

GPT模型
Paper:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-1
GPT-1是OpenAI在论文《Improving Language Understanding by Generative Pre-Training》中提出的生成式预训练语言模型。该模型的核心思想:通过二段式的训练,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。GPT-1可以很好地完成若干下游任务,包括分类、蕴含、相似度、多选等。在多个下游任务中,微调后的GPT-1系列模型的性能均超过了当时针对特定任务训练的SOTA模型。
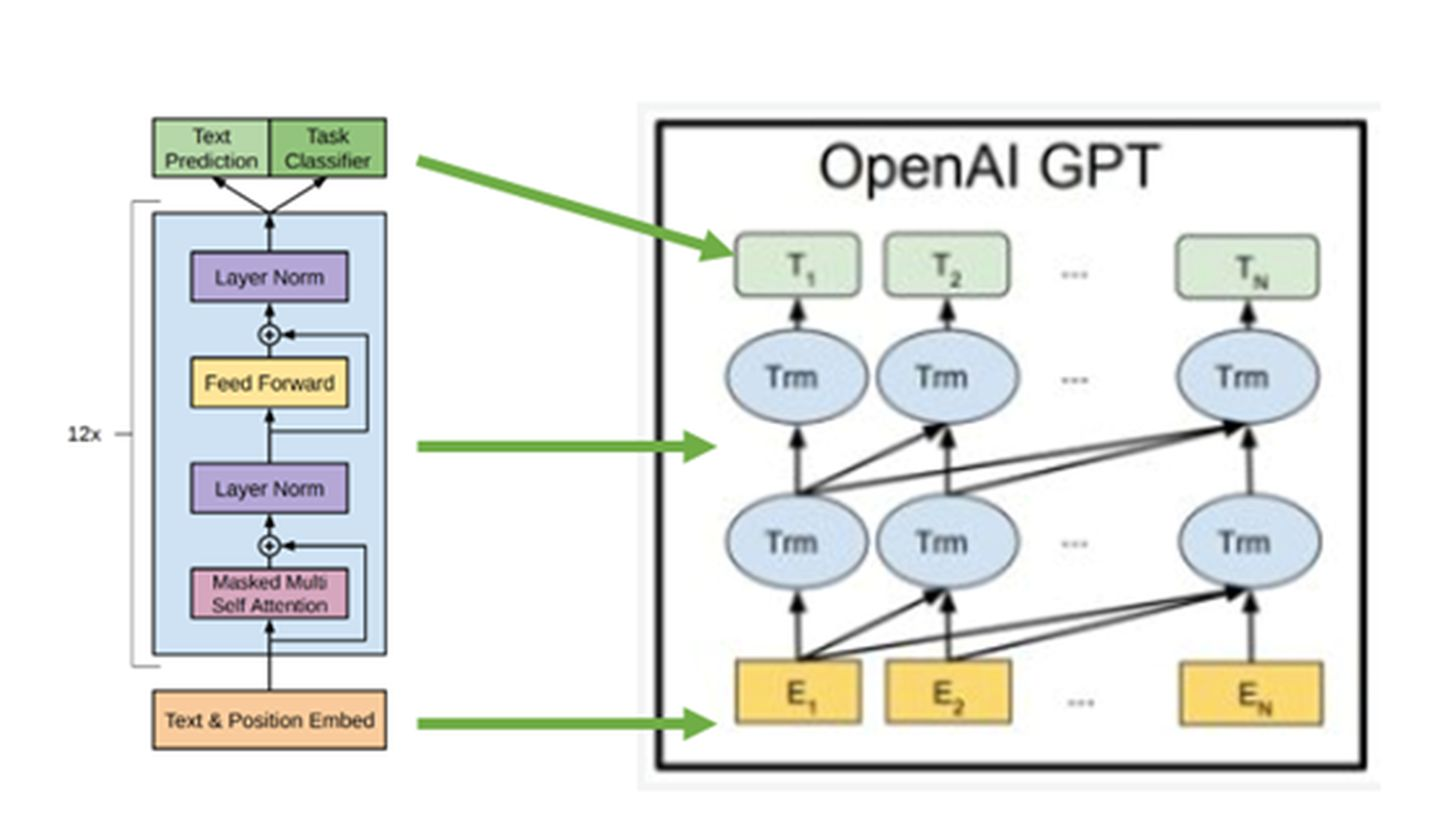
GPT-1的结构:基于Transformer Decoder

GPT-1在无然督训练阶段,依然采用标准的语言模型,即给定无标签的词汇集合u = { u 1 , . . . , u 2 } u={u_1,…,u_2}u ={u 1 ,…,u 2 },最大化以下似然函数:
L 1 ( u ) = ∑ i l o g P ( u i ∣ u i − k , . . . u i − 1 ; Θ ) L_1(u)=\sum_{i}^{}{logP(u_i|u_{i-k},…u_{i-1};\Theta)}L 1 (u )=i ∑l o g P (u i ∣u i −k ,…u i −1 ;Θ)
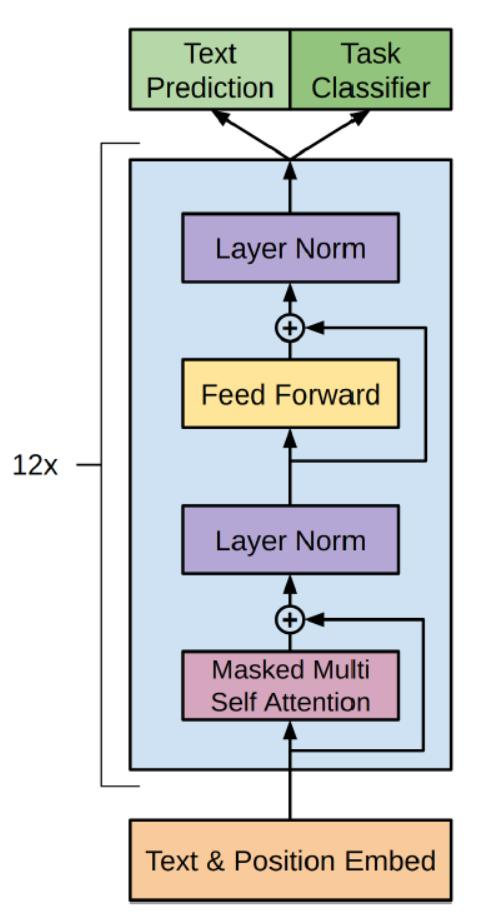
其中,k k k是上下文窗口的大小。在模型结构上,GPT-1选择了Transformer Decoder作为其主要组成部分。GPT-1由12层Transformer Decoder的变体组成,称其为变体,是因为与原始的Transformer Decoder相比,GPT-1所用的结构删除了Encoder-Decoder Attention层,只保留了Masked Multi-Head Attention 层和Feed Forward层。Transformer结构提出之始便用于机器翻译任务,机器翻译是一个序列到序列的任务,因此Transformer设计了Encoder用于提取源端语言的语义特征,而用Decoder提取目标端语言的语义特征,并生成相对应的译文。GPT-1目标是服务于单序列文本的生成式任务,所以含弃了关于Encoder部分,包括Decoder的 Encoder-Dcoder Atcnion层。
GBT保留了Decoder的Masked Multi-Atenlion 层和 Fed Forward层,并扩大了网络的规模。将层数扩展到12层,GPT-1还将Atention 的维数扩大到768(原来为512),将Attention的头数增加到12层(原来为8层),将Fed Forward层的隐层维数增加到3072(原来为2048),总参数达到1.5亿。GPT-1还优化了学习率预热算法,使用更大的BPE码表,活函数ReLU改为对梯度更新更友好的高斯误差线性单元GeLU,将正余弦构造的位置编码改为了带学习的位置编码。
GPT-1以Transfomer Decoder模型为主要结构,搭建语言模型骨架, 成为Transformer Block,扩大模型复杂度和相应的参数。GPT-1的数据流如下:
(1)输入语句的前k k k个词通过词表转化为一维向量U = { u − k , . . . , u − 1 } U={u_{-k},…,u_{-1}}U ={u −k ,…,u −1 }。
(2)输入U U U右乘权重矩阵W e W_e W e 和W p W_p W p 转化为转为特征向量h o h_o h o :
h o = U W e W p h_o=UW_eW_p h o =U W e W p
(3)经过12层Transformer Block,最终的语义特征向量h n ( n = 12 ) h_{n(n=12)}h n (n =1 2 )的计算公式为
h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) h_l=transformer_block(h_{l-1})h l =t r a n s f o r m e r _b l o c k (h l −1 )
(4)Softmax输出下一个词u u u的概率:
p ( u ) = S o f t m a x ( h n W e T ) p(u)=Softmax(h_nW^T_e)p (u )=S o f t m a x (h n W e T )
以上为无监督训练阶段语言模型的数据流,此阶段利用L 1 L_1 L 1 似然函数作为优化目标训练语言模型。在监督微调阶段,GPT-1采用附加的线性输出层作为针对不同任务的自适应层(每个自适应层都是并列关系,各自拥有的独立的权重矩阵W y W_y W y ,需要根据特定任务微调训练)。假定有带标签的数据集C C C,其中每个实例由一系列输入词x 1 , . . . , x 2 x^1,…,x^2 x 1 ,…,x 2和标签y y y组成。通过预训练的GPT-1先将输入转化为语义特征h l m h_l^m h l m (下标l表示层,上标m表示输入x m x^m x m对应的语义特征),再经过任务特定的线性输出层预测y y y:
P ( y ∣ x 1 , . . . , x m ) = S o f t m a x ( h l m W y ) P(y|x^1,…,x^m)=Softmax(h_l^mW_y)P (y ∣x 1 ,…,x m )=S o f t m a x (h l m W y )
而需要优化的目标函数也变为:
L 2 = ∑ x , y l o g P ( y ∣ x 1 , . . . , x m ) L_2=\sum^{}_{x,y}{logP(y|x^1,…,x^m)}L 2 =x ,y ∑l o g P (y ∣x 1 ,…,x m )
为了使微调训练后的模型有更好的泛化性能,在监督微调的优化目标函数中加入辅助优化函数是一个已被验证可行的方法,而且可以加速模型的微调收敛。在监督微调训练阶段,GPT-1使用的优化目标函数为
L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3(C)=L_2(C)+\lambda L_1(C)L 3 (C )=L 2 (C )+λL 1 (C )
其中,L L L是无监督训练阶段的目标函数,λ \lambda λ是辅助函数的权重常系整。总体来说,在GPT-1监督微调训练阶段,需要训练的最主要的额外权重矩阵就是W y W_y W y 。
; GPT-1下游任务微调
文本分类任务
可以通过带标签的文本分类数据,通过微调方法进行训练,让GPT-1学会文本分类。
输入文本:梅西宣布退役。标签:体育新闻
问答或者常识推理任务
虽然标签代表的文本与输入文本并没有因果关系,但语义上存在强关联,可以理解为预训练语言模型经过微调训练能够学会这样的映射。对于输入文本包含多个句子(有序的句子对、二元组、三元组)的任务。
问:今天天气怎么样?
答1: 今天多云转阴,气温23摄氏度。
答2: 今天适合去爬山。答3:周末天气很好。
正确选择:答1
对于由多个句子按照规定组合而成的数据格式,GPT-1显然无法通过更改其输入数据格式来匹配指定任务。将问答语句揉在一起作为输入序列的简单拼接方式存在明显的隐患,事实上,这样做也无法获得很好的微调效果。思考Self-Attention过程在以下输入语句上的表现:
常添天气怎么样?今天多云转阴,气温23摄氏度。今天适合去爬山。周末天气很好。
隐患一,虽然Self-Atcntion的计算过程不考虑词与词之间的距离,直接计算两个词的语义类联性:但是,位置编码会引入位置关系,人类语言学认知及实验结果均表明,距离越近的。因此,直接拼接的输入会导致相同的答案之间在不同的位置与问句产生不同的相关性,即答案之间存在不公平的现象。
隐患二,模型无法准确分割问句与多个答句,在本例中,模型带问号,或者答句内部存在句号,则会出现问题,例如:
怎么用一句话证明你是去过北京?北京干燥。而且北京风沙很大。北京冬天很冷。但是北京的烤鸭很好吃。
模型无法根据句号判断这是两个答案还是四个答案。
考虑到以上两个隐患,GPT-1采用遍历式方法(Traversal-style Approach)做输入数据预处理,从而将预训练语言模型应用于有序句对或者多元组任务。
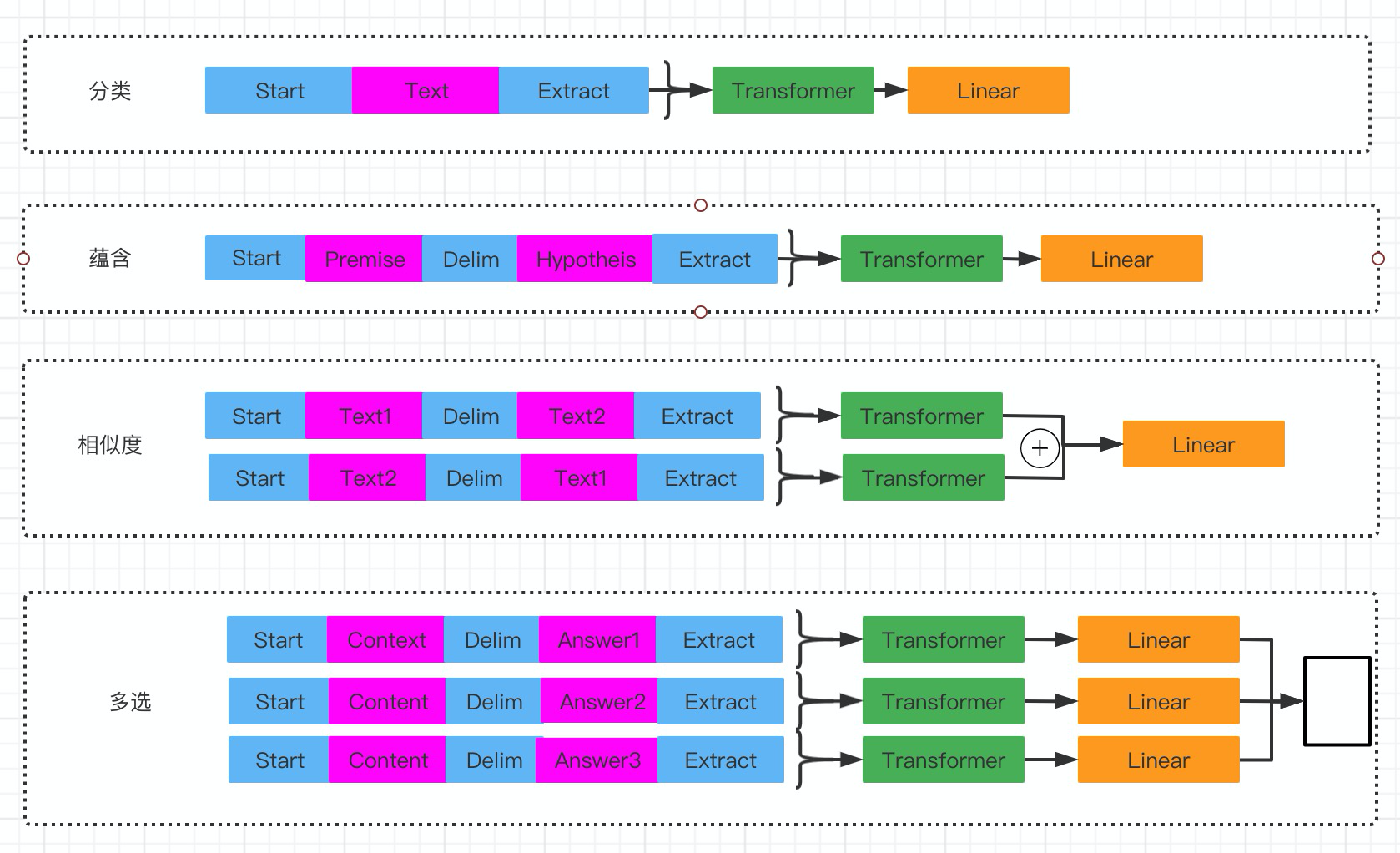
; 蕴含任务
(1)任务介绍:给定一个前提P(Pronise)根据这个前提推断假设H(Hypotheis),与前提P的关系,蕴含关系表示可以根据前提推理得到假设H,蕴含的任务就是计算在已知前提P的情况下,能推理得到假设H成立的概率值。
(2)人改写:顺序连接前提户和假设日,中间加入分隔符,如图A1中蓝色部分所示。
(3)样例:
~~体错我的球明天还你。$你的球在我这里。~~
相似度任务
(1)任务个绍:给定两个文本序列,判断两个序列的语义相似性,以概率表示(0~1)。
(2)输入改写:相似度任务中的两个文本序列并没有固定顺序,为了避免序列顺序对相似度计算造成干扰,生成两个不同顺序的输入序列,经过GPT-1主模型(12个Transfomer Block)后,得到语义特征向量h l m h_l^m h l m ,在输入至任务独有的线性层之前按元素相加。
(3)样例:
~~她很漂亮S她很好看~~
多选任务
(1)任务介绍:给定上下文文档Z Z Z(也可以没有)、一个问题Q Q Q(question)和一组可能的答案{ a k } {a_k}{a k }(answer),从可能的答案中选取最佳答案。
(2)输入改写:将上下文Z Z Z和问题Q Q Q连在一起作为前提条件,加入分隔符与每个可能的答案a k a_k a k 拼接,得到[ z ; q ; ; a k ] [z;q;;a_k][z ;q ;;a k ]序列。这些序列都用GPT-1单独进行处理(包括独有的线性层),最后通过Softmax 层进行规范化,在所有可能的答案上计算一个概率分布。
(3)样例:
~~今天天气怎么样?8今天多云转阴,气温23摄氏度。~~
GPT-2:Zero-shot Learning
机器学习中的三个概念:Zero-shot Learning(零样本学习)、One-shot Learning(单样本学习)和Few-shot Learming(少样本学习)。深度学习技术的迅速发展离不开大量高质量的数据,但在很多实际应用场景中,获取大量的高质量数据非常困难,所以模型能从少量样本中学习规律并具备推理能力是至关重要的。
核心思想
GPT-2的核心思想并不是通过二阶段训练模式(预训练+微调)获得特定自然语言处理任务中更好的性能。而是彻底放弃微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learning的设置下自己学会解决多任务的问题。与之相对的是,在特定领域进行监督微调的爱的专家模型并不具备多任务场景下的普适性。GPT-2在Zero-shot Learning设置下依然能够很好执行各种任务,证明了自然语言处理领域通用模型的可能性。
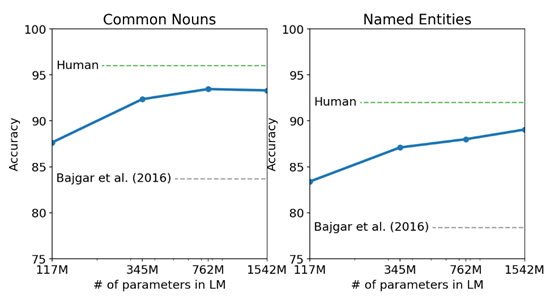
对于Zero-Shot问题,则需要考虑目标的风格以及分布情况,并实现一些训练集到测试集的映射(如处理特殊符号、缩写等),从而实现从已知领域到未知领域的迁移学习。GPT-2在Zero-Shot(尤其是小数据集Zero-Shot)以及长文本(长距离依赖)中都表现优异。下图为GPT-2在童书词性识别测试中的成绩:位于人类水平之下,但超过了之前模型的水平。
; 模型结构
与第一代GPT模型相I比,GPT-2在模型结构上改动极小、在复用GPT的基础上,GPT-2做了以下修改:
(1)LN层被放置在Self-Attention层和Feed Forward层前,而不是像原来那样后置。
(2)在最后一层Tansfomer Block后增加了LN层。
(3)修改初始化的残差层权重,缩放为原来的N \sqrt{N}N 。其中,N是残差层的数量。
(4)特征向量维数从768扩展到1600,词表扩大到50257。
(5)Transformer Block的层数从12扩大到48。
GPT-2有4个不同大小的模型,它们的参数如下:
总参数(M:百万)层数特征向量维数117M12768345M241024762M3612801542M481600
最小的模型其实就是第一代GPT,参数量也达到了1.17亿;而参数量高达15亿的最大模型,一般被称为GPT-2。GPT-2的不俗表现,证明它是一个极其优秀的预训练语言模型。
GPT-3:Few-shot Learning的优秀表现
与GPT-2在Zero-shot Learning设置下的惊喜表现相比,GPT-3在Few-shot Learning设置下的性能足以震惊所有人。在自然语言处理下游任务性能评测中,GPT-2在Zero-shot Learning设置下的性能表现远不如SOTA模型,而GPT-3在Few-shot Learning设置下的性能表现与当时的SOTA模型持平,甚至超越了SOTA模型。
GPT-3 的训练过程与 GPT-2 类似,但对模型大小、数据集大小与多样性、训练长度都进行了相对直接的扩充。关于语境学习,GPT-3 同样使用了与 GPT-2 类似的方法,不过 GPT-3 研究团队系统地探索了不同的语境学习设定。
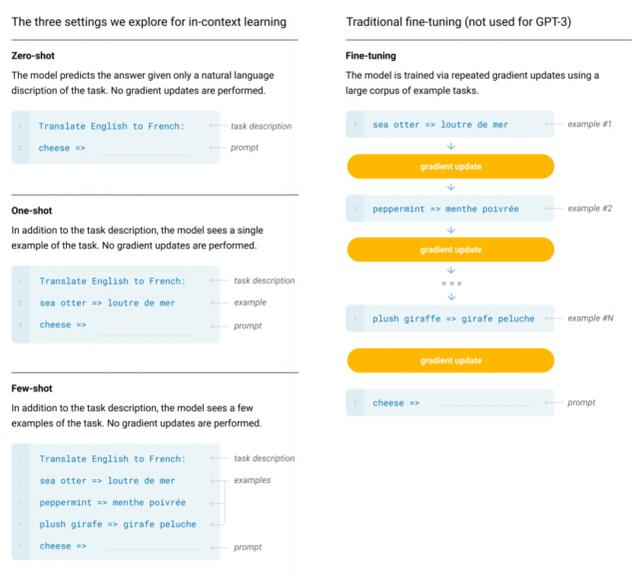
OpenAI 团队明确地定义了用于评估 GPT-3 的不同设定,包括 zero-shot、one-shot 和 few-shot。
Fine-Tuning (FT):微调是近几年来最为常用的方法,涉及在期望任务的特定数据集上更新经过预训练模型的权重;
Few-Shot (FS):在该研究中指与 GPT-2 类似的,在推理阶段为模型提供少量任务演示,但不允许更新网络权重的情形;
One-Shot (1S):单样本与小样本类似,不同的是除了对任务的自然语言描述外,仅允许提供一个任务演示;
Zero-Shot (0S):零次样本除了不允许有任何演示外与单样本类似,仅为模型提供用于描述任务的自然语言指示。
; 模型结构
使用了和 GPT-2 相同的模型和架构,包括改进的初始设置、预归一化和 reversible tokenization。 区别在于 GPT-3 在 transformer 的各层上都使用了交替密集和局部带状稀疏的注意力模式,类似于 Sparse Transformer。
GPT-3
(1)不具备真正的推理
(2)存在不良内容出现
(3)在高度程序化问题上表现不佳
参考
NLP模型应用之三:GPT与GPT-2
GPT-3
《预训练语言模型》邵浩
欢迎关注公众号:

Original: https://blog.csdn.net/weixin_42486623/article/details/119303820
Author: 发呆的比目鱼
Title: GPT模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532015/
转载文章受原作者版权保护。转载请注明原作者出处!