

前言
最近博主在做的一个项目中涉及到了中文NER任务。所以调研了近些年来中文NER上有什么刷榜的模型。发现了两个宝藏模型:FLAT和LEBERT。本篇文章将简单介绍下这两个模型各自的思想,并针对LEBERT的GitHub代码做一些实验上的分析。最后,还会提出一些NER数据增强方法。
原文链接:中文NER—项目中的SOTA应用


一、FLAT(ACL2020)
1、论文标题:《 FLAT: Chinese NER Using Flat-Lattice Transformer 》
2、论文链接: https://arxiv.org/pdf/2004.11795.pdf
3、Github: https://github.com/LeeSureman/Flat-Lattice-Transformer
4、方法
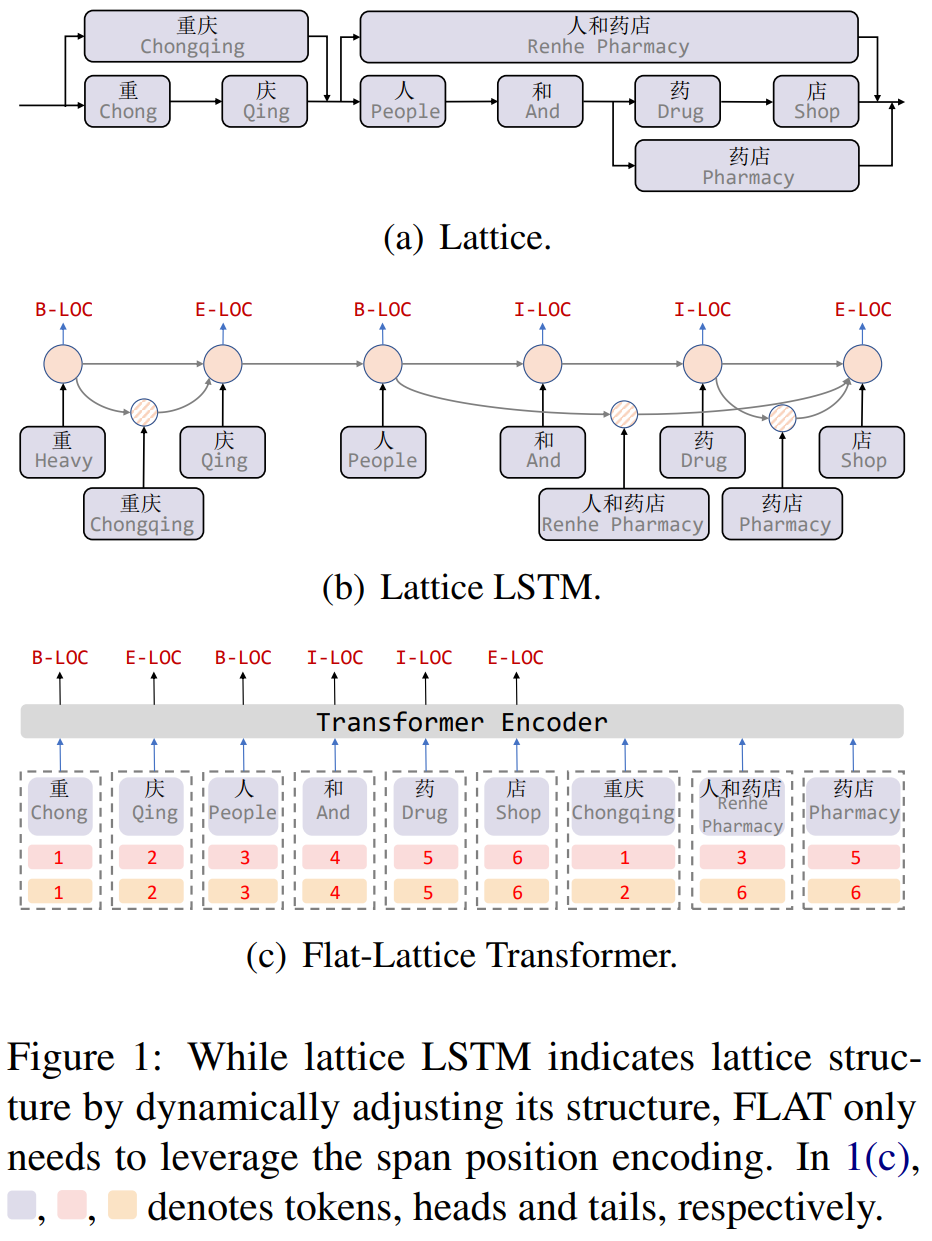
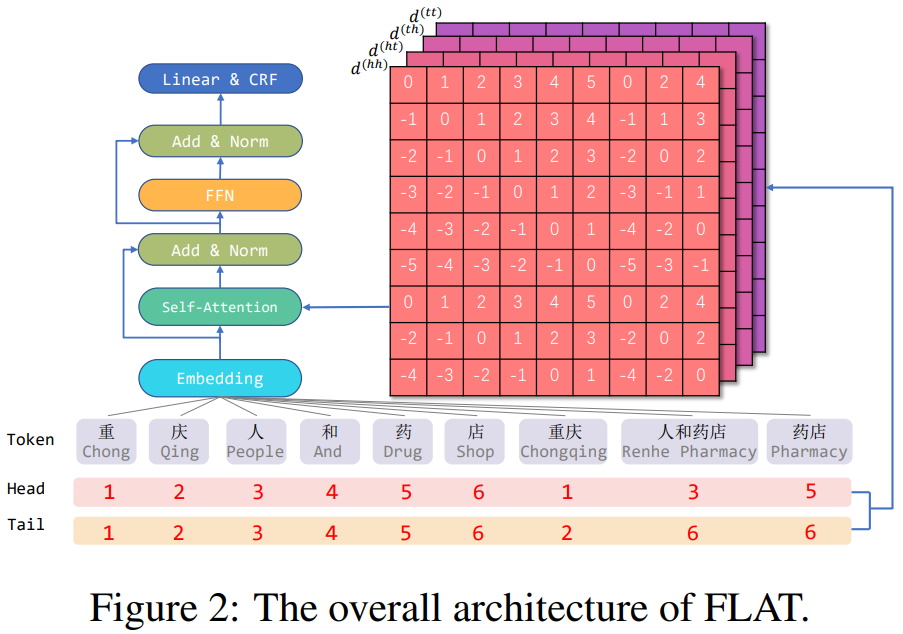
FLAT结构如下图Figure1(c)所示,每个字符和每个潜在的word使用head和tail两个索引去表示token在输入序列中的绝对位置,head表示开始索引,tail表示结束索引,对于每个字符,head和tail是一样的;每个word是不一样的,比如word “重庆”,head为1,tail为2,说明序列中第一个字符和第二个字符为”重庆”。
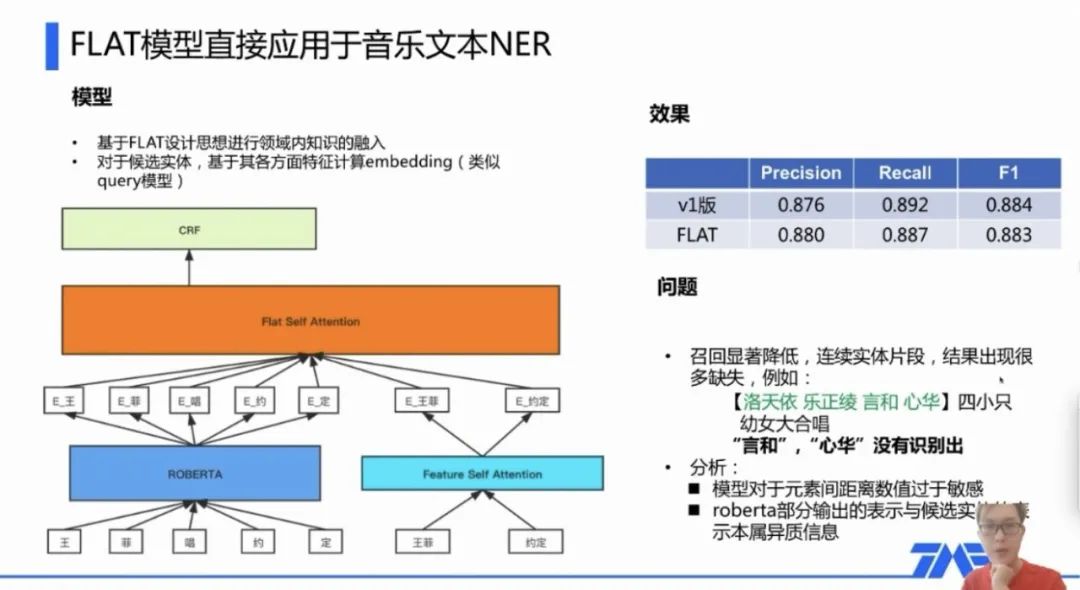
5、腾讯音乐文本NER
之前听分享报告,腾讯QQ音乐在做音乐文本NER时,采用的就是FLAT模型。其NER优化方案就是:设计更好的领域内知识融入模型。而该项目是2020年做的,当年领域内知识融入的SOTA便是ACL2020成果FLAT。该模型重要思想在于:1)候选实体和原token放到同一序列中;2)知识融入在attention计算时进行。
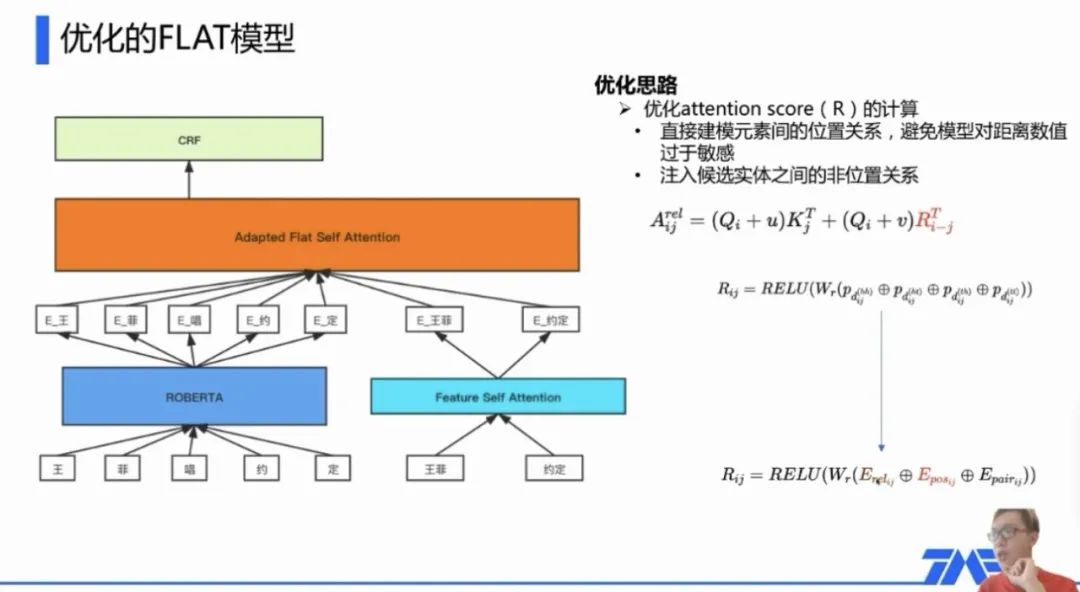
这里附上两张当时的截图,对FLAT直接应用的效果以及如何做优化:
二、LEBERT(ACL2021)
1、论文标题:
《 Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter 》
2、论文链接: https://arxiv.org/abs/2105.07148
4、方法
该文在中文NER,中文词性标注,分词任务上实现state of the art。在模型中添加词信息并不算罕见,在此之前就有很多论文采用了这种方法,并且模型效果都不错,但这篇论文相比于之前的论文在信息融合上做了一些改变。
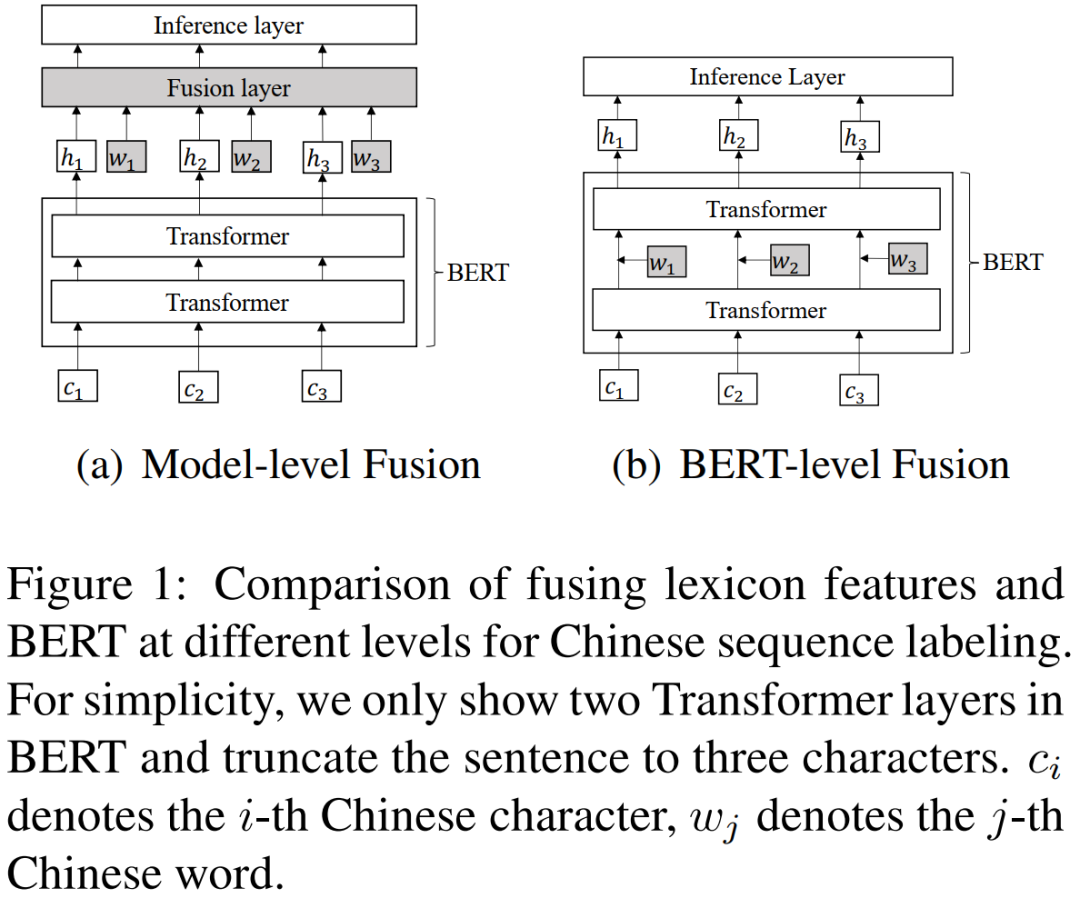
模型结构如上所示,左边是其他模型的信息融合方案,是将BERT模型的输出和词信息通过一个融合层(比如线性层),得到融合后的向量,这个向量既包含了字信息也包含了词信息,但是本篇论文认为这样融合的效果一般,于是提出了另一种融合方案,也就是右边的模型,相比于左边的模型,这个模型将融合信息层放在了BERT模型中的某一层后面,这使得字信息和词信息能更好的融合。
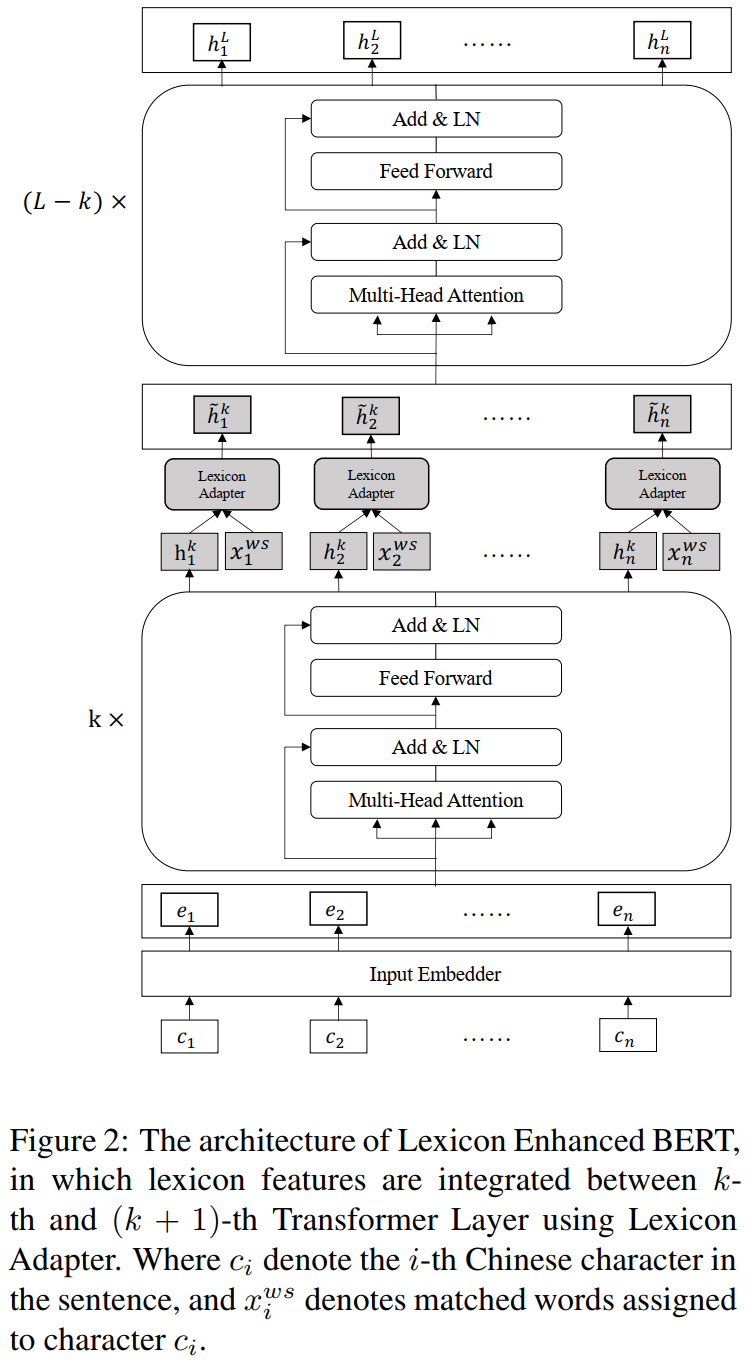
LEBERT结构图如上所示,可以看作是Lexicon Adapter和BERT的结合,其中Lexicon Adapter应用到了BERT当中的某一个Transformer层。
对于给定的中文句子
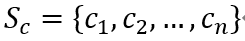
,将其构建成character-words pair sequence形式
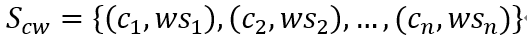
。
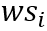
表示包含字符
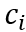
的词汇组成的组合,其中BERT的输入为
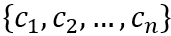
,假设第k层transformer输出
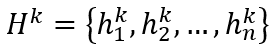
,Lexicon Adapter嵌入到第k层和第k+1层Transformer之间。
三、一些关于LEBERT复现实验
1、对数据的解读
1)训练数据主要组成文件如下图,train.json和 train.char.bmes 和 labels.txt
2)labels.txt(标注标签文件,采用的是IOBES标注法)

3)train.json

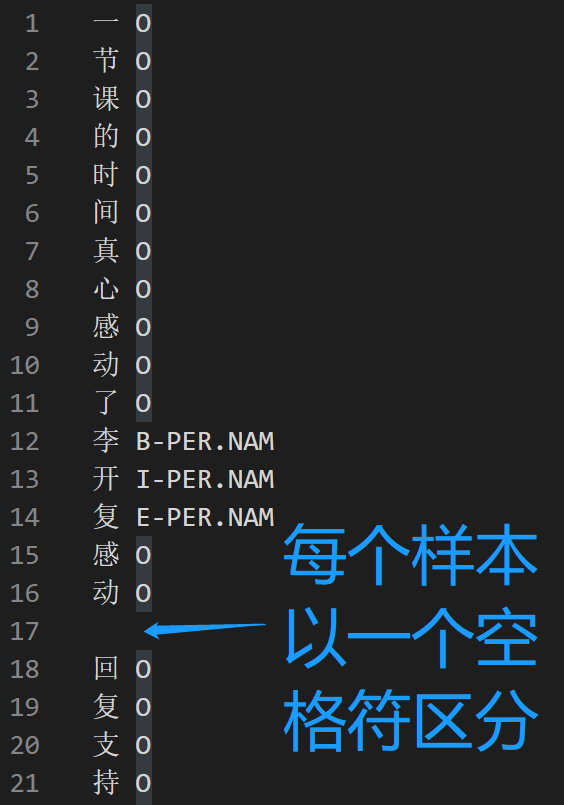
4)train.char.bmes 该文件对应train.json中的每一条训练数据,只是train.char.bmes需要以”char-标签”的方式进行存储。
2、BUG复现
【题外话】这块我只提两个比较令人头疼的BUG,毕竟在博主解决它们时做了一些列的验证实验,想想还是有必要提一提,以方便后面复现实验的肝帝们能轻松一些。当然如果你在复现的时候还有什么其他的BUG,也可以私信我啦,也许我知道呢!!!
1)第一个bug

解决方案:
vocab.py中convert_id_to_item中id会超过idx2item列表的范围,Trainer.py中第526行的label_vocab。打印一下label_vocab.init_vocab(),你会发现item2idx和idx2item会重复进列表,导致列表超出范围。
2)第二个bug
模型训练时预测效果很好,但是单独与测试效果很差的验证。
解决方案:阿弥陀佛,这可把博主折磨的够呛的,做了N多个验证后,确定是分布式训练导致模型参数保存时漏掉了某几层参数,致使单独预测加载模型时这几层参数重置。
- 预测代码验证:重新训练开源数据weiboNER,并进行训练阶段预测和单独加载模型预测,结果是训练阶段预测效果很好,单独预测效果非常差。预测代码没问题;
- 模型参数验证:训练阶段和单独预测阶段,模型加载时的参数对比。训练时加载的模型参数是完整的,而单独进行预测时某些层参数会被重置(weigth重置值为1.的矩阵、bias重置值为0.的矩阵);
- 训练时会提示:some weights of the model checkpoint were not used when initializing 。这是正常的,BERT checkpoint 是由 Mask Language model 和 Next Sentence Predict 训练的参数,对于下游任务,只会用到BERT编码器,一些权重将不会用到下游任务中;
- 分布式验证:原模型训练时进行了分布式参数设置,某些参数被分布训练导致单独预测加载模型时没有加载部分参数,进而导致参数重置。去掉分布式参数进行训练后,在开源数据weiboNER上,训练时预测结果与单独加载训练后的模型进行预测结果是一致的。 【 run_demo.sh 中去掉分布式参数:-m torch.distributed.launch –master_port 13517 –nproc_per_node=1 】
四、NER中的数据增强
1、实体替换
解决实体不均衡的问题。有的实体在数据中出现次数较少,我们可以通过实体较多的样本,将该稀缺实体替换上去。比如”月均收入”可以替换为”平均收入”。
2、实体扩充
解决实体类型少的问题。比如实体”一万”,我们可以扩充实体的类型为”1万”或”壹万”等。
3、实体规避
解决实体冲突问题,不同中标签可能会对应到同一种实体。比如对于金服质检项目中,我们设置了两种标签MAN(满期)和MONTH(每个月),但这两种标签都涵盖了少部分相同的实体,导致NER模型在识别这类实体时准确度较低。
4、非实体片段替换
增加文本噪声,增强模型在同一非实体文本中识别不同实体的能力。比如:这是周杰伦的歌曲七里香——>七里香是周杰伦唱的。
5、实体名扰动
增加实体噪声。在实体的基础上增加扰动信息,比如:可以在”每一天”的基础上增加扰动信息”每每”,变为”每每每一天”。
6、实体样性扩增
增加对应标签实体的丰富性。
Original: https://blog.csdn.net/u014577702/article/details/121373289
Author: NLP分享汇
Title: 中文NER—项目中的SOTA应用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532137/
转载文章受原作者版权保护。转载请注明原作者出处!