

2021SC@SDUSC
本文我们将分析create_vocabulary.py文件,该文件主要的功能是创立了一个词典,统计了文本的所有词和词对应的索引,以便后续的指标的计算和处理,将得到的结果保存到vocab_kp20k.npy文件中。首先我们来看一下该文件的结构。
一、create_vocabulary.py结构
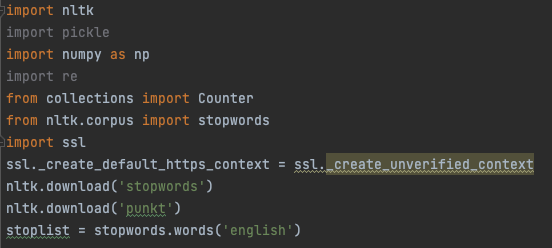

图1:create_vocabulary.py的第一部分和相关资源的下载
首先是一些包的引入,Counter基于可迭代对象实现计数,我们将依次对每个词计数,依旧是引入了nltk包,里面有很多自然语言处理相关的函数接口。通过nltk下载了英文的stopwords停词赋给stoplist,stopwords一般指没有实意的词,如英文语句中的the,is等。
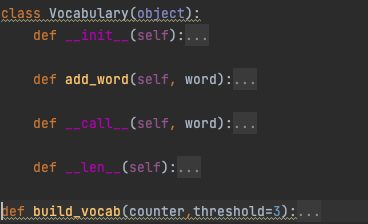
图2:create_vocabulary.py的第二部分
第二部分写了一个类Vocabulary,是对词典的一个封装,提供了对词典进行处理的相关函数。
- init函数:vocabulary对象的初始化函数
- add_word函数:实现了向词典对象中添加词及相应索引
- call函数:查找词典中是否有word单词,若没有返回unk,若有单词,返回单词的索引
- len函数:返回词典的长度,即一共收纳了多少词
之后还写了build_vocab函数,该函数完成了词典的构造,设置了阈值为3,即只记录语料中出现了超过三次的单词。里面会有对vocabulary对象的相关处理。
代码的第三部门就是main函数的实现和对结果的保存,将在下文仔细分析。
二、关于create_ vocabulary_demo.py的分析
在分析源文件之前, 我们先来分析一个创建词典的demo文件以大致了解词典创建的思路和方法。我们采用测试文本test.txt进行词典demo的构建,该测试文本选自wiki文本数据的一小部分,只是为了演示demo,因此这里不再设置阈值,而是列出所有出现的单词。测试文本的内容见下图。

图3:test.txt
将test.txt与create_ vocabulary_demo.py放在同一目录下后读入测试文件,开始词典的构建,create_ vocabulary_demo.py的完整代码如下。
import string
filename=open('test.txt')
打开测试文本
filelines=filename.readlines()
按行读入
filename.close()
word_cnt={}
初始化word_cnt为空词典
for line in filelines:
line=line.rstrip()
line=line.lower() # 将所有单词转为小写处理
word_list=line.split(" ") # 以空格作分词处理
for word in word_list:
if word in word_cnt:
word_cnt[word]+=1
else:
word_cnt[word]=1
result=sorted(word_cnt.items(),key=lambda d:d[1],reverse=True) #将结果按词频降序排列
print(result) # 输出构造的词典
对于test.txt中的每一行,首先将英文转为小写统一处理,再以分词得到了由一个一个英语单词组成的列表word_list,这里没有用stopwords对一些停词进行处理。之后构造词典,对于列表word_list中的每一次词word(也就是列表中的元素),若它还未出现在词典word_cnt中,就在词典中加入该词并令其出现次数为1,若已出现,则令其出现次数加一。
我们来分析将结果排序的那一行代码,首先这里用了一个迭代器,dict.items()——an interator over the (key, value) items of D,之后用到了匿名函数。lambda x:x+1表示若输入为x,将其转化为x+1输出,这里lambda d:d[1]表示若访问(key,value),则输出value(即d[1],d[0]表示key)。这里的d可以是任意变量名,用作指代dict.items()返回的变量。reverse=True表示按值进行从大到小的排序;reverse=False表示按值进行从小到大的排序。
demo的输出结果如下:

图4:create_ vocabulary_demo.py的输出结果
三、关于Vocabulary类的分析
在分析了demo之后,我们就很容易分析源文件了。不过需要注意的是,这里并不统计每个词出现了多少次,而是希望给每个词一个索引,用pyhton词典的方式,可以用索引找到单词,也可以用单词找到索引。我们首先分析vocabulary类。
class Vocabulary(object):
def __init__(self):
self.word2idx = {} # 字典 词到索引的映射
self.idx2word = {} # 字典 索引到词的映射
self.idx = 0 # 初始化索引为0
首先是初始化的init函数,这里首先将idx初始化为0, 也就是词典中还没有单词。有两个词典一个是word2idx用来是词找索引,idx2word用索引找词,都初始化为空。
def add_word(self, word):
if not word in self.word2idx: # 如果词到索引的映射字典中 不包含该词 则添加
self.word2idx[word] = self.idx
self.idx2word[self.idx] = word # 同时创建索引到词的映射
self.idx += 1 # 索引自增
add_word函数向词典中添加单词,如果参数word不在集合word2idx中,则将word2idx映射的词典中增加key为word的一个词,并将value(也就是word的索引)设置为idx,之后完成索引idx的自增,同时idx2word的映射中key为idx,value为加入的词word。如果参数word已经在word2idx词典中,则不执行if语句,返回不做操作。
def __call__(self, word):
if not word in self.word2idx: # 词典里没有记录该词
return self.word2idx['']
return self.word2idx[word] # 返回词到索引的映射结果
如果传入的参数word不在word2idx中。返回unk的索引,如果存在word单词,返回 word2idx的结果,也就是这个word的索引。
def __len__(self):
return len(self.word2idx)
#词到索引映射的字典大小
返回word2idx的词典长度,也就是有多少个单词。
四、关于build_vocab方法的分析
def build_vocab(counter,threshold=3): #传入计数器和阈值
# Ignore rare words
words = [[cnt,word] for word, cnt in counter.items() if ((cnt >= threshold))]
words.sort(reverse=True) # 按出现频次排序
words = [e[1] for e in words[:50000]] # 取出现频次最高的50000个单词
f = open('vocab_file.txt','w')
# Create a vocabulary and initialize with special tokens
vocab = Vocabulary()
vocab.add_word('')
vocab.add_word('')
vocab.add_word('')
vocab.add_word('')
# Add the all the words
for i, word in enumerate(words): # 将word加入字典中,调用add_word方法
vocab.add_word(word)
return vocab
我们先分析创建Vocabulary类的代码,该段代码创建了vocabulary对像并用一些特殊的tokens做初始化。
Create a vocabulary and initialize with special tokens
vocab = Vocabulary()
vocab.add_word('')
vocab.add_word('')
vocab.add_word('')
vocab.add_word('')
调用vocabulary的add_word方法,该方法会同时修改word2idx和idx2word字典,加入特殊的词start、end、pad、unk。可以知道,词典中索引为0的word就是最先加入词典的start,unk就是当词典中查不到传入的word时返回的特殊token。
Ignore rare words
words = [[cnt,word] for word, cnt in counter.items() if ((cnt >= threshold))]
words.sort(reverse=True) # 按出现频次排序
words = [e[1] for e in words[:50000]] # 取出现频次最高的50000个单词
f = open('vocab_file.txt','w')
build_vocab需要传入counter计数器和阈值,默认阈值为3。counter计数器记录了每个词和它出现的频次,通过取counter.items()取出词和计值,以列表形式返回words,里面每一项记录了词频和词,注意在这一步构造中有一步筛选,即只取出现了大于等于threshold次数的词。然后将得到的结果words按降序排列,由于words的每一项也是[词频,词]的列表形式,取出后一部分真正的word部分,并只取排列后的前50000名,再次进行一次过滤。
Add the all the words
for i, word in enumerate(words): # 将word加入字典中,调用add_word方法
vocab.add_word(word)
return vocab
过滤掉出现频次不高的词后建立了一个enumerate,i是索引、word是words中真正的词,这里直接取words加入到vocab中,最后该函数返回vocab对象。
五、关于main函数的分析
if __name__ == '__main__':
emb = dict()
f = open('glove.6B.200d.txt','r',encoding='gbk') # 打开glove.6B.200d.txt
e = f.readline() # 按行读入打开的文件
while e:
line = e.split(' ') # 以空格分割,返回list对象
emb[line[0]] = line[1:]
# line[0]为实际word,设置为key,line[1:]为value,实际的向量
e = f.readline() # 读取下一行
依旧一段一段分析代码,这里是先新建了一个字典emb,然后打开glove.6B.200d.txt文件,读入文件的每一行后,对每一行split分割后返回分割完的列表对象,词典的key是line[0]也就是真正的词word,其value也就是编码就是line[1:]即列表第一个位置后的元素,(我将会大致演示这一过程便于理解)然后再读取下一行直到读完。
GloVe是一种用于获取单词向量表示的无监督学习算法。对来自语料库的聚合的全局词-词共现统计进行训练,得到的表示展示了词向量空间有趣的线性子结构。
这里glove.6B.200d.txt是200d的常用英文单词的词向量。其内容大致如下,可以看到,split之后列表的第一个元素是常用的英语单词,其中the在第一个,后面还有of、to、and等词。line经过split之后返回列表,所以line[0]就是英语单词,line[1:]就是实际的向量,将它们分别赋给dict的key与value。

图5:glove.6B.200d.txt分词后的内容
corpus = list(np.load('document.npy', allow_pickle=True))
counter = Counter() #初始化一个counter对象
i = 0
for sent in corpus:
# sent = sent[1]
tokens = sent.split() # 分割得到tokens
# tokens.extend(q.split())
# tokens = nltk.tokenize.word_tokenize(sent.lower())
counter.update(tokens) # 更新counter
vocab = build_vocab(counter) # 传入counter对象,生成字典
np.save('vocab_kp20k.npy', vocab) # 保存vocab对象
这里是load了document.npy后转为list赋给corpus,然后初始化了一个计数器对象。对于corpus中的每一个元素,先用split分割,然后更新计数器对象。经历完for循环后,得到了所有词和对应的出现频率。最后将counter对象作为参数调用bulid_vocab方法。将返回的vocab对象保存为vocab_kp20k.npy以便后续使用。
Original: https://blog.csdn.net/OceanOcean123/article/details/121410727
Author: OceanOcean123
Title: 无监督关键短语的生成问题博客07–create_vocabulary.py的分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531718/
转载文章受原作者版权保护。转载请注明原作者出处!