

文章目录
transformers实践:基于BERT训练自己的NER模型
基于训练好的BERT进行迁移NER的原理如下:
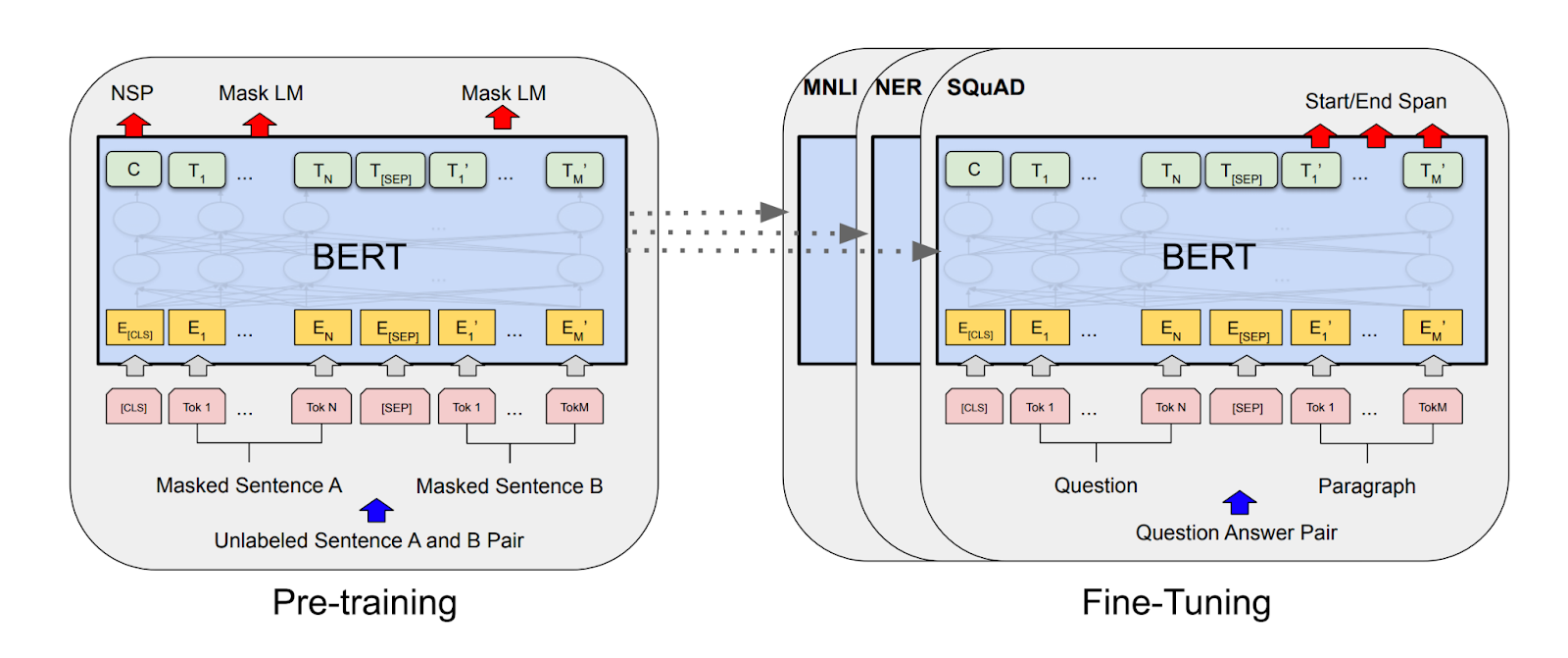

官方样例集成的很好,直接运行run_ner.py即可,下面对几个步骤(数据预处理、运行参数、模型调用)做下补充说明
; 数据集处理
run_ner.p中train_file要求的格式样例,如
https://github.com/huggingface/transformers/blob/master/tests/fixtures/tests_samples/conll/sample.json
{"words": ["痛", "1", "天", "。"], "ner": ["B-SIGNS", "O", "O", "O"]}
{"words": ["痛", "5", "天", "。"], "ner": ["B-SIGNS", "O", "O", "O"]}
数据集1:CCKS 2020:面向中文电子病历的医疗实体及事件抽取(一)医疗命名实体识别的原始数据集的格式为:
{
"train": [
[
[
"女",
"O"
],
[
"性",
"O"
],
[
",",
"O"
],
[
"8",
"O"
],
[
"8",
"O"
]
]
]
}
数据集2:
天池竞赛CBLUE数据集转换
中文医疗信息处理挑战榜CBLUE(Chinese Biomedical Language Understanding Evaluation)数据集
"text": "患者缘于1小时前不慎伤及腰部,伤后疼痛,腰部活动受限,未"
"entities": [
{
"start_idx": 12,
"end_idx": 13,
"type": "BODY",
"entity": "腰部"
},
分别对应下面两个转换函数
def convert_array_to_conll(fname, out_file=None):
with open(fname, 'rt') as f:
c = json.load(f)
for k, v in c.items():
out = []
for sentence in v:
words = list(map(lambda x: x[0], sentence))
ner = list(map(lambda x: x[1], sentence))
out.append({"words": words, "ner": ner})
if out_file is None:
out_file = fname.replace('.json', '_' + k + '_t.json')
with open(out_file, 'a') as f:
for x in out:
f.write(json.dumps(x, ensure_ascii=False)+'\n')
def convert_simple_to_conll(fname, out_file=None):
"""把简介模式的格式转换为conll格式
"text": "患者缘于1小时前不慎伤及腰部,伤后疼痛,腰部活动受限,未"
"entities": [
{
"start_idx": 12,
"end_idx": 13,
"type": "BODY",
"entity": "腰部"
},
转换为:
{"words": ["痛", "1", "天", "。"], "ner": ["B-SIGNS", "O", "O", "O"]}
{"words": ["痛", "5", "天", "。"], "ner": ["B-SIGNS", "O", "O", "O"]}
"""
with open(fname, 'rt') as f:
c = json.load(f)
out = []
for x in c:
text = list(x['text'])
ner = ['O']*len(text)
for e in x["entities"]:
# print(x['text'],text,len(ner),e)
_type = e['type'].upper()
ner[e['start_idx']] = 'B-'+_type
ner[e['start_idx']+1:e['end_idx']+1] = ['I-'+_type] * \
(e['end_idx']-e['start_idx'])
out.append({"words": text, "ner": ner})
if out_file is None:
out_file = fname.replace('.json', '_t.json')
with open(out_file, 'a') as f:
for x in out:
f.write(json.dumps(x, ensure_ascii=False)+'\n')
训练过程
上一步预处理后的数据集就可以拿来训练了,如下
python run_ner.py \
--model_name_or_path bert-base-chinese \
--train_file train_data_train_t.json \
--validation_file train_data_test_t.json \
--output_dir ./tmp/ner1 \
--do_train \
--do_eval
默认的epoch为3,模型输出到./test-ner目录,就可以直接通过from_pretrained加载了
另外也支持no Trainer方式:
export TASK_NAME=ner
python run_ner_no_trainer.py \
--model_name_or_path bert-base-chinese \
--train_file train_data_train_t.json \
--validation_file train_data_test_t.json \
--task_name $TASK_NAME \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir ./tmp/$TASK_NAME/
但这种方式输出的目录只有两个文件:config.json和pytorch_model.bin,只能通过from_pretrained加载模型,而且还要手工补文件
也可以定义更多个性化的训练参数
python run_ner.py \
--model_name_or_path bert-base-chinese \
--train_file CMeEE_dev_t.json \
--validation_file CMeEE_train_t.json \
--output_dir ./tmp/CMeEE \
--save_steps 2000 \
--logging_steps 200 \
--eval_steps 500 \
--evaluation_strategy steps \
--num_train_epochs 21 \
--do_train \
--do_eval
运行流程如下:
- 读取参数说明Training/evaluation parameters TrainingArguments
- datasets.builder
- 下载,生成json数据,保存在缓冲 /root/.cache/huggingface/datasets/
- configuration_utils.py
- 加载模型的config.json,结合数据集进行调整(没看明白为何写两遍日志)
- tokenization_utils_base.py
- 加载vocab.txt
- 加载tokenizer.json
- 加载added_tokens.json 可以为空
- 加载special_tokens_map.json 可以为空
- 加载tokenizer_config.json
- modeling_utils.py:
- 加载pytorch_model.bin
- 缓冲处理后的数据集
- trainer.py开始训练
模型的调用和使用
首先设置环境变量USE_TORCH,表示使用的是pytorch版(USE_TF表示使用tensorflow)
import os
os.environ['USE_TORCH']="1"
import torch
加载训练好的模型
from transformers import AutoModelForTokenClassification, AutoTokenizer
pretrained_model ='./transformers/examples/pytorch/token-classification/tmp/CMeEE/'
tokenizer = AutoTokenizer.from_pretrained(pretrained_model)
model = AutoModelForTokenClassification.from_pretrained(pretrained_model)
进行推理
sequence='遇有发热、咽峡炎和淋巴结肿大三联症,血中淋巴细胞增多并出现异淋时,称传染性单核细胞增多症(infectiousmononucleosis,IM;简称传单)。'
print(tokenizer.decode(tokenizer.encode(sequence)))
tokens = tokenizer.tokenize(tokenizer.decode(tokenizer.encode(sequence)))
inputs = tokenizer.encode(sequence, return_tensors="pt")
outputs = model(inputs)
outputs= outputs.logits
predictions = torch.argmax(outputs, dim=2)
for token, prediction in zip(tokens, predictions[0].numpy()):
print((token, model.config.id2label[prediction]))
结果如下:
[CLS] 遇 有 发 热 、 咽 峡 炎 和 淋 巴 结 肿 大 三 联 症 , 血 中 淋 巴 细 胞 增 多 并 出 现 异 淋 时 , 称 传 染 性 单 核 细 胞 增 多 症 ( infectiousmononucleosis , [UNK] ; 简 称 传 单 ) 。 [SEP]
('[CLS]', 'O')
('遇', 'O')
('有', 'O')
('发', 'B-DIS')
('热', 'I-DIS')
('、', 'O')
('咽', 'B-DIS')
('峡', 'I-DIS')
('炎', 'I-DIS')
('和', 'O')
('淋', 'B-DIS')
('巴', 'I-DIS')
('结', 'I-DIS')
('肿', 'I-DIS')
('大', 'I-DIS')
('三', 'O')
('联', 'O')
('症', 'O')
(',', 'O')
('血', 'O')
('中', 'O')
('淋', 'B-BOD')
('巴', 'I-BOD')
('细', 'I-BOD')
('胞', 'I-BOD')
('增', 'I-SYM')
('多', 'I-SYM')
('并', 'O')
('出', 'O')
('现', 'O')
('异', 'I-SYM')
('淋', 'I-SYM')
('时', 'O')
(',', 'O')
('称', 'O')
('传', 'B-DIS')
('染', 'I-DIS')
('性', 'I-DIS')
('单', 'I-DIS')
('核', 'I-DIS')
('细', 'I-DIS')
('胞', 'I-DIS')
('增', 'I-DIS')
('多', 'I-DIS')
('症', 'I-DIS')
('(', 'O')
('in', 'B-DIS')
('##fe', 'I-DIS')
('##ct', 'I-DIS')
('##ious', 'I-DIS')
('##mon', 'I-DIS')
('##on', 'I-DIS')
('##uc', 'I-DIS')
('##le', 'I-DIS')
('##os', 'I-DIS')
('##is', 'I-DIS')
(',', 'O')
('[UNK]', 'B-DIS')
(';', 'O')
('简', 'O')
('称', 'O')
('传', 'B-DIS')
('单', 'I-DIS')
(')', 'O')
('。', 'O')
('[SEP]', 'I-DIS')
附:两个数据集说明:
相同模型,对下列数据集的的测试结果为:
CCKS 2020:面向中文电子病历的医疗实体及事件抽取(一)医疗命名实体识别 的运行情况
***** train metrics *****
epoch = 3.0
***** eval metrics *****
eval_accuracy = 0.9776
eval_f1 = 0.9275
eval_loss = 0.0872
eval_precision = 0.9175
eval_recall = 0.9377
eval_runtime = 0:00:02.22
eval_samples = 57
eval_samples_per_second = 25.644
eval_steps_per_second = 1.8
中文医疗信息处理挑战榜CBLUE(Chinese Biomedical Language Understanding Evaluation)数据集 的运行情况
***** train metrics *****
epoch = 20.0
train_loss = 0.0231
train_runtime = 0:25:01.89
train_samples = 10000
train_samples_per_second = 133.165
train_steps_per_second = 8.323
***** eval metrics *****
epoch = 20.0
eval_accuracy = 0.8211
eval_f1 = 0.5732
eval_loss = 1.7064
eval_precision = 0.5383
eval_recall = 0.6129
eval_runtime = 0:01:08.33
eval_samples = 15000
eval_samples_per_second = 219.501
eval_steps_per_second = 13.726
发现CCKS的数据质量明显高于CBLUE
附:参考
- https://huggingface.co/transformers/task_summary.html#named-entity-recognition
- https://huggingface.co/transformers/training.html
Original: https://blog.csdn.net/lichangzhen2008/article/details/119946739
Author: 钢铁峡
Title: transformers实践:基于BERT训练自己的NER模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531736/
转载文章受原作者版权保护。转载请注明原作者出处!