


文章提出了一种通过在模块中增加额外偏移量的空间采样位置和从目标任务中学习到偏移量且不需要额外的监督的方法来增强CNN的变换建模能力。基于这种思想提出了两个新模块:可变形卷积和可变形RoI池化。新模块可以很容易地取代现有CNN中的普通模块,并且可以通过标准反向传播轻松地进行端到端训练。
Deformable Convolutional Networks
; 参考目录
可变形卷积原文:Deformable Convolutional Networks
学习DCN时我看了很多别人的文章,都写得很好,我把对我有帮助的罗列在下面。
1、这篇非常直白,可以先了解个大概: 可变形卷积从概念到实现过程
2、这篇可以先看前面的解析增加了解,后面还有代码:deformable convolution(可变形卷积)算法解析及代码分析
3、这篇比较生动活泼:更灵活、有个性的卷积——可变形卷积(Deformable Conv)
4、最后这两篇写的比较细致完整,我最后还是看这两篇最多:
目标检测之Deformable Convolutional Networks(2017)
Deformable Convolution 关于可变形卷积
当然别忘记看原文,最后知乎的那篇评论有各路神仙发言,可以帮助理解。
下面仅记录我自己的一些理解。
可变形卷积
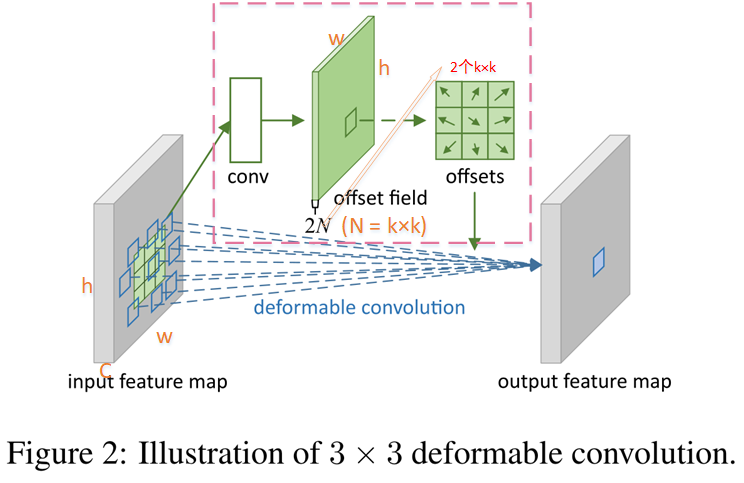
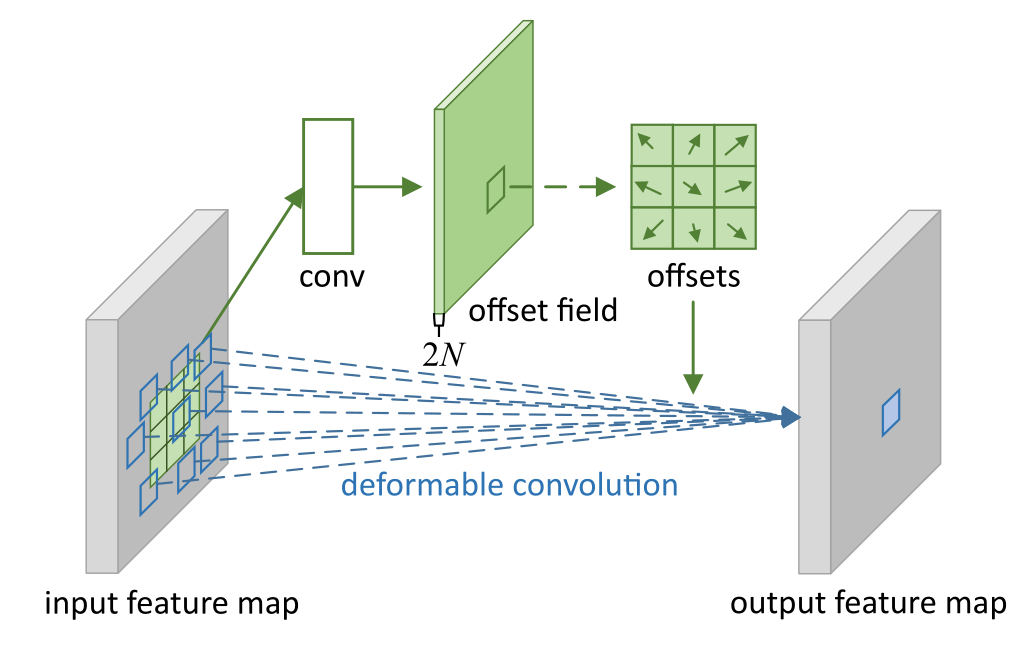
整个过程:
- 输入图片经过一个普通卷积得到input feature map 。
- 将input feature map先由一路(上图粉色部分)卷积得到偏移量Δ p n Δp_n Δp n 。
- 偏移量可能是浮点数,而图像位置都是整数,所以使用双线性插值来表示偏移位置。其次也是为了方便梯度反传。
- 将获得偏移量加到input feature map 得到新的采样位置,然后使用一个3×3卷积核提取特征(蓝色部分)得到output feature map。
其实非常简单,有几个注意点:
粉色虚线部分: 通过conv(与图中对应)得到整张input feature map图的偏移量(offset field)大小为h ∗ w ∗ 2 N hw2N h ∗w ∗2 N 。偏移的是input feature map图像位置而不是卷积。
- 2N是什么:2 是指x和y两个方向。N是k×k卷积核大小,具体到这张图就是3×3。也就是说offset field的维度2N=18是每个位置上xy两个方向分别九个偏移量的展开。得到两个offsets(x、y)刚好可以加到二维图像input feature map 的每个位置上。
- Offset field对应整个input feature map的大小,所以一次求得了每个像素位置的偏移量。
- Input feature map应该有C个通道,粉色中实现的是每个通道的偏移量,所以应该有对应的C个粉色虚线部分。
蓝色部分::
- 每个3×3的卷积核和特征图像做卷积前,先从粉色一路获取特征图像偏移量,得到偏移位置,用偏移位置的特征值做卷积。
- 形象表达一下,可以帮助理解,但是是错的!!!!!:就好像蓝色一路的卷积核做了一个形变然后印在特征图像上,和特征图像对应位置的特征值做卷积。
- 实际上卷积核是不动的,改变的是对应特征图像的位置。
最后再说一点:这个网络学习的不是偏移offset本身,而是如何从原图学习产生offsets的核的过程
最后祝各位科研顺利,身体健康,万事胜意~
Original: https://blog.csdn.net/qq_45122568/article/details/124190576
Author: 暖风️
Title: 可变形卷积:Deformable Convolutional Networks
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532585/
转载文章受原作者版权保护。转载请注明原作者出处!