

Yolov1-v4
文章目录
- Yolov1-v4
- 一. Yolo是什么?
* - (一)目标检测
- (二) Yolo 系列
- 二. Yolo的演进
* - (一)Yolov1
– - (二)Yolov2
–- 1. YoloV2模型结构
- 2. YoloV2训练过程
+ - 1)计算先验框
- 2)分类预训练
- 3)分类finetune
- 4)目标检测训练
- 4. YoloV2改进点
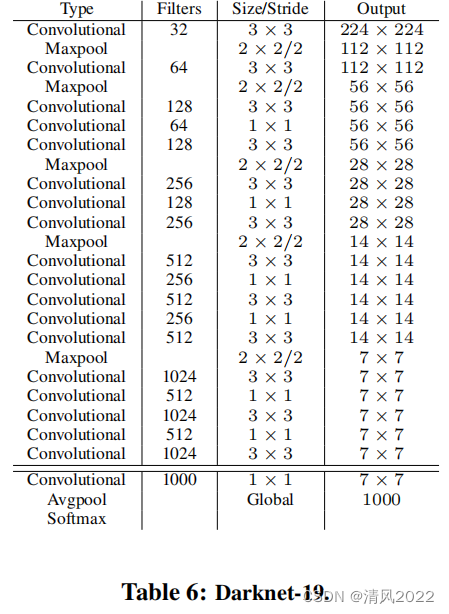
- 1. New network (DarkNet19)
- 2. Batch Normalization 归一化
- 3. High resolution classifier
- 4. Convolutional with Anchor Boxes
- 5. Dimension Clusters 聚类选择先验框
- 6. Direct location prediction 位置预测
- 7. Multi-Scale Training 多尺度训练
- 8. Fine-Grained Features 细粒度特征
- (三)Yolov3
– - (四)Yolov4
–
一. Yolo是什么?
YOLO,You Only Look Once,只需看一眼即可识别图像中物品及其位置。属于 one-stage 目标检测模型。
(一)目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的 类别和 位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
- two-stage 模型:R-CNN系列,包含 fast R-CNN, faster R_CNN,R-FCN和LibraR-CNN。 1) 定位候选框(位置) 2) 将含有单个物体的候选框进行分类(类别)
- one-stage 模型:Yolo系列 快!
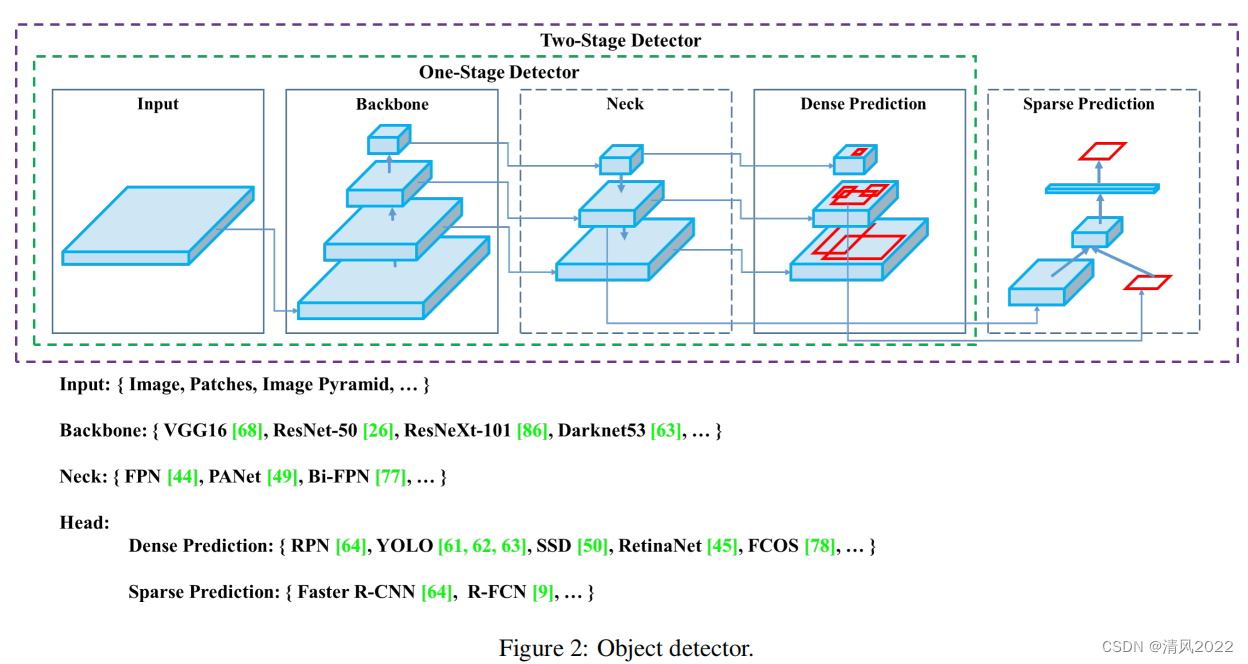

; (二) Yolo 系列
简称时间作者论文/代码YOLOV12016.5Joseph Redmon
《 You Only Look Once:Unifified, Real-Time Object Detection》
YOLOV22016.12Joseph Redmon
《YOLO9000: Better, Faster, Stronger》
YOLOV32018.4Joseph Redmon
《YOLOv3: An Incremental Improvement》
YOLOV42020.4Alexey Bochkovskiy
《YOLOv4: Optimal Speed and Accuracy of Object Detection》
YOLOV52020.5Ultralytics公司
yolov5 github
YOLOVX2021.8旷视科技研究院
刘松涛 《YOLOX: Exceeding YOLO Series in 2021》 github
YOLOV62022.06美团
gitHub
YOLOV72022.07.6Chien-Yao Wang、Alexey Bochkovskiy, Hong-Yuan Mark Liao
《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》 github
二. Yolo的演进
(一)Yolov1
1. Yolov1思想
将目标检测建模成回归任务, 同时预测边界区域和类别。可以端到端训练。
将目标检测建模成回归任务, 同时预测边界区域和类别。可以端到端训练。

; 2. Yolov1检测过程
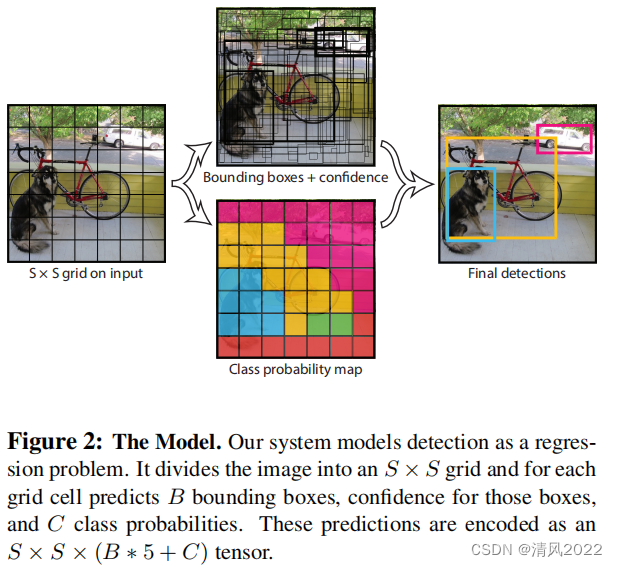
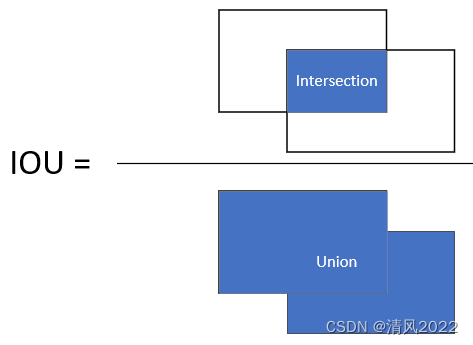
IOU
Intersection over Union 交并比
Intersection:两个框子相交的面积
Union:两个框相并的面积
; 3. Yolov1网络结构

4. Yolov1 训练过程
1)分类预训练
224×224 ImageNet1000-class数据集 前20层+平均池化层+全连接层
2)目标检测训练
预训练的前20层后追加 随机初始化的4个卷积层 和 2个全连接层。
数据集: PASCAL VOC 2007 and 2012
参数: batch size 64, momentum 0. 9,decay 0.0005, dropout layer rate = .5 after the first connected layer
训练输入: 448×448
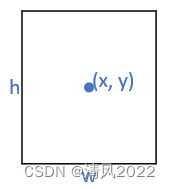
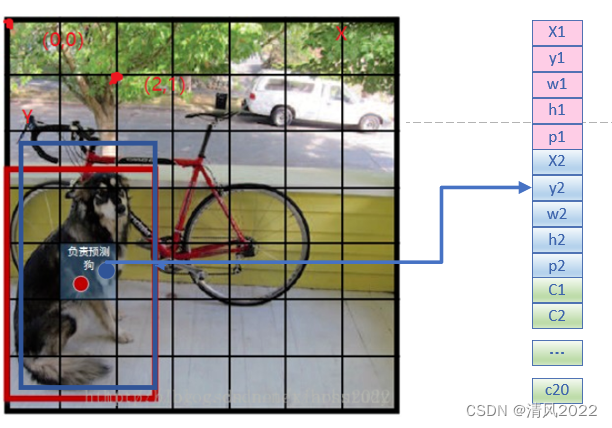
训练输出:每个单元格预测一个类别,构建训练数据。 其中w,h为相对原始图像的缩放比例,在0到1之间。(x,y)为相对网格的偏移值,也在(0,1)之间。
置信度p
训练阶段, 如果选中区域中不包含物体,则为0,如果包含物体,则为IOU
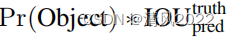
测试阶段,置信度p计算如下:
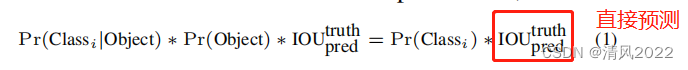
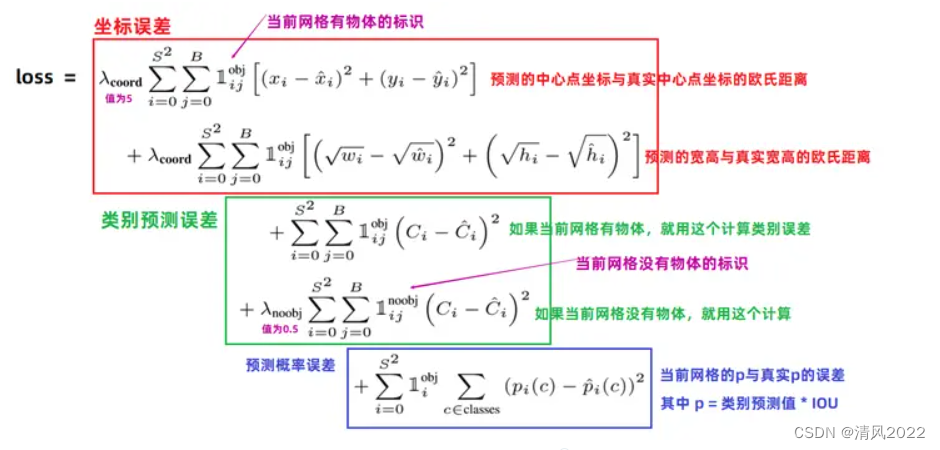
; 损失函数
因为不包含对象的单元格较多,因为会增加权重
激活函数
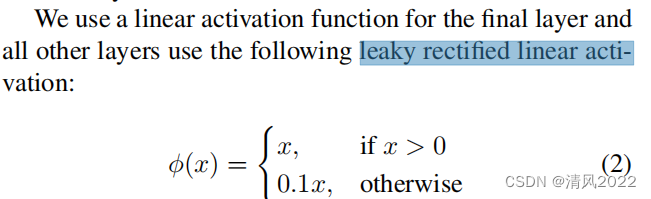
5. Yolov1 推理过程
1)模型推理
输入:448×448×3 固定尺寸
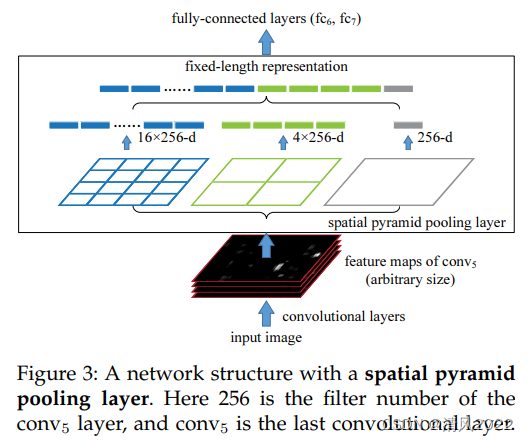
模型结构:参见Figure3
输出:共预测7×7×2=98个边界框,示例S=7, B=2, C=20 预测一个边界框(x,y,w,h,p)输出为7×7×(2×5 +20)
2)后处理:非极大值抑制
非极大值抑制,筛选出最终的结果。在RCNN算法中提出。

1)设定目标框的置信度阈值,常用的阈值是0.5左右
2)根据置信度降序排列候选框列表
3)选取置信度最高的框A添加到输出列表,并将其从候选框列表中删除
4)计算A与候选框列表中的所有框的IoU值,删除大于阈值的候选框
5)重复上述过程,直到候选框列表为空,返回输出列表
; 6. YoloV1缺点
- 输入尺寸固定
- 每个格子最多只预测出一个物体
- 精度差
(二)Yolov2
1. YoloV2模型结构
Yolov2中网络结构发生了改变,采用DarkNet19网络(有19个卷积层)。去掉全连接层,进行了5次降采样,减少计算量。
2. YoloV2训练过程
1)计算先验框
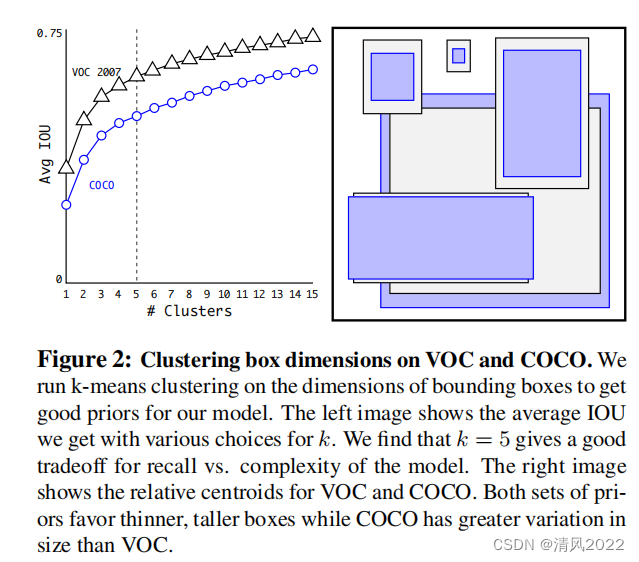
Yolov2版本中每个网格要预测 5 个bbox,但是这5个bbox的大小是通过原始图片聚类得到的,将原始图像中物体框通过K-means算法聚成5类,然后取这五类的平均值作为bbox的大小。这样得出的box的大小更符合实际情况,检测效果更好。
使用k-means 选择先验框
距离计算
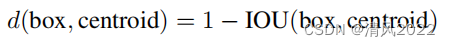
; 2)分类预训练
数据集: ImageNet 1000 class classifification dataset
输入:224 × 224×3
模型结构:
输出:采用global avgpooling做预测
3)分类finetune
输入:448 × 448×3
输出:13x13x(5*(5+classnum))
10epochs微调
4)目标检测训练
模型结构:
; 4. YoloV2改进点
Better, Faster, Stronger
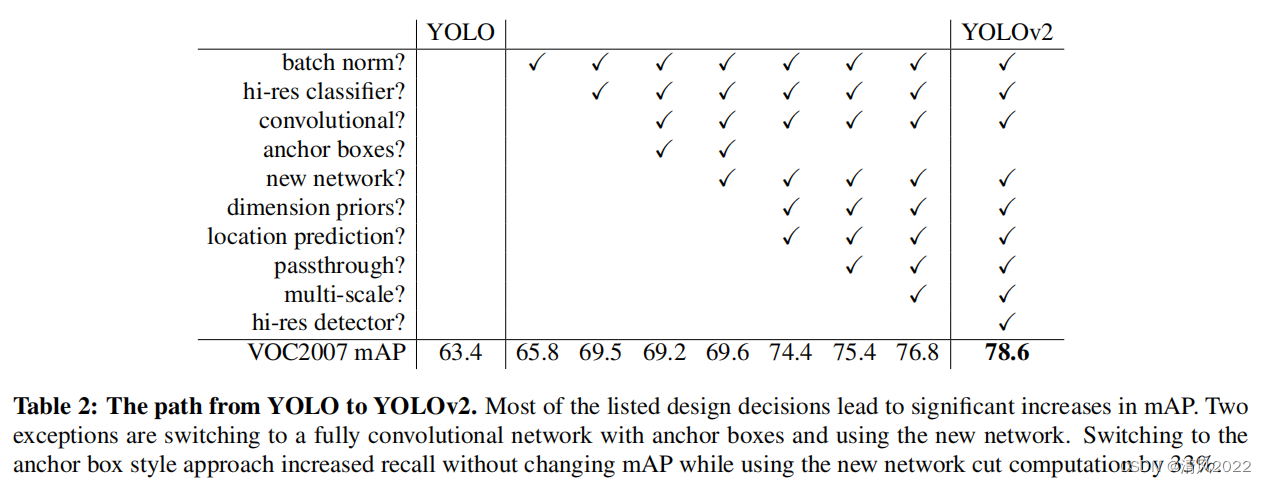
1. New network (DarkNet19)
2. Batch Normalization 归一化
Batch Normalization可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用dropout。
3. High resolution classifier
Yolov1在训练时用的图片大小时224×224,在检测时Yolov1输入的是448×448大小的图片 ,这样可能会导致模型前后不一致,影响效果。
Yolov2增加了10个epochs 448×448分辨率的微调,然后在detection network上微调。
4. Convolutional with Anchor Boxes
使用anchor boxes预测边界框。
Yolov1将输入图像分成7×7的网格,每个网格预测2个Bounding Box,因此一共有98个Box。
Yolov2使用了anchor boxes,每个Cell可预测出5个Anchor Box,共13×13×个boxes。
5. Dimension Clusters 聚类选择先验框
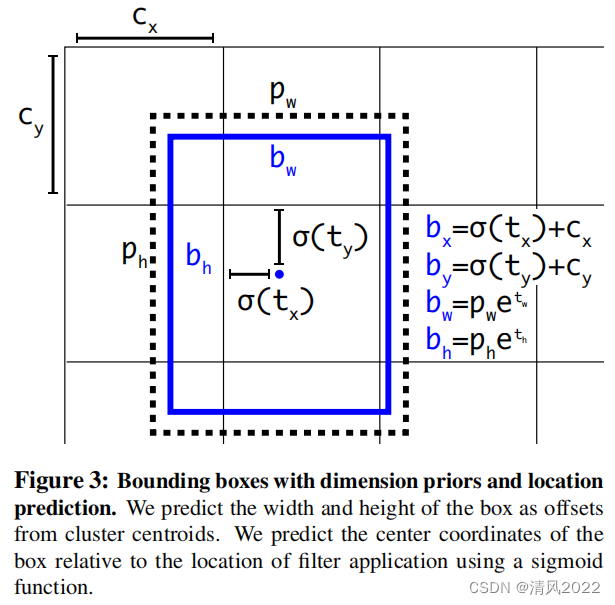
6. Direct location prediction 位置预测
预测中心点在网格中的相对位置,使用sigmoid函数将预测值约束到网格中。

; 7. Multi-Scale Training 多尺度训练
训练过程中每间隔一定的iterations之后改变模型的输入图片大小。增强模型的鲁棒性。
在YOLOv2中没有全连接层,只有卷积层和池化层,因此模型可以接受任意尺寸的输入。采用不同size的样本来训练网络。具体做法为:训练过程中每间隔一定的iterations之后改变模型的输入图片大小。因为下采样率为32,所以选择的尺寸都是32的倍数,具体的范围为

这样的训练过程使得模型能够从不同分辨率的输入中学习,从而对不同分辨率的输入只需要修改对最后检测层就能够进行预测。
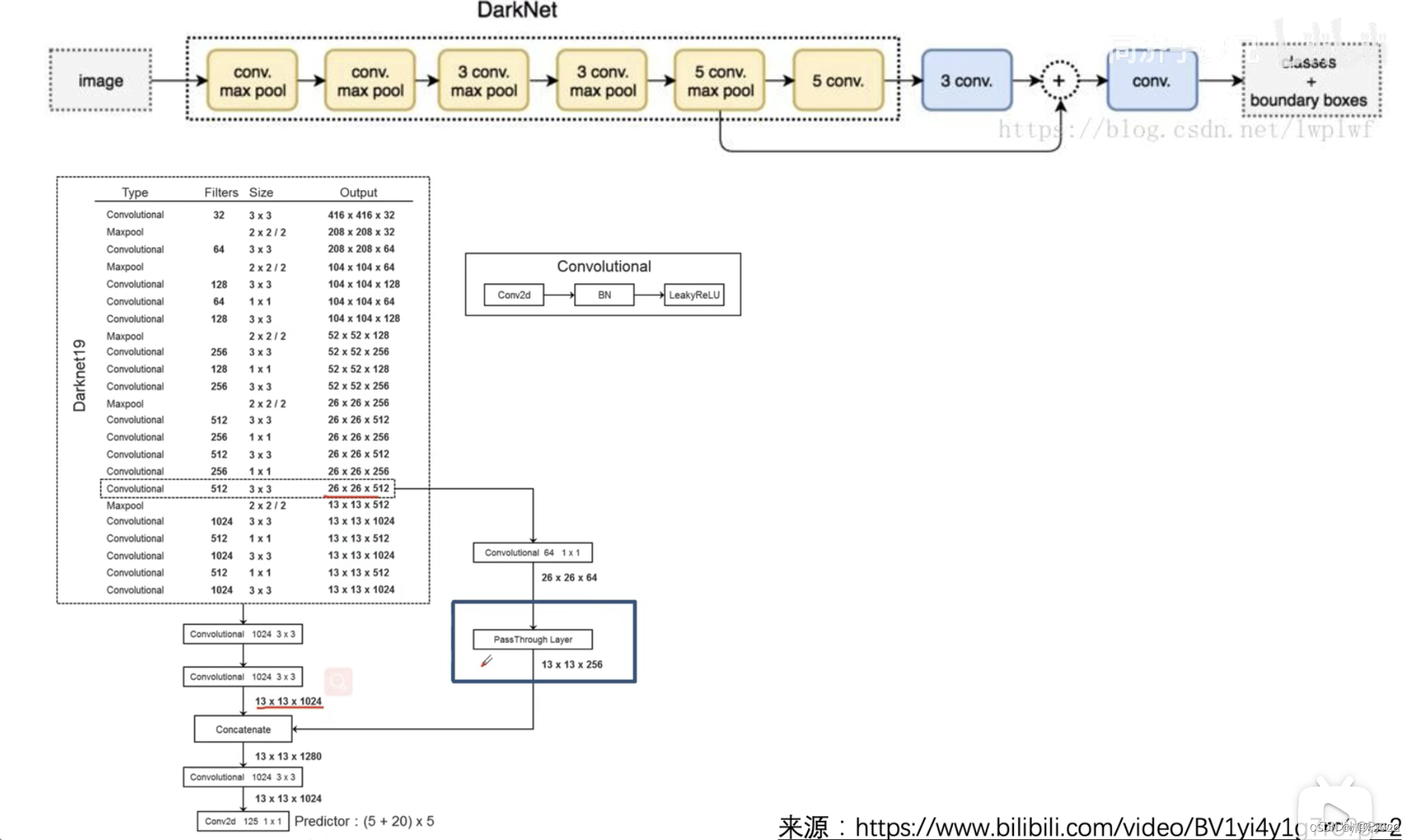
8. Fine-Grained Features 细粒度特征
YOLOv2输入为416×416,5次池化最终输出为13×13×1024。对于大目标来说,最终的特征图足以提取其特征;
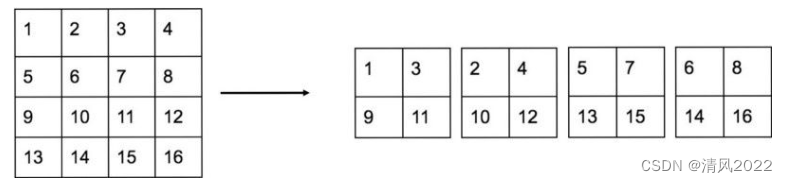
但对于小目标,多次卷积池化后特征不明显,因此需要更精细的特征图(Fine-Grained Features)。YOLOv2引入一种称为passthrough层的方法在特征图中保留一些细节信息
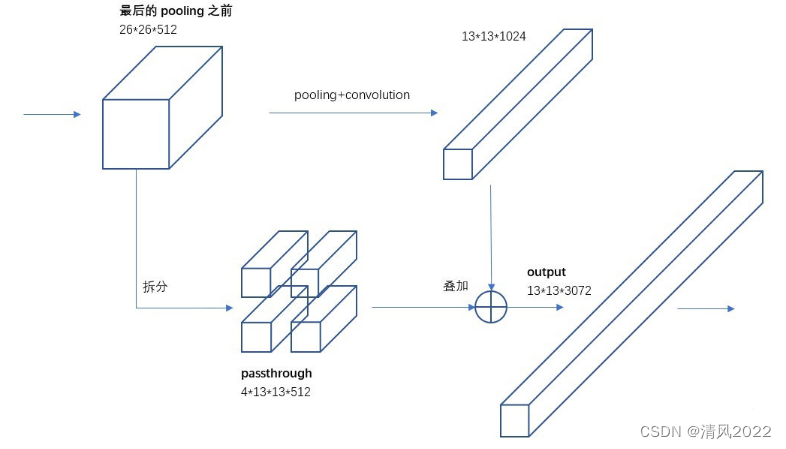
其中,passthrough layer拆分方式如下图所示:
; (三)Yolov3
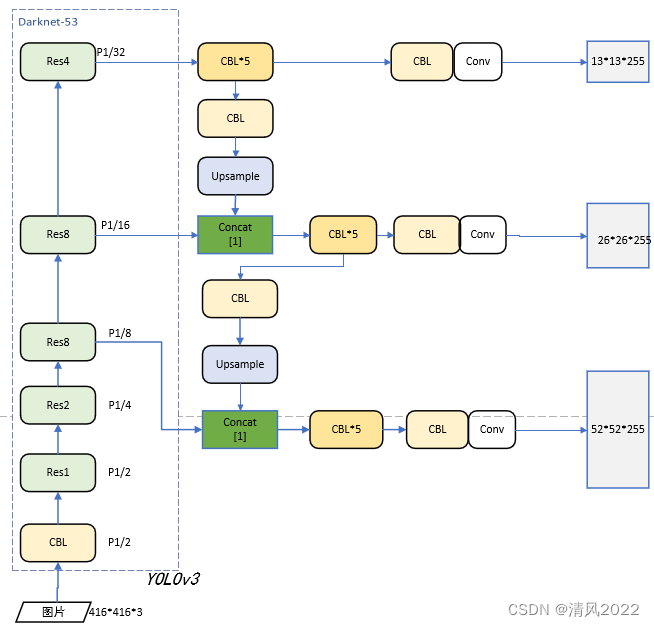
1. YoloV3网络架构
Yolov3 将原来的 darknet-19 改进为darknet-53,引入resnet(残差网络)

; 2. YoloV3 可预测多标签
使用交叉熵损失函数,而不是softmax
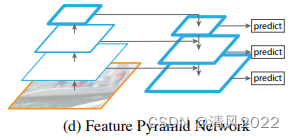
3. YoloV3 Predictions Across Scales
是真正的多尺度,一共有3种尺度,每个尺度有3个先验框,共9个。
分别是13×13,26×26,52×52三种分辨率,分别负责预测大,中,小的物体边框,这种改进对小物体检测更加友好。
FPN
; (四)Yolov4
Yolov3和Yolov4两个版本的作者发生了变化。
Yolov4则是在Yolov3算法的基础上增加了很多实用的技巧,使得它的速度与精度都得到了极大的提升。
Yolov4对深度学习中一些常用Tricks进行了大量的测试,最终选择了这些有用的Tricks:WRC、CSP、CmBN、SAT、 Mish activation、Mosaic data augmentation、CmBN、DropBlock regularization 和 CIoU loss。
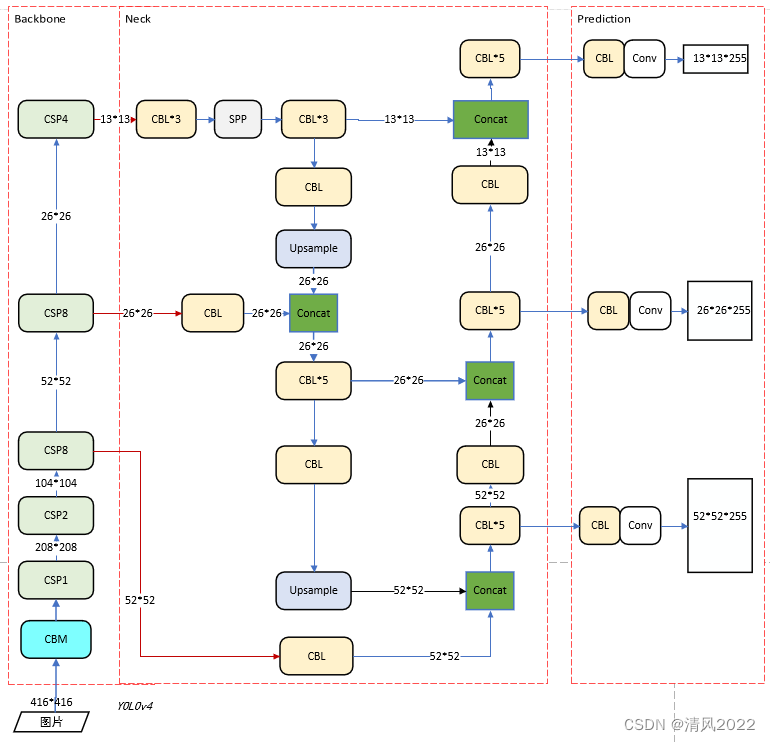
1. YoloV4网络架构
核心思想:三个尺寸特征的融合
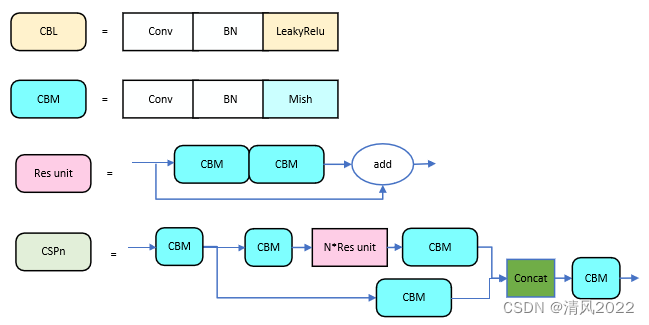
CBL-CBL模块由Conv+BN+Leaky_relu激活函数组成。
CBM-CBM是Yolov4网络结构中的最小组件,由Conv+BN+Mish激活函数组成。
Res unit-借鉴ResNet网络中的残差结构,用来构建深层网络,CBM是残差模块中的子模块示。
CSPX-借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成而成。
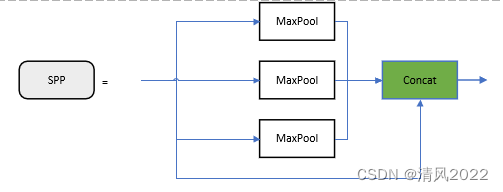
SPP-采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合
; 输入端
在模型训练阶段,做了一些改进操作,主要包括 Mosaic数据增强、cmBN、SAT自对抗训练;
BackBone基准网络
融合其它检测算法中的一些新思路,主要包括: CSPDarknet53、Mish激活函数、Dropblock;
Neck网络
目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov4中添加了 SPP模块、FPN+PAN结构;
输出端
(80+5)*3=225
输出层的锚框机制与YOLOv3相同,主要改进的是训练时的损失函数 CIOU_Loss,以及预测框筛选的DIOU_nms。
2. YoloV4训练阶段
1)分类训练
数据集: ImageNet image
输入数据: Mosaic
训练过程:
2)目标检测训练
数据集: MS COCO
训练过程:cmBN
3. YoloV4推理阶段
4. YoloV4输入端
- *Mosaic数据增强
Mosaic数据增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成

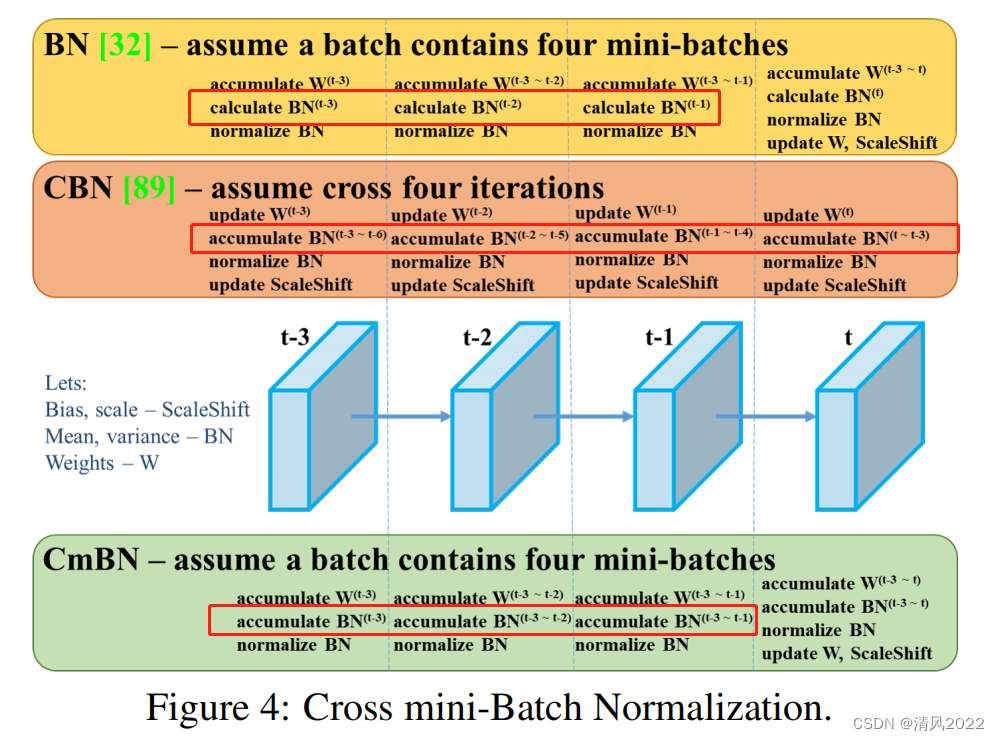
- *; cmBN
BN是对当前mini-batch进行归一化,CBN是对当前以及当前往前数3个mini-batch的结果进行归一化,而CmBN则是仅仅在这个Batch中进行累积。
- SAT自对抗训练1)生成对抗样本 2)使用对抗样本进行训练
5. YoloV4 Backbone
- CSPDarknet53Cross Stage Partial Network 论文链接 resnet -> desenet -> cspnet 优点:减少计算量 CSPNet的作者认为推理计算过高的问题是由于网络优化中的 梯度信息重复导致的。 CSP模块先将基础层的特征映射划分为两部分, 然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
- 激活函数Leaky-ReLU是Relu的变体,函数形式如下所示:
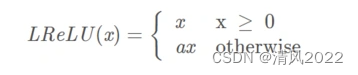
其中a为固定参数,通常取0.01。
优点:缓解Relu导致神经元死亡的问题。
缺点:非线性没有ReLU 强大。
使用场景:不适合分类任务,适合回归任务,卷积神经网络 隐藏层使用。
; Mish
Mish激活函数是Leaky_relu算法的基础上改进而来的,更加平滑一些,可以进一步提升模型的精度。
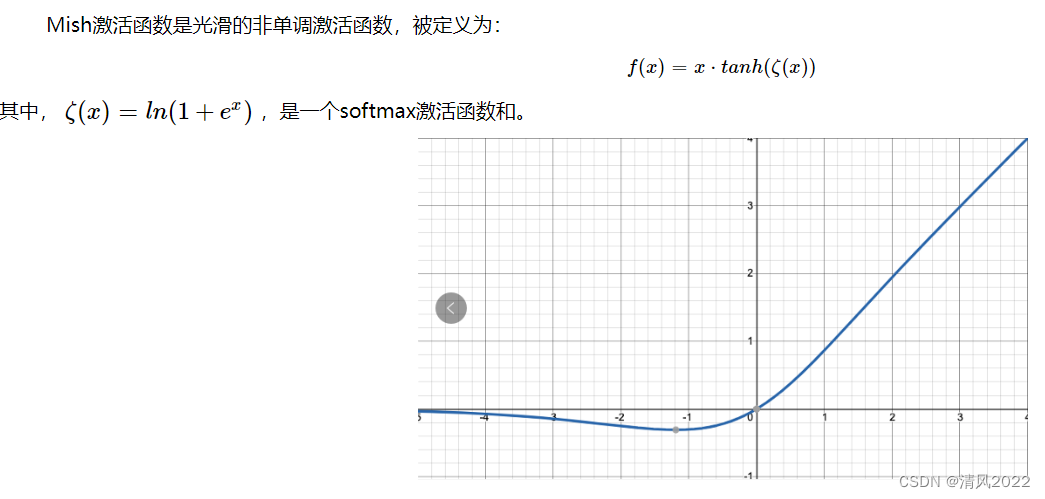
优点:有上限,无下限,光滑,非单调
缺点:计算量大
- DropblockDropblock是一种解决模型过拟合的正则化方法,它的作用与Dropout基本相同。Dropout的主要思路是随机的使网络中的一些神经元失活,从而形成一个新的网络。如下图所示,最左边表示原始的输入图片,中间表示经过Dropout操作之后的结果,它使得图像中的一些位置随机失活,Dropblock的作者认为:由于卷积层通常是三层结构,即卷积+激活+池化层,池化层本身就是对相邻单元起作用,因而卷积层对于这种随机丢弃并不敏感。除此之外,即使是随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。最右边表示经过Dropblock操作之后的结果,我们可以发现该操作直接对整个局部区域进行失活(连续的几个位置)。

; 6. YoloV4 Neck
- SPP模块Spatial Pyramid Pooling(空间金字塔池化结构) 论文链接
通过融合不同大小的最大池化层来获得鲁棒的特征表示。 采用全局最大池化,可以使输出固定。
- ; FPN+PAN深层网络容易响应语义特征,浅层网络容易响应图像特征几何信息 FPN, Feature Pyramid Networks,高维度向低维度 捕获强语义特征。 PAN, Path Aggregation Network 低纬度向高纬度 传递定位信息。 通过组合这两个模块,可以很好的完成目标定位的功能。
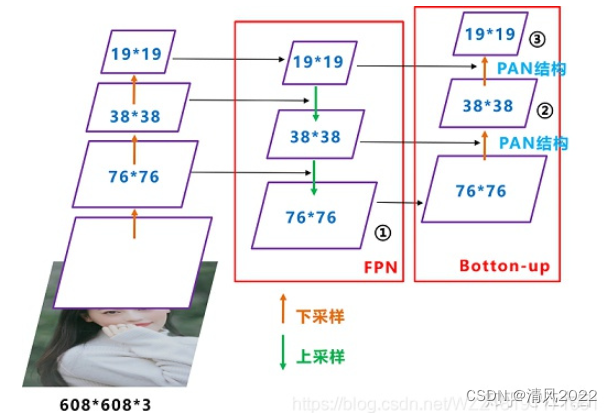
7. YoloV4 输出
采用CIOU
特征IOU交并比GIOU交并比,外接矩形DIOU交并比,中心点距离CIOU交并比,中心点距离, 长宽比
- IOU*IOU
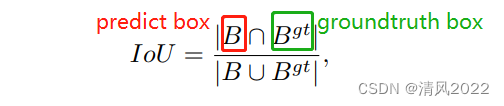
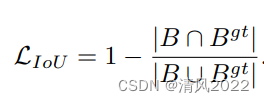
但以下情况无法处理

; GIOU
generalized IoU

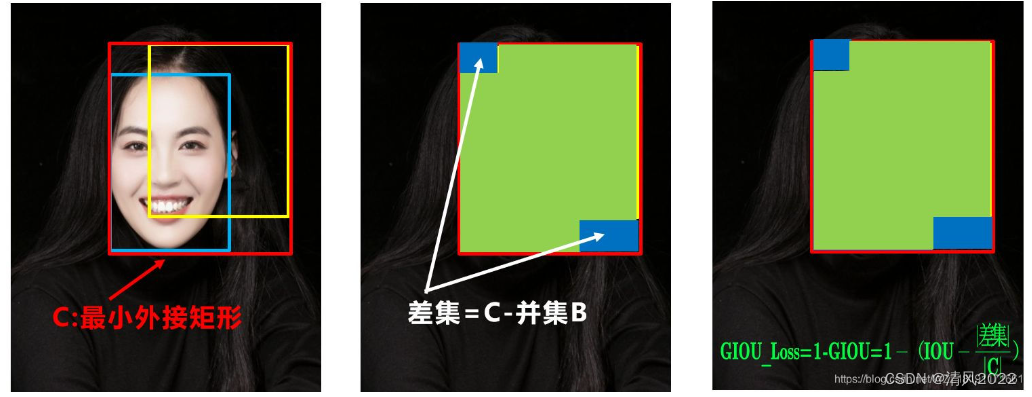
但以下情况无法处理
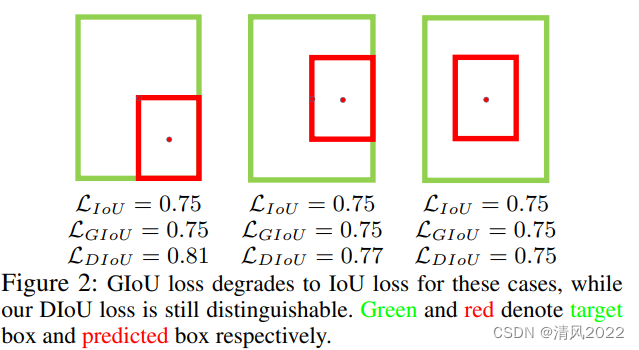
DIOU
相比IOU 添加中心对角距离
Distance-IoU 参考论文

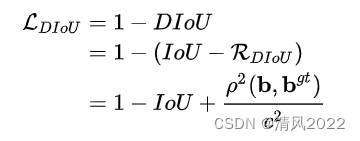

; CIOU
相比IOU 添加中心对角距离和长宽比
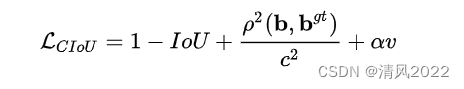

Original: https://blog.csdn.net/weixin_41021342/article/details/125730204
Author: 清风2022
Title: YoloV1~YoloV4
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532388/
转载文章受原作者版权保护。转载请注明原作者出处!