于检测此类攻击非常重要。
近年来,已经提出了几种基于手工特征和基于深度学习的方法用于表现攻击检测 (PAD)。一方面,经典的手工描述符利用相邻的局部关系作为判别特征,这对于在活人脸和欺骗脸之间的信息描述具有鲁棒性。另一方面,由于具有非线性激活的堆叠卷积模块,CNN 具有很强的表示能力来区分真假。然而,基于 CNN 的方法侧重于更深层次的语义特征,这些特征不利于描述活人脸和欺骗人脸之间的细粒度信息,并且在环境变化时很容易失效。如何将局部描述符与卷积操作相结合以获得鲁棒的特征表示值得进一步研究。
最新的基于深度学习的 FAS 方法通常建立在基于图像分类任务的主干网络之上,例如 VGG、ResNet 和 DenseNet。网络通常由二分类交叉熵损失监督,它不利于学习具有区分度的特征。为了解决这个问题,已经开发了几种利用伪深度图标签作为辅助监督信号的深度监督 FAS 方法。然而,所有这些网络架构都是由专家精心设计的,这可能不是 FAS 任务的最佳选择。因此,应考虑使用辅助深度监督自动发现最适合 FAS 任务的网络。此外,设计高性能的快速方法对于现实的 FAS 应用程序至关重要。


图1 标准卷积和 CDC 的特征响应
受上述讨论的启发,作者提出了一种新的卷积算子,称为 CDC,它擅长描述细粒度的不变信息。 如图 1 所示,CDC 在不同环境中比普通卷积更有可能提取内在的欺骗信息。 此外,在专门设计的 CDC 搜索空间中,神经架构搜索 (NAS) 用于发现基于深度监督 FAS 任务的高效网络。创新点如下:
(1) 作者设计了 CDC 的新型卷积算子,由于其在不同环境中对不变细粒度特征的卓越表示能力,它适用于 FAS 任务。 在不引入任何额外参数的情况下,CDC 可以替代现有神经网络中的卷积,即插即用,形成具有强大的建模能力的 CDCN。
(2) 作者提出了 CDCN++,CDCN 的扩展版本,由搜索到的主干网络和多尺度注意力融合模块 (MAFM) 组成,用于有效地聚合多级 CDC 特征。
相关工作
(1) FAS
传统的 FAS 方法通常从人脸图像中提取手工特征来捕获欺骗信息。几个经典的局部描述符,如 LBP、SIFT、SURF、HOG 和 DoG,用于提取帧级特征,而视频级方法通常捕获动态线索,如动态纹理和眨眼。最近,针对帧级和视频级 FAS 提出了一些基于深度学习的方法。对于帧级方法,预先训练的深度 CNN 模型经过微调后在二分类监督中提取特征。相比之下,引入了辅助深度监督 FAS 方法能够更有效地学习更详细的信息。尽管实现了 SOTA 的性能,但基于视频级深度学习的方法需要长序列作为输入。此外,与传统的描述符相比,CNN 容易过拟合,很难在未知的场景上很好地泛化。
(2) 卷积算子
卷积算子常用于深度学习框架中提取基本的视觉特征。 最近已经提出了对普通卷积算子的扩展。 在一个方向上,经典的局部描述符被考虑到卷积设计中。 代表作品包括 Local Binary Convolution 和 Gabor Convolution,分别是为了节省计算成本和增强对空间变化的抵抗力而提出的。 另一个方向是修改聚合的空间范围。然而,由于不变细粒度特征的表示能力有限,这些卷积算子可能不适合 FAS 任务。
(3) NAS
现有的 NAS 方法主要分为三类:(1) 基于强化学习;(2) 基于进化算法;(3) 基于梯度。从计算机视觉应用的角度来看,NAS 已被用于开发人脸识别、动作识别、ReID、目标检测和分割等任务。
为了克服上述缺点,作者在专门设计的搜索空间上搜索帧级 CNN,使用新提出的卷积算子进行深度监督的 FAS 任务。
方法论
(1) CDC
在现代深度学习框架中,特征图和卷积以 3D 形状 (2D 空间域和额外通道维度) 表示。由于卷积操作在通道维度上保持不变,为简单起见,作者在 2D 中描述卷积。
由于 2D 空间卷积是 CNN 中视觉任务的基本操作,这篇文章首先对其进行回顾。 2D 卷积包含两个主要步骤:(1) 在输入特征图 x 上采样局部感受野区域 R;(2) 通过加权求和聚合采样值。因此,输出特征图 y 可以表示为:
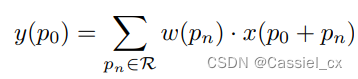
其中,
表示输入和输出特征图上的当前位置; 表示则枚举了感受野区域 R 中的位置,如 (−1, −1),(−1, 0), · · · ,(0, 1),(1, 1)。
作者受 LBP (以二进制中心差分方式描述局部关系) 启发将将中心差分引入普通卷积以增强其特征表示和泛化能力。同样,CDC 也包括两个步骤,即采样和聚合。采样步骤与普通卷积中的相似,而聚合步骤不同:如图 2 所示,CDC 更喜欢聚合采样值中心方向的梯度。
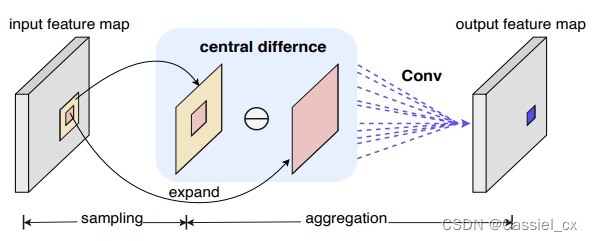
图2 CDC
CDC 公式如下:
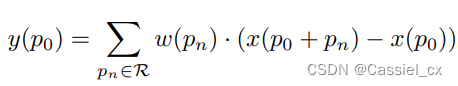
当
= ( 0, 0 ) 时,相对于中心位置 本身,其梯度值始终为零。
对于 FAS 任务,语义信息和详细信息对于区分活人脸和欺骗人脸至关重要,这表明将普通卷积与中心差分卷积相结合能提供更强大的建模能力。因此作者将 CDC 概括为:

其中,
,用于权衡深度和梯度级别信息之间的贡献。θ 的值越高,意味着中心差分梯度信息的重要性越高。
为了在现代深度学习框架中有效地实现 CDC,作者将上述公式进行分解和合并,修改后的公式如下:
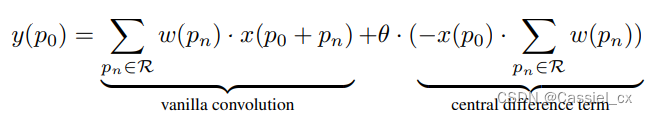
CDC 与 GaborConv 相比,GaborConv 侧重于增强空间变换 (即方向和尺度变化) 的表示能力,而 CDC 更侧重于表示不同环境中的细粒度鲁棒特征。
(2) CDCN
深度监督的 FAS 方法利用了基于 3D 形状的欺骗和活人脸之间的区分,并为 FAS 模型提供像素级详细信息以捕获欺骗线索。受此启发,作者建立了一个类似深度监督网络,称为”DepthNet”作为基线。为了提取更细粒度和鲁棒的特征来估计面部深度图,引入了 CDC 以形成 (CDCN)。请注意,当所有 CDC 算子的 θ = 0 时,DepthNet 是 CDCN 的特例。θ 的默认值为 0.7。
CDCN 的详细信息如表 1 所示。给定大小为 3×256×256 的单个RGB面部图像,提取多级融合特征用于预测大小为 32 × 32 的灰度面部深度。
表1 DepthNet 和 CDCN 的架构
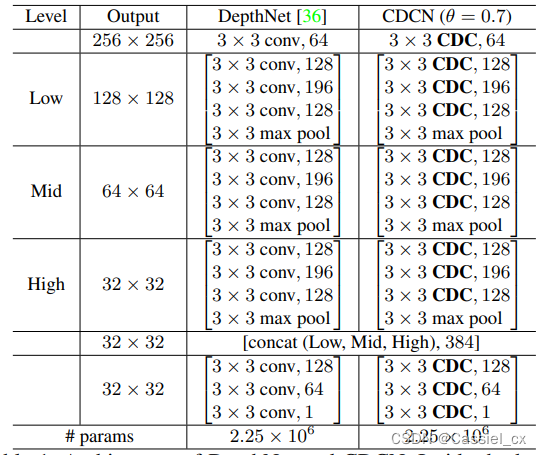
对于损失函数,均方误差 (mean square error, MSE) 损失用于逐像素监督。此外,为了 FAS 任务中细粒度的监督需求,对比深度损失 (contrastive depth loss, CDL) 被认为可以帮助网络学习更详细的特征。整体损失如下:

(3) CDCN++
从表 1 可以看出,CDCN 的架构设计粗糙,这可能会针对 FAS 任务进行次优化。受经典视觉目标理解模型的启发,作者提出了一个扩展版本的 CDCN++ (图 3),它由一个基于 NAS 的主干网络和多尺度注意力融合模块 (MAFM) 组成。

图3 CDCN++整体结构
虽然简单地融合低-中-高级特征可以提高搜索到的 CDC 架构的性能,但仍然很难找到需要关注的重要区域,这不利于学习更具区分性的特征。受人类视觉系统选择性注意的启发,不同层次的神经元可能在其感受野中受到不同注意的刺激。因此,作者提出了 MAFM,它能够通过空间注意力来细化和融合中低水平的 CDC 特征。
如图4所示,来自不同级别的特征通过空间注意与感受野相关的内核大小进行细化,即语义级别信息应该具有较小的注意力内核大小,而低级别信息应该具有较大的注意力内核大小,然后连接在一起。细化特征的表示如下:
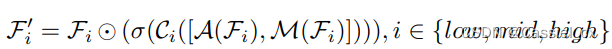
其中,
表示 Hadamard 乘积; 和 分别表示平均池化层和最大池化层; 表示 sigmoid 激活函数; 表示卷积层。具有 7×7、5×5 和 3×3 内核的普通卷积分别用于 、 以及 。由于 CDC 对空间注意力至关重要的全局语义认知能力有限,因此在 MAFM 中没有使用 CDC。
实验
表2 OULU-NPU 数据集上的测试结果
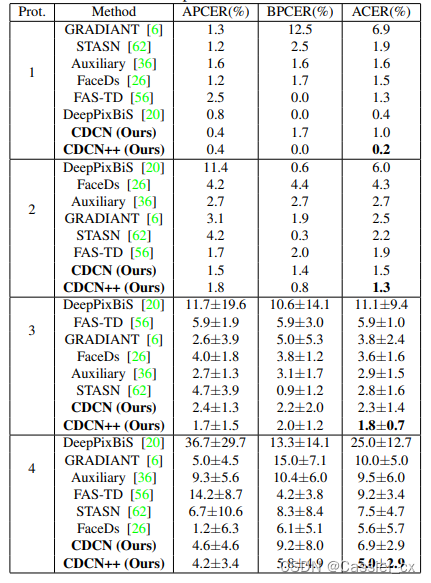
CDCN++ 的 ACER 指标性能最优。
结论
作者设计了 CDC,可以提取更加显著的细节特征,提升模型在 FAS 任务上的性能。此外,由于CDCN++ 的泛化能力强,因此可扩展到其他应用场景。
参考
活体检测——CDCN/CDCN++_Peanut_范的博客-CSDN博客
Original: https://blog.csdn.net/qq_38964360/article/details/125825815
Author: Cassiel_cx
Title: 活体检测CDCN学习笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532747/
转载文章受原作者版权保护。转载请注明原作者出处!