

1.嵌入是用向量表示一个物体
2.用数值表示标识符,在机器学习领域称为 词嵌入 ,也称 分布式表示
3.词嵌入通常有两种方法——基于平台的Embedding学习,基于 预训练模型
4.word2vec是最开始提出的embedding预训练模型
5.word2vec有两种: CBOW 和 Skip-Gram
6.word2vec 数据集的一个样本 仅选输入词前后各c个词和输入词进行组合
7.word2vec利用神经网络进行权重更新
8. Hierarchical Softmax 和 negative sampling 是word2vec两种优化策略
嵌入,英文是Embedding,是用向量表示一个物体,这个物体可以是一个单词、一条语句、一个序列、一件商品、一个动作、一部电影等。在机器学习领域,我们把这些统一称为标识符(token),由于数学只认识数字,因此我们 用数值表示这些标识符,也即通常说的 词嵌入 ,又称为 分布式表示.
传送门:
最先开始的embedding是 word2vec,我们再详细介绍一次该算法,开始之前,先简单说明一下序列问题的处理步骤。


序列问题
序列,简单来说就是一串元素按照某种性质进行排列。比如数学常见的数列,还有生活中常见的网页浏览、商品浏览,按照时间生成的时间序列……
拿到一份语言材料,要对它进行任务工作,一般需要进行一定的特征工程,流程通常可以表示为下图:
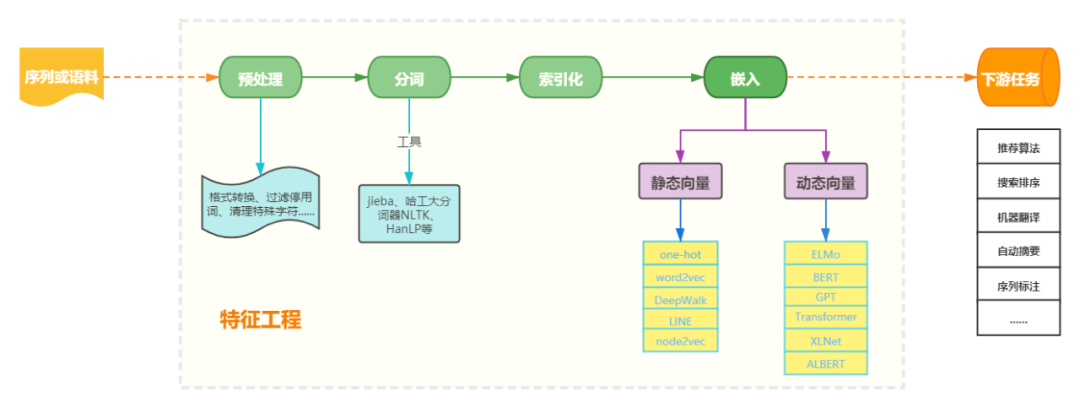
词嵌入是处理序列问题中最具魅力的一环,对于词嵌入的方法,通常有两种—— 1.利用平台的Embedding层学习,2.使用预训练的词嵌入
对于第一种方法,通过是利用PyTorch、TensorFlow等平台学习,首先初始化词向量,然后平台不断学习得到。比如PyTorch的简单Embedding:
import torch
import jieba
import numpy as np
from torch import nn
raw_text = '越努力越幸运'
words = list(jieba.cut(raw_text))
word_to_ix = {i:word for i,word in enumerate(set(words))}#索引化
embeds = nn.Embedding(4,3)
keys = word_to_ix.keys()
keys_list = list(keys)
tensor_value = torch.LongTensor(keys_list)
embeds(tensor_value)
第二种嵌入是预训练嵌入——利用较大语料库训练好的预训练模型,把词嵌入加载到当前任务中。预训练模型有很多,最原始的是word2vec,我们先展开介绍这个模型。

CBOW与Skip-Gram
word2vec实质分两种,一种是 根据上下文预测目标值,即Continuous Bag-Of-Words Model,简称 CBOW;另外一种是 根据目标值生成上下文,称为 Skip-Gram模型,我们在词嵌入(Word Embedding)文章中详细介绍了它的原理。这两种是相反的过程,我们举一个例子来说明Skip-Gram模型的具体过程,CBOW模型就不再赘述了。在此之前,再强调一下该模型的做出的三个假设:
- 一个词汇只与其上下文c个词汇有关(称为窗口,window size)
- 每个单词在窗口下的2c个单词的联合条件概率相互独立且同分布
- *给定每个单词,在窗口下每个单词的条件概率分布相互独立且同分布
对于下面语料库(句子):

natural language processing and machine learning is fun and exciting

首先,要将这条语句生成一个由序列(输入,输出)构成的数据集,假设取定window size = 2,那么这个 数据集的一个样本 仅选输入词前后各2个词和输入词进行组合 构成:
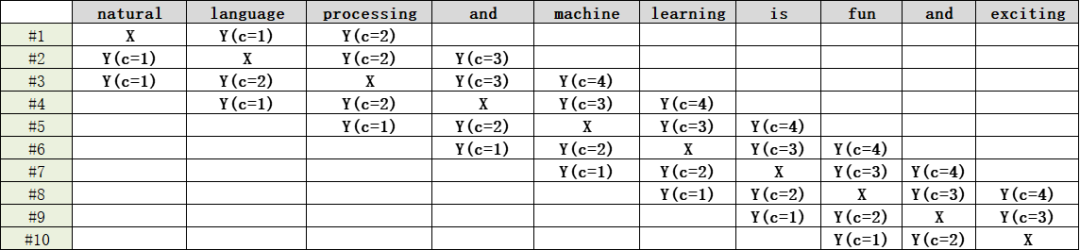
这条语句一共10个单词,所以数据集是由10个样本构成,从#1~#10.注意,输出标签y不再是一个文本,可能是两个,也可能是三个,这里最多是四个。
接着就是把这些文本变成数字形式表示,利用one-hot编码,虽然该语句一共10个单词,但只有9个互不相同的单词,所以每一个词向量维度应该是9。
我们列出#1~#5前五个样本的向量表示,剩下五个类推:
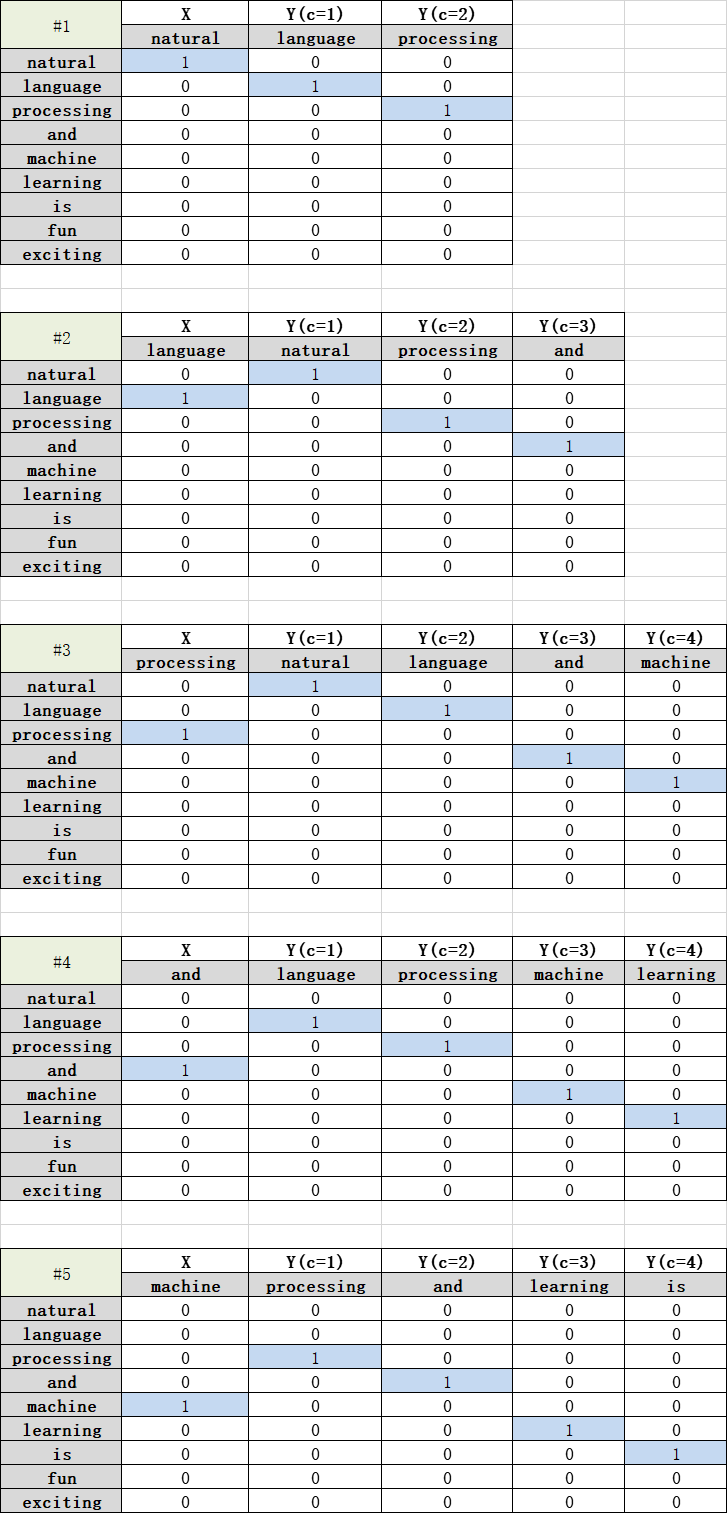
这样子,就从文本型语句转换为训练集的向量表示。
进行了预处理后的数据集,就可以输入神经网络进行训练,输入是X,输出是Y,隐藏层只有一层,由于输出向量维度是多维的,所以采取softmax激活函数,执行DNN的前向传播与反向传播,然后通过梯度下降更新 隐藏层系数矩阵W1和 输出层系数矩阵W2:

传送门:多层感知机(MLP)
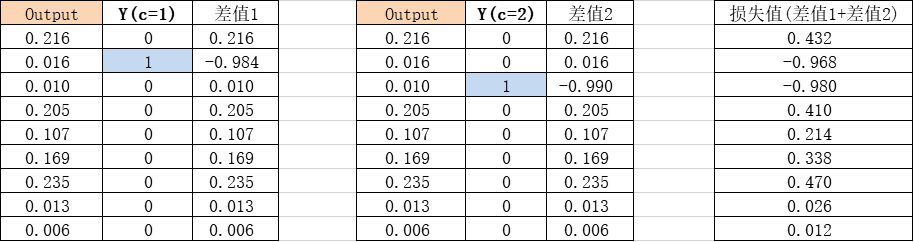
这里需要注意的是,由于输出的Y是多个的,在计算损失的时候是多个Y的和。这里以样本1举例,假设经过softmax输出层为:

由于样本的输出有两个,所以分布计算损失再求和(以残差为例):

word2vec优化策略
word2vec算法每次迭代要更新两个矩阵:隐藏层系数矩阵W1和输出层系数矩阵W2,如果词汇量V很大的时候,每次更新矩阵就要消耗巨大的资源,特别的是W2,还需要计算梯度。为了提高效率,word2vec有两种优化策略: Hierarchical Softmax和 Negative Sampling(负采样)。这两种策略出发点一致:不再显式使用W2矩阵,即不再完全计算或更新W2矩阵。
Hierarchical Softmax(简称HS)是用于加速神经语言模型Softmax的一种方式,HS的实质是 基于哈尔曼树(一种二叉树)将计算量大的部分变为一种二分类问题,它将 通过W2连接输出层改为隐藏层直接与下面二叉树根节点相连:

这里,白色的叶子节点代表词汇表所有的词汇(假设长度为V),黑色节点表示非叶子节点。用n(w,j)表示从根节点到叶子节点w的路径上的第j个非叶子节点,并且每个非叶子节点对应一个与隐藏层维度相同的向量。
训练一个神经网络意味着要输入训练样本并不断调整神经元权重, 每训练一个样本,该样本的权重就会调整一次,从神经网络训练流程可以看出来:

词汇表的大小决定了Skip-Gram神经网络权重矩阵的具体规模,这些权重需要经过上亿次的训练样本来调整,这需要非常消耗资源,在实际中效率会非常低下。而 负采样只需要每次更新一个训练样本的一小部分权重,并且能改善所得到的词向量的质量。
word2vec的 负样本是one-hot编码后的为0的那些位置的样本,每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。
参考资料:
《深入浅出Embedding》
Original: https://blog.csdn.net/qq_27388259/article/details/118257571
Author: 整得咔咔响
Title: 详解word2vec
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531794/
转载文章受原作者版权保护。转载请注明原作者出处!