

MVSnet:从非结构化多视角立体中推断深度
网络输入:1张参考图像+N张原图像(从其他视角观察同一物体的图像),每张图像对应的相机内参和外参
网络输出:概率图+优化深度图,在后处理中使用概率图对优化深度图进行过滤
MVSnet的理解
- 一、训练数据处理
* - 1.数据准备
- 2.视图选择
- 二、特征提取
- 三、构建特征体
- 四、代价度量
- 五、代价空间正则化
- 六、深度图初始估计
- 七、概率图
- 八、优化深度图
- 九、损失计算
- 十、后处理
* - 1.深度图过滤
- 2.深度图融合
一、训练数据处理
1.数据准备
使用dtu数据集,因为其GT为点云或网格格式,采用SPSR(Poisson surface reconstruction,筛选的泊松表面重建)+网格渲染将原GT转化为深度图GT
2.视图选择
每个原图像分别与参考图像计算得分,取得分高的前N张图像作为网络输入原图像。
同时缩小图像尺寸至800×600,然后从中心裁剪W=640、H=512的图像块作为训练输入,输入的相机参数会相应地更改。
深度假设:[425,935]mm均匀取样,分辨率为2mm(D=256)或[425,902.5],分辨率为2.5mm(D=192)
二、特征提取



目标:提取每幅输入图像的特征,输入1个参考图像+N个原图像,输出N+1个32通道的特征图。
1.参数共享:与常见的匹配任务类似,参数在所有特征图间共享,即对所有视角的输入图像,用同一网络提取特征。
2.每个输入图像输出一个1/4原尺寸,32通道的特征图:将每个剩余像素的原始邻域信息编码到32通道的像素描述符中,与直接对原始图像稠密匹配相比,在特征空间中进行稠密匹配提高了重建质量。
; 三、构建特征体

目标:将所有特征图变换到参考相机的锥形立体空间,形成N+1个特征体Vi。
这里的空间是四维的,首先对四维空间有一个抽象的认知:
三维空间是一本书,书页的大小用长W和宽H来表示,书的每一页是一个Channel(通道),W、H、Channel三个维度构成了三维空间
四维空间是一摞书,每一本书构成第四个维度,用Depth(深度)来表示在这里,使用单应性矩阵对每个特征图进行变换
1.首先,每个特征图Fi对应D(深度采样数)个单应性矩阵,把每张特征图看成一本书,那么每个深度经单应性变换得到一本书,D个深度,会得到一摞书,书有D本。
2.变换过程:已知参考视角的内外参数矩阵,深度信息,可以计算参考视角像素坐标的世界坐标系值,即将其投影到世界坐标系。再通过已知的源视角内外参数矩阵,可以投影到源视角的相机坐标系,归一化后得到源视角的像素坐标。从参考视角到去找源视角的像素坐标对应点的计算过程,可以用单应性矩阵来描述。
这里的单应性变换是可微的,即可以实现反向传播,进行端到端训练(单应性变换只负责找对应点,实际的梯度计算和矩阵无关,是沿特征图反向传播的)。
最终,将在源视角对应点的特征(通道维度的所有数据)存放在参考视角的像素位置处完成变换。
3.形状:虽然假设的空间是关于参考视角的锥形立体空间(可以理解为拍摄参考图像的相机所在的相机坐标系,沿Z轴方向由Z的范围(深度假设范围)确定的一个立体空间),但在每个深度平面上像素点数量是一样的,作为数据存放时是方形的立体空间。
4.双线性插值:个人理解,对于找不到的对应点(对应点超出了特征图宽高边界),用插值填充。
5.参考视角的处理:直接在每个深度复制特征图,为代价度量做准备。
6.最终,每个特征图得到了一摞书,每本书代表一个深度,每本书的每一页代表一个通道,每本书的通道数相同,都为32(原特征图的通道数)。N+1个特征图,得到N+1摞书,这里实际上已经5维了,下一步计算将这N+1个特征体在同一空间位置的相似性进行代价度量,得到代价空间,降回4维。
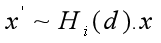

四、代价度量

目标:将N+1个特征体聚合为一个统一的代价空间C(将N+1摞书合并为一摞书)
C.shape:(D,W,H,F),D、W、H、F为深度采样数、输入图像的宽度,高度的1/4和特征图的通道数。理论:如果假设深度接近实际深度值,那么找到的对应点更准确,所有特征体在同一位置的特征相似性高,反之相似性低。即特征的相似性度量可以判断深度假设接近实际深度值的程度。方差反映了一组数据的波动情况,即数据越相似,方差越小,是一个反比关系。
实现过程:
N+1个特征体是重叠在同一空间位置的,对同一空间位置的点计算方差
比如说,将每摞书第一页左上角的点都取出来,然后计算方差,得到输出的那摞书的第一页左上角的点。对每个空间点都进行这样的计算,得到输出的一摞书,即最终的代价空间。现在代价空间是一摞页面大小相同的书,同样,页面大小为W、H,每一页代表一个通道,每一本代表一个深度。
使用方差的好处:
1.可以适应任意数量的原图像输入
2.显式的度量了多视图特征的差异

; 五、代价空间正则化

目标:根据代价空间C得到概率空间P(将一摞书合并为一本书)
抽象理解:
在这一步做了三件事
1.通过三维卷积对代价空间正则化,即将深度的取值集中起来,尽可能变成单峰分布。
2.三维卷积的最后将通道降为1,也就是把每本书都变成一页纸,一张纸代表一个深度。
这个时候可以把这些纸按序纸合并为一本书(W,H,D),页面大小为(W,H),页数为D,这就是最终的代价空间,对于书页((W,H)平面)上的每一个点,若它在第三页的值最大,那么这个点的深度就为第三页的取值(例如,[425,935]mm均匀取样,分辨率为2mm(D=256),那么第三页的深度为425+3×2=431mm)。
3.沿页数方向用softmax进行归一化,即对于(W,H)平面上的每个点,沿D方向的概率合为1.,这便得到最终的概率空间P.
下一步将从概率空间P获取初始深度图和概率图。
网络:类似于3D-UNet,使用编码器-解码器结构,以相对较低的内存和计算成本,从一个大的感受野聚集相邻的信息。
简单说一下三维卷积和二维卷积的区别:
二维卷积:一般的二维卷积核有三个维度,窗口大小(h,w)和与输入特征图相同的通道数c,每次卷积得到的是单通道图,即输入特征图为(B,C,H,W)时,输出特征图为(B,1,H,W),用卷积核数量控制输出通道数。(将卷积核数量也看作一个维度时,是4个维度)。
三维卷积:卷积核有四个维度,窗口大小(h,w),与输入特征图相同的通道数c,在depth维度的取值d,每次卷积所有通道参与,部分深度参与(取决于d的值)。若输入特征维度为(B,C,D,H,W),输出维度为(B,1,D,H,W)(深度维度的步长是1,有填充时),同样用卷积核数量控制输出的通道数。
六、深度图初始估计

目标:从概率空间P中获取深度图(将一本书变成一页纸,(W,H,1))
方法:
对(W,H)平面每个点,沿书页D方向计算期望,期望值即为该点的深度估计。使用期望的优势:
1.相比于argmax,过程可微
2.可以产生连续的深度估计
; 七、概率图

目标:由概率空间P获取深度质量的估计d(也是一张纸(W,H,1)),对深度图进行过滤。
深度估计的质量d:估计值在真实值附近一个小范围的概率。
计算方式:对概率空间,沿深度维度计算每四个邻域的概率和,再沿深度维度取最大的概率和。概率图:每个点的值表示该位置深度估计的有效性,概率越高,越可能为正确的深度估计(或该点的深度估计有效,不是背景等)。
八、优化深度图
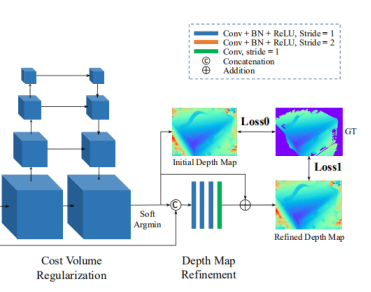
目标:利用参考图像的边界信息优化深度图。
初始深度图是一个不错的深度图,但由于正则化时感受野较大,重建的边界可能过度平滑,而自然场景中的参考图像包含边界信息。具体做法:
1.将参考图像(RGB3通道)缩小1/4,使其和初始深度图尺寸相同(W,H,3)。同时,将深度图(W,H,1)归一化[0,1](减最小值再除以(最大值减最小值)),防止在某个深度比例上产生偏差。将处理过的两个图进行通道拼接(W,H,4)
2.将拼接后的4通道图像放入 4层残差结构的卷积网络进行信息融合
3.将残差网络输出的单通道特征图(W,H,1)还原到深度假设的区间(与归一化过程相逆),将其与初始深度图逐元素相加,由此得到优化后的深度图。
; 九、损失计算


1.使用L1损失,分别对初始深度图和优化深度图进行损失计算,再以权重系数λ相加,λ一般设置为1.0。
2.只考虑GT中有深度信息的像素点(除过图中蓝色背景的区域)。
十、后处理
1.深度图过滤
1.光度一致性度量匹配质量。用网络得到概率图来衡量深度估计的质量。在实验中,将概率低于0.8的像素视为漏光像素。
2.几何约束度量多个视图之间的深度一致性,类似于立体图像的左右视差检查。几何约束可以用视差原理图来理解:
假设上图右相机为参考相机(左右相机共用深度图),通过像素点PR和它的深度d1,可以得到它在相机坐标系的实际位置(射线O2 PR上到线段O1 O2距离为d1的点),连接该点和O1,即可得到PR在左相机成像平面的对应点PL,将PL通过它的深度d2用同样的方式投影回右相机成像平面,因为深度使用的是估计值,因此投影回右相机成像平面的点会与PR产生位置偏差,假设投影点为P reproj,该点的深度估计为d reproj,如果重投影坐标P reproj和重投影点深度d reproj满足
则认为p1的深度估计d1是两视图一致的。在实验中,所有深度至少应为三视图一致性。


; 2.深度图融合
将不同视点的深度图融合到统一的点云表示中,使用基于可见性的融合算法,把遮挡,光照等影响降到了最低,使得不同视点之间的深度遮挡和冲突最小化。
为了进一步抑制重建噪声,在滤波步骤中确定每个像素的可见视图,并将所有重投影深度的平均值作为像素的最终深度估计。
融合后的深度图直接投影到空间,生成三维点云。Original: https://blog.csdn.net/qq_43027065/article/details/116641932
Author: 朽一
Title: 理解MVSnet
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532693/
转载文章受原作者版权保护。转载请注明原作者出处!