

【ACL2021】Modeling Fine-Grained Entity Types with Box Embeddings
背景:
命名实体识别和实体类型的发展以在类型集上的大小和复杂性的增长为特征,这些类型通常遵循一些层次结构,因此,针对这些任务的有效模型经常明确地涉及这个层次结构。之前的系统通过层次性loss纳入了这种结构或通过嵌入类型到高维欧氏或双曲空间。然而,前一种方法需要类型层次结构的先验知识,这不适用于最近的一类大型类型集,其中层次结构并不明显。后一种方法,虽然利用双曲空间的归纳偏差来表示树,但缺乏对嵌入的概率解释,不能自然地捕获所有超出严格遏制的复杂类型关系。
神经实体类型模型通常将细粒度实体类型表示为高维空间中的向量,但这样的空间并不适合对这些类型的复杂相互依赖进行建模。
本文研究了box embeddings(将概念嵌入为d维超矩形)的能力,以捕获类型的层次结构,即使这些关系本来没有明确定义。 本文模型以box的形式表示类型和实体。
主要思路:
本文描述了一种在高维空间中用box嵌入表示实体类型的方法。本文构建了一个实体类型模型,将每个实体mention和实体类型联合嵌入到同一个box空间中,以确定它们之间的关系。boxes的体积对应于概率,取boxes的相交部分对应于计算联合分布,这使得能够建立mention-type关系(这个mention展示了什么类型?)和type-type关系(类型层次结构是什么?)的模型。
研究方法:
box可以嵌套、重叠或完全不相交,以捕获子类型、关联或分离关系,以及在欧氏空间中没有明确显示的属性。box计算的本质也允许这些复杂的关系在一个比基于向量的模型所需的更低维的空间中表示。相比于Euclidean空间中的点嵌入类型,box空间由于其几何属性,并且具有表现力,适合表示实体类型。


图1:mention和三个实体类型被嵌入到向量空间(左)和box空间(右)中。
box空间可以更充分更加自然地表示类型之间的层次性交互和mention属性的不确定性
box嵌入将实体类型表示为n维超矩形
; box embedding:
一个box x的特征是两个点( X m , X M ) (X_m, X_M)(X m ,X M ),其中X m , X M ∈ R d X_m, X_M∈R^d X m ,X M ∈R d是box x的最小角和最大角,对每个坐标i ∈ 1 , … d , X ( m , i ) ≤ X ( M , i ) i∈{1,…d},X_(m,i)≤X_(M,i)i ∈1 ,…d ,X (m ,i )≤X (M ,i ),b o x x box x b o x x的体积计算公式:

x和y两个盒子的交集体积定义为:V o l ( x ∩ y ) = ∏ i m a x ( m i n ( X ( M , i ) , Y ( M , i ) ) − m a x ( X ( m , i ) , Y ( m , i ) ) ) , 0 ) Vol(x ∩ y) = ∏i max (min(X(M,i), Y_(M,i)) − max(X_(m,i), Y_(m,i))), 0)V o l (x ∩y )=∏i m a x (m i n (X (M ,i ),Y (M ,i ))−m a x (X (m ,i ),Y (m ,i ))),0 )
可视为实体类型x和y的联合概率。因此,我们可以得到条件概率为:P ( y ∣ x ) = ( V o l ( x ∩ y ) ) / ( V o l ( x ) ) P(y | x) = (Vol(x∩y) )/(Vol(x) )P (y ∣x )=(V o l (x ∩y ))/(V o l (x ))
但本文为了软化box确保梯度流动,使用了Gumbel boxes来改进box嵌入的训练。
基于box的多标签类型分类器:
设s表示上下文词的序列,m表示s中一个实体mention范围。给定输入元组(m, s),实体类型模型的输出是任意数量的预测类型t 0 , t ( 1 , … . . ) ∈ T {t_0,t_(1,…..)}∈T t 0 ,t (1 ,…..)∈T
本来类别本身可能是多层级的,比如 “爬行动物”,”蛇”。这两个type的信息本身是一种包含关系。但是作者忽略这个信息,本文将实体类型视为一个多标签分类问题:

现在,假设box x x x已给出,那就可以通过类型box y k y^k y k去计算mention所属的第k个实体类型的概率,每个类型t k t^k t k都对应于一个box y k y^k y k,它由一个中心向量c y k c_y^k c y k 和一个偏移向量o y k o_y^k o y k 构成,
一个y k y^k y k的最小和最大角计算公式为:y m k = σ ( c y k − s o f t p l u s ( o y k ) ) , y M k = σ ( c y k + s o f t p l u s ( o y k ) ) y_m^k = σ(c_y^k − softplus(o_y^k )),y_M^k = σ(c_y^k + softplus(o_y^k ))y m k =σ(c y k −s o f t p l u s (o y k )),y M k =σ(c y k +s o f t p l u s (o y k ))
这个(m,s)属于类型t k t^k t k的条件概率为:


本文使用了Dasgupta等人(2020)的Gumbel box方法,box坐标被解释为一个方差为β的Gumbel max分布的位置参数。在这种方法中,交集处的box的坐标为:

并使用一个软加函数来近似Gumbel box的预期体积:

; 表示一个box只需要center&offset:
首先把上下文s和mention m格式化为x = [CLS] m [SEP] s [SEP],使用预训练的bert,我们通过在[CLS]处获取隐藏向量h,将整个序列编码为单个向量,一个high-way层会把隐藏向量h^([CLS])投影到 2d的空间,前d维代表中心,后d维代表偏移量。X m X M X_m X_M X m X M 的计算如下:

损失函数:
使用二分类交叉熵计算loss
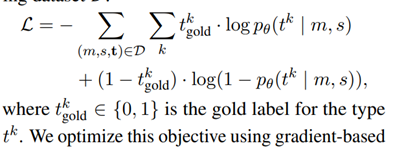
; 实验结果:
在本文实验中重点比较了基于box的模型和基于向量的baseline

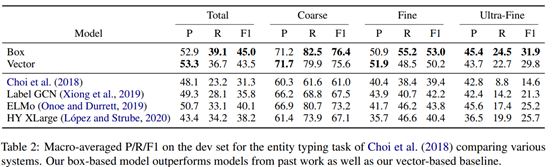


实验结果分析文中阐述较多,一些自己的观察:效果好,但是也没那么好,指标提升也没有特别大。Recall的提升比较大,但是precision可能会下降,使用box嵌入表示实体类型,鲁棒性更好。
参考:
https://zhuanlan.zhihu.com/p/409083354
Original: https://blog.csdn.net/qq_41202483/article/details/120818860
Author: 芝士Lillian
Title: 【论文阅读笔记】Modeling Fine-Grained Entity Types with Box Embeddings
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532069/
转载文章受原作者版权保护。转载请注明原作者出处!