

文章目录
1 项目介绍
1.1 背景知识介绍
对话系统按领域分类,分为任务型和闲聊型。闲聊型对话系统有Siri、微软小冰、小度等。它们实现可以以任意话题跟人聊天。任务型对话系统是以完成特定任务为目标的对话系统。例如可以以订机票为一个特定的任务,实现的对话系统。我们这里重点关注任务型对话系统。
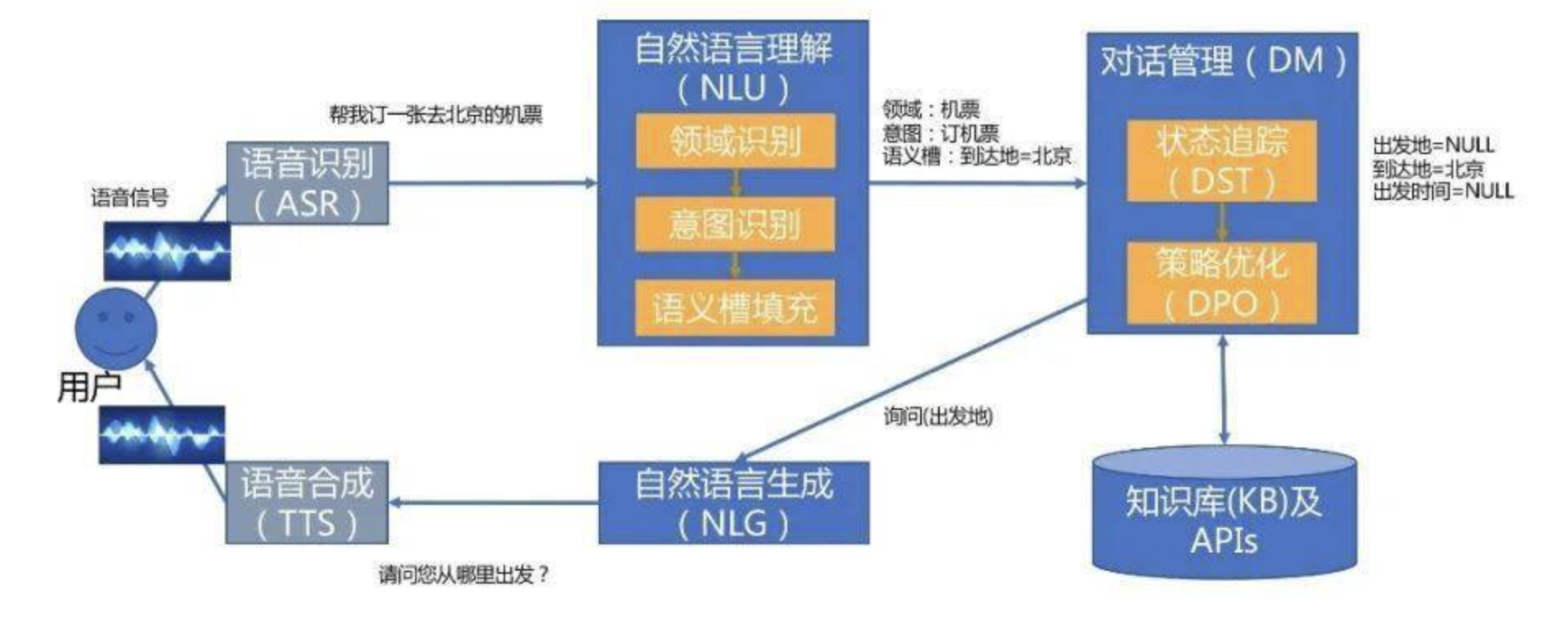

任务型对话系统分为语音识别、自然语言理解NLU、对话管理DM、自然语言生成NLG、语音合成几个部分。与NLP领域相关的是NLU、DM、NLG三个部分。本次报告详细描述的是NLU这个部分。
NLU是从用户输入的一句话中提取出领域、意图以及槽值三部分。通过领域识别和意图识别理解用户想要进行的操作。槽值填充,能够提取与意图相关的关键词。例如一句话:帮我订一张去北京的票。其领域是:机票,意图是:订机票,语义槽值有:到达地=北京。
NLU理解到的领域,意图、槽值,之后会给到DM模块,进行后续处理。DM模块往往也业务是强相关的。目前大多数系统通过堆规则的方式实现,可以借助有限状态机来实现。
领域识别和意图识别都是分类问题。槽值填充是序列标注问题。
; 1.2 数据集介绍
SMP2019 中文人机对话技术评测(The Evaluation of Chinese Human-Computer Dialogue Technology,SMP2019-ECDT),是由全国社会媒体处理大会(Social Media Processing,SMP)主办的,专注于以社会媒体处理为主题的科学研究与工程开发,为传播社会媒体处理最新的学术研究与技术成果提供广泛的交流平台。
本次使用的数据集共包含 2579个数据对,其中 2000个用于训练数据集,579个用于验证数据集。
原始数据样例:

原始数据是JSON结构。每条数据有文本、领域、意图,还有对应的槽的名称、以及槽值。例如数据中,文本=请帮我打开uc,领域=app,意图=LAUNCH,槽的名称=name,槽值=uc。
1.3 评价指标
对于领域分类、意图识别,我们采用准确率(acc)来评价,对于语义槽填充,我们通常采用F值来评价。对于domain,当预测的值与标准答案相同时即为正确。对于intent来说,当domain预测正确,且intent的预测的值与标准答案相同时才为正确。对于slots来说,我们采用F值作为评价指标,当预测的slots的一个key-value组合都符合标准答案的一个key-value组合才为正确(domain和intent的也必须正确)。
为了综合考虑模型的能力,我们通常采用句准确率(sentence acc)来衡量一句话领域分类、意图识别和语义槽填充的综合能力,即以上三项结果全部正确时候才算正确,其余均算错误。
在项目中我们将领域和意图一起识别,使用准确率acc评价。对于语义槽使用句准确率评价。在计算句准确率的时候没有考虑领域、意图的准确率。
2 技术方案梳理
2.1 模型目标
通常来说,实现一个对话系统中的 NLU 任务,要分三步,第一步领域识别,第二步意图识别 ,第三步槽值填充。如果不考虑未来系统中领域的扩展,我们可以将第一步和第二步合并起来,那么合并之后就有两步要做,第一步意图识别,第二步槽值填充(”三步并作两步”)。我们的目标是,进一步提高效率,同时完成意图识别和槽值填充这两个步骤(”两步合成一步”)。具体模型介绍参考论文参考:《BERT for Joint Intent Classifification and Slot Filling》。
2.2 模型介绍
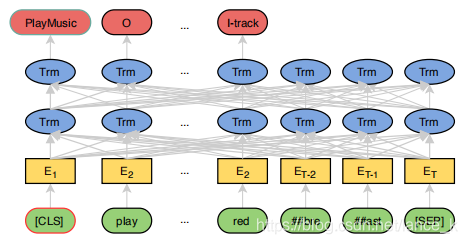
本次模型使用BERT+CRF完成NLU任务。BERT具体使用chinese-roberta-wwm-ext预训练模型。
BERT是一个机遇Transfer模型的多层双向self-attention Transformer 编码器结构。其输入部分由token embedding词嵌入向量、segment embedding句子编码向量以及position embedding位置编码向量三部分组成。这三部分相加组成了最终的BERT输入向量。
BERT使用Word Piece方式分词。对于中文而言,基本相当于单字分词。
本次任务的数据是单句分类。输入格式:[CLS] 句子[SEP]。
BERT模型输出层,CLS所对应的token被认为是代表了句子的向量。我们使用CLS的token进行领域-意图识别。每个单词对应的Token,代表了这个单词,用于槽值分类。
BERT是一种预训练模型。在BERT的输出层,加一层线性层,对CLS token计算,得到该句子在各个分类上的概率。
对于槽值分类我们使用BIO标记法。例如:
012345678CLS请帮我打开ucSEPOOOOOOB-nameI-nameO
在BERT的输出层,加一层线性层,计算各个词在所有槽值类型上的概率。一般来说这样也可以实现。但是BERT不能很好地捕捉时序之间的关系。如果能将这一步的输出,作为输入送入CRF模型中,CRF模型将能很好地学习到标签的依赖关系。所以对于槽值分类将使用BERT+线性层+CRF的结构。
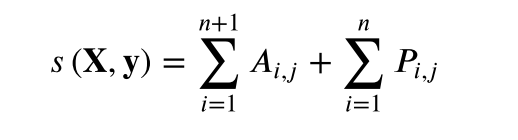
第一部分是标签依赖关系,是CRF学到的。第二部分是每个位置属于槽值分类的概率,由BERT+线性层模型学习。
; 2.3 模型实现
2.3.1 数据处理
需要将JSON格式的文件处理为后面方便读取的格式:app@launch 请帮我打开uc o o o o o b-name i-name
此外,将数据集分为训练集和验证集,数据量分别为2000、579。
提取出所有的领域-意图标签。
提取出所有的槽值标签。
这样就得到了train.tsv,test.tsv,cls_vocab,slot_vocab。在数据使用过程中会将标签数据都转小写。
train.tsv,test.tsv部分数据展示
cls_vocab部分数据展示
slot_vocab部分数据展示
; 2.3.2 构建dataset
按照2.2分析的模型构建数据集,使用[pad]做batch对齐。这里需要说明的是使用了pin_memory,可以在数据从CPU搬移到GPU的过程中继续做其他事情。
class PinnedBatch:
def __init__(self, data):
self.data = data
def __getitem__(self, k):
return self.data[k]
def pin_memory(self):
for k in self.data.keys():
self.data[k] = self.data[k].pin_memory()
return self
2.3.3 模型定义
模型定义基于BertPreTrainedModel,使用BERT预训练模型。
class NLUModule(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_intent_labels = config.num_intent_labels
self.num_slot_labels = config.num_slot_labels
self.use_crf = config.use_crf
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.intent_classifier = nn.Linear(config.hidden_size, config.num_intent_labels)
self.slot_classifier = nn.Linear(config.hidden_size, config.num_slot_labels)
self.crf = CRF(num_tags=config.num_slot_labels, batch_first=True)
self.init_weights()
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
slot_labels=None
):
r"""
labels (:obj:torch.LongTensor of shape :obj:(batch_size,), optional):
Labels for computing the sequence classification/regression loss.
Indices should be in :obj:[0, ..., config.num_labels - 1].
If :obj:config.num_labels == 1 a regression loss is computed (Mean-Square loss),
If :obj:config.num_labels > 1 a classification loss is computed (Cross-Entropy).
"""
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
pooled_output = outputs[1]
seq_encoding = outputs[0]
pooled_output = self.dropout(pooled_output)
intent_logits = self.intent_classifier(pooled_output)
slot_logits = self.slot_classifier(seq_encoding)
if self.use_crf and slot_labels is not None:
crf_loss = self.crf(slot_logits, slot_labels, mask=attention_mask.byte(), reduction='mean')
crf_loss = -1 * crf_loss
return intent_logits, slot_logits, crf_loss
else:
return intent_logits, slot_logits, None
2.3.4 训练相关参数
优化方式。优化方式使用Adm+warm up的方式。初始学习率8e-6,warmup=200。
loss计算。使用交叉熵损失mean计算loss。在计算槽值损失的时候要去掉mask的部分。当使用CRF层的时候,槽值损失就是CRF计算得到的损失。在计算总的损失的时候是将领域-意图损失+槽值损失。也可以为他们分配不同的比例。在项目中发现,如果不加CRF层,需要调整比例,模型才能学到更好的槽值分类。
使用batch_split,使用时间换空间策略。有时候我们的GPU内存不够大,每一个batch的数量不能很大(本项目中是30),这个时候可以多做几次前向传播,再做一次梯度更新。用更多的数据可以让梯度更新的值更准确,收敛得更快。
本项目中训练了30轮。每训练40步做一次验证。
2.3.5 训练结果
intent_loss=0.00402, intent_acc=1, slot_loss=0.0344, slot_acc=1
dev_intent_loss 0.2449, dev_slot_loss 0.0817, dev_intent_acc 0.9430, dev_slot_acc 0.8325
在本项目中,也做不了加CRF的训练。dev_intent_acc:0.9309,dev_slot_acc:0.8083。能够看出添加CRF对于槽值分类提高了2个百分点。
3 项目总结
NLU不但可以用在对话系统中,同样也可以用于知识图谱搜索中。当识别到用户的意图和槽值之后可以使用固定的搜索模板,填充槽值返回搜索结果。
本项目已经上传到git。框架代码来源于silverriver。CRF部分参考monologg。
Original: https://blog.csdn.net/flying_all/article/details/120091981
Author: 约定写代码
Title: 对话系统之NLU总结报告
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532133/
转载文章受原作者版权保护。转载请注明原作者出处!