

文章目录
本文内容整理自深度之眼《GNN核心能力培养计划》
GCN在文本识别的应用
GCN文本分类
是一个半监督任务
主要参考的文章是:Graph Convolutional Networks for Text Classification,是2019 AAAI(Association for the Advancement of Artificial Intelligence)(CCF A类会议)发表的一篇文章
另外一篇2018 AAAI的文章是关于半监督学习的:Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning
模型over-smoothing问题
问题描述:当GCN的层数比较多的时候,会导致各个节点的embedding趋向于一致,从而失去了区分度的现象。
究其原因是,当卷积层数过深,那么就会相当把图中所有节点的信息都汇聚到每一个节点上,每个节点上丢集中了所有其他节点的信息,而所有的节点汇聚信息肯定都是一样的,因而每个节点的embedding结果就会非常类似,导致节点分类任务效果很差。
摘要
摘要套路分析:
文本分类这个任务很重要。
Text classification is an important and classical problem in natural language processing.
现在的解决方案是什么。
There have been a number of studies that applied convolutional neural networks (convolution on regular grid, e.g., sequence) to classification.
这里要有转折分析现有方法的缺点。
However, only a limited number of studies have explored the more flexible graph convolutional neural networks (convolution on
non-grid, e.g., arbitrary graph) for the task.
根据缺点,讲我们怎么做(创新点),总分法介绍开始:
总:In this work, we propose to use graph convolutional networks for text classification.
分:We build a single text graph for a corpus based on word co-occurrence and document word relations, then learn
a Text Graph Convolutional Network (Text GCN) for the corpus.
这里补充一下word co-occurrence and document word relations
word co-occurrence是用一个窗口大小的范围,分析两个词之间的共现次数,作为词与词之间的边的关系;
document word relations是指一个词在一个文章中的出现次数,作为词与整个文章边的关系。
分:Our Text GCN is initialized with one-hot representation for word and document, it then jointly learns the embeddings
for both words and documents, as supervised by the known class labels for documents.
实验结果(创新带来的结果)露一手,SOTA要亮出来(注意实验条件,一个模型不一定是全面超越前人的研究,这个模型的SOTA条件是直接用text GCN模型然后不用预训练词向量,得到效果最佳):
第一个贡献:Our experimental results on multiple benchmark datasets demonstrate that a vanilla Text GCN without any external word embeddings or knowledge outperforms state-of-the-art methods for text classification.
第二个贡献:On the other hand, Text GCN also learns predictive word and document embeddings. In addition, experimental results show that the improvement of Text GCN over state-of-the-art comparison methods become more prominent as we lower the percentage of training data, suggesting the robustness of Text GCN to less training data in text classification.
模型
文本或者说文章不是图结构的,先来看看如果把文章转化为图的形式。上面说了有两个东西要用来表示节点(词、文章)之间的关系:word co-occurrence and document word relations。
对于后者(document word relations)文章中也提到,光使用词频来表示权重是有失偏颇的(出现得多反而不怎么重要,类似【的】【地】等,但是一个词在某个文章中出现次数多,但是在其他文章中不多见,则可认为这个词对于这个文章非常重要。)
因此要引入TF-IDF,可以参考这里。
PS.之前我也写过,忘记在哪里了,谁能告诉我CSDN有没有搜索功能。
对于前者(word co-occurrence)文章使用了PMI(point-wise mutual information互信息)来计算。
有了边的关系,就可以根据原文公式3得到图的结构,也就是邻接矩阵A i j A_{ij}A i j 。
然后再用GCN来训练,文章中也用了一段篇幅来讲解为什么虽然文本和文本没有边,但是这个模型可以获取到文本和文本之间的关系(相似?不相似)
A two-layer GCN can allow message passing among nodes that are at maximum two steps away. Thus although there is no direct document-document edges in the graph, the two-layer GCN allows the information exchange between pairs of documents.
RGCN模型讲解
模型来自论文:Modeling Relational Data with Graph Convolutional Networks
模型的特点:
1.异质图经典baseline
2.GCN应用到异质图的经典模型
3.每个类型边对应一组神经网络参数
4.针对上面参数变多的特点,使用矩阵分解降低参数
模型主要用于两个任务:two fundamental SRL tasks: link prediction (recovery of missing triples) and entity classification (assigning types or categorical properties to entities).
举个例子:张三毕业于清华大学,那么可以推断张三在北京住过。因为清华大学位于北京。
KG天然就是图结构。
他的核心公式是原文公式2:
h i ( l + 1 ) = σ ( ∑ r ∈ R ∑ j ∈ N i r 1 c i , r W r ( l ) h j ( l ) + W 0 ( l ) h i ( l ) ) h_i^{(l+1)}=\sigma\left(\sum_{r\in R}\sum_{j\in N_i^r}\cfrac{1}{c_{i,r}}W_r^{(l)}h_j^{(l)}+W_0^{(l)}h_i^{(l)}\right)h i (l +1 )=σ⎝⎛r ∈R ∑j ∈N i r ∑c i ,r 1 W r (l )h j (l )+W 0 (l )h i (l )⎠⎞
其中W 0 ( l ) h i ( l ) W_0^{(l)}h_i^{(l)}W 0 (l )h i (l )表示当前节点本身self loop
R R R表示当前边类型r r r的集合
c i , r c_{i,r}c i ,r 是归一化项是当前节点i i i的邻居里面节点类型为r r r的节点数量,针对这一个类型的邻居进行归一化
N i r N_i^r N i r 是当前节点i i i的邻居里面节点类型为r r r的节点集合
W r W_r W r 表示不同边类型有自己的参数(特点3)
原文中还考虑边的方向:in/out
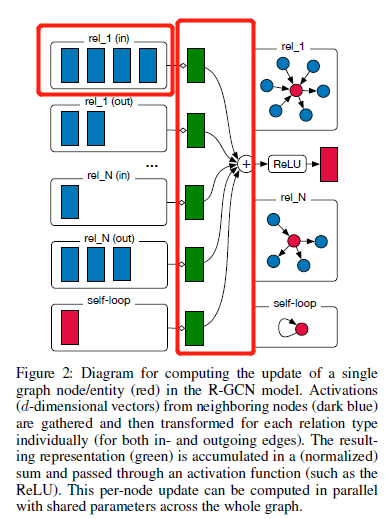

横着的红框代表里面的求和,竖着的红框代表外面的求和,最下面的红色那个是self loop。
可以看到由于每个类型都有一个W r W_r W r ,如果还考虑层数l = 2 l=2 l =2,那么参数还要翻倍,每层参数可以表示为:W r l W_r^l W r l ,数量非常大(参数多还会有过拟合的风险),原文在2.2节给出了使用矩阵分解的方式来解决这个问题的方案(公式3)。
Original: https://blog.csdn.net/oldmao_2001/article/details/118223742
Author: oldmao_2000
Title: 第四周.01.GCN文本分类及RGCN模型讲解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531953/
转载文章受原作者版权保护。转载请注明原作者出处!