

原文作者:Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit
原文标题:Attention is all you need
原文来源:NIPS 2017
原文链接:https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Attention is all you need
主流序列转导模型基于复杂的CNN或RNN,包括编码器和解码器。有的模型使用注意力机制连接编码器和解码器,达到了最优性能。本文提出了一个仅基于注意力机制的网络架构,Transformer。实验表明,该模型需要的训练时间明显减少,性能更好。
模型架构
文中使用了经典的encoder-decoder架构。Encoder将输入序列转化成一个固定维度的稠密向量。decoder将之前生成的固定向量再转化成输出序列。
encoder
文中的encoder由n个相同层组成。每层有两个子层:第一个子层是一个多头自注意力机制,第二子层是一个简单的位置全连接前馈网络。另外在每个子层间使用残差连接,然后进行层归一化。每个子层的输出为
LayerNorm ( x + Sublayer ( x ) ) \text{LayerNorm}(x + \text{Sublayer}(x))LayerNorm (x +Sublayer (x ))
模型中的所有子层,包括嵌入层的维度为512。
decoder
Decoder同样由n个相同层组成。除了encoder中的两个子层外,decoder还增加了一个子层:对encoder层的输出执行多头注意力。另外对自注意力子层进行修改(Mask),防止某个position受后续的position的影响。确保位置i的预测只依赖于小于i的位置的已知输出。


; Attention机制
注意力函数将query(Q)和一组键值对(K、V)映射为输出,Q、K、V都是向量。对V进行加权求和得到输出,每个V的权值通过Q和K的相似度得到。
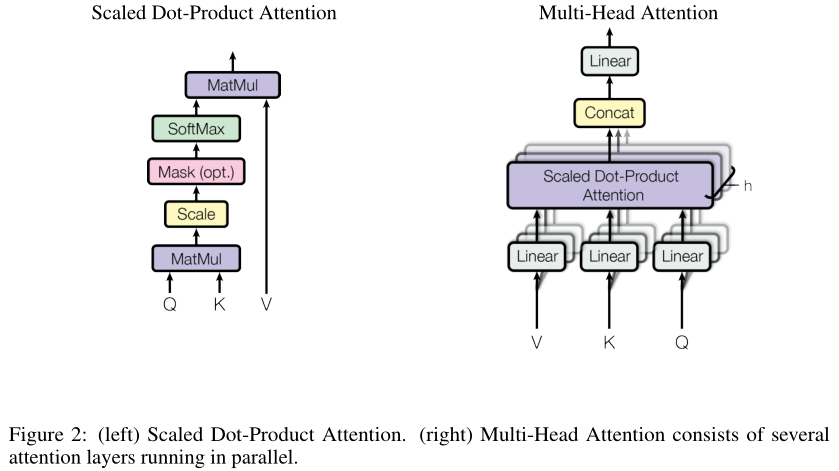
如图2所示为本文提出的attention机制。输入为d k d_{k}d k 维的Q和K,d v d_{v}d v 维的V。计算Q和K的点积,除以d k \sqrt{d_{k}}d k ,再使用一个softmax得到V的权重。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left( \frac{QK^{T}}{\sqrt{d_{k}}} \right)V Attention (Q ,K ,V )=softmax (d k Q K T )V
值得注意的是本文中的注意力函数有一个缩放因子1 d k \frac{1}{\sqrt{d_{k}}}d k 1 。文中提到,最常见的注意力函数有两种,一种是additive,一种就是上述的点积。Additive attention使用前馈网络来作为兼容性函数得到V的权重。当d k d_{k}d k 比较小时,两种注意力机制的表现差不多,随着d k d_{k}d k 的增大,additive注意力比点积注意力表现要好。由于点积可以使用高度优化的矩阵乘法代码来实现,因此更快,空间效率更高,这也是作者选择点积的原因。作者认为,当d k d_{k}d k 较大时,点积有数量级的增加,使得softmax函数梯度很小,为了抵消这种影响,作者对点积进行缩小。
而为什么向量维度的增加会导致点积数量级变大,假设向量q和k的分量都是均值为0,方差为1的独立随机变量,经过数学推导可有q i k i q_{i}k_{i}q i k i 的均值为0,方差为d k d_{k}d k 。 大维度导致点积的方差很大,在均值为0的前提下意味着点积的值更可能取大值,大的点积值导致梯度很小。因为在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。在输入值很大的时候,softmax导数几乎为0。
方差大表示各个分量的差距较大,然后softmax中的指数运算会进一步加大差距,导致最大值对应的概率很大,其他分量的概率很小。容易导致梯度消失,所以需要将其方差归一化到1。
具体的计算流程如下:
Step1.首先每个word都有query、key、value三个向量。这三个向量通过输入embedding与训练得到的三个矩阵W Q , W K , W V W^{Q},W^{K},W^{V}W Q ,W K ,W V相乘得到。
Step2.对于某个位置的单词w,计算query和key的相似度,一般使用内积。我们需要根据这个词对输入句子的每个词进行评分。当我们在某个位置对单词进行编码时,分数决定了将多少注意力放在输入句子的其他部分上。
Step3.将第二步得到的分数(即相似度)除以d k \sqrt{d_{k}}d k 。
Step4.将第三步的结果送入softmax函数。得到的结果值越大,表示该word与当前word关联性越强。
Step5.将第四步的结果与value向量相乘,得到加权的value向量。
Step6.将加权value相加,得到该位置上的word的注意力层的输出。
最终的结果送入前馈网络中。在实现时,为了高效方便,通常使用矩阵进行计算。
多头自注意力
多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息。
MultiHead ( Q , K , V ) & = Concat ( head 1 , … , head h ) W O head i = Attention ( Q W i Q , K W i K , V W i V ) \begin{matrix} \text{MultiHead}(Q,K,V)\& = \text{Concat}\left( \text{head}{1},\ldots,\text{head}{h} \right)W^{O} \ \text{head}{i}\ = \text{Attention}\left( QW{i}^{Q},KW_{i}^{K},VW_{i}^{V} \right) \ \end{matrix}MultiHead (Q ,K ,V )&=Concat (head 1 ,…,head h )W O head i =Attention (Q W i Q ,K W i K ,V W i V )
使用h个上述的注意力模型,这样就有h组Q、K、V。由于前馈网络层只能处理一个矩阵,所以将多个注意力函数的结果拼接起来与矩阵W O W^{O}W O相乘,得到多头自注意力层的输出,然后送入前馈网络中。本文中使用的h=6。如图二右侧所示。
多头自注意力机制,每一个head能表示某个单词一方面的语义信息,如下图所示。对于The animal didn’t cross the street, because it was too tired.这个句子来说,图中橙色线代表一个head,绿色线代表另一个head。橙色表明了it指代的最有可能是the animal;绿色表示了it是”tired”。也就是说,橙色代表了it的指代信息,而绿色代表了it的状态信息,不同的颜色表示了it的不同的语义信息。

; positional embedding
在Transformer中没有使用循环和卷积,所以需要一些位置信息来表达序列中的顺序。因此在encoder和decoder的底层将输入embedding加上positional embedding(维度与输入embedding相同)。positional embedding可以通过学习得到,也可以是固定的。本文中使用了不同频率的sin和cos函数:
P E ( p o s , 2 i ) & = sin ( p o s / 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) & = cos ( p o s / 1000 0 2 i / d model ) \begin{matrix} PE_{(pos,2i)}\& = \sin\left( pos/10000^{2i/d_{\text{model\ }}} \right) \ PE_{(pos,2i + 1)}\& = \cos\left( pos/10000^{2i/d_{\text{model\ }}} \right) \ \end{matrix}P E (p os ,2 i )&=sin (p os /1000 0 2 i /d model )P E (p os ,2 i +1 )&=cos (p os /1000 0 2 i /d model )
其中,pos就是位置word在句子中的位置,i是维度,也就是向量中的哪一维。positional encoding中的每一维对应一个正弦信号。通过上述这组公式得到positional embedding这个向量,从0 到 e m b e d d i n g d i m e n s i o n − 1 0到embedding \ dimension – 1 0 到e mb e dd in g d im e n s i o n −1,每两个位置用一次公式。从公式中可以看到,位置嵌入函数的周期会一直变化,使得位置编码具有周期性,并且有很好的表示相对位置的关系的特性(对于任意的偏移量k,PE[pos+k]可以由PE[pos]线性表示)。
Transformer的encoder部分
从图二中可以看到,Transformer模型的encoder部分由输入和n个解码器组成。
1)输入embedding与positional encoding
输入为输入的句子的embedding,每一个单词对应一个embedding向量。然后将其与上述的位置编码向量相加,得到送入第一 个encoder的输入:
X = I n p u t E m b e d d i n g + p o s i t i o n a l e m b e d d i n g X = Input\ Embedding + positional\ embedding X =I n p u t E mb e dd in g +p os i t i o na l e mb e dd in g
2)解码器-自注意力
每一个解码器由两个子层组成:一个self-attention层,一个FeedForward层。Self-attention层我们上面已经介绍过了,将输入映射为三个矩阵Q,K,V来得到注意力得分:
Q = Linea r ( X ) = X W Q K = Linea r ( X ) = X W K V = Linea r ( X ) = X W V X attention = Attention ( Q , K , V ) \begin{matrix} Q = \text{Linea}r\left( X \right) = XW_{Q} \ K = \text{Linea}r\left( X \right) = XW_{K} \ V = \text{Linea}r\left( X \right) = XW_{V} \ X_{\text{attention}} = \text{Attention}\left( Q,K,V \right) \ \end{matrix}Q =Linea r (X )=X W Q K =Linea r (X )=X W K V =Linea r (X )=X W V X attention =Attention (Q ,K ,V )
3)残差与层规范化
X attention = X + X attention X_{\text{attention}} = X + X_{\text{attention}}X attention =X +X attention
X attention = LayerNorm ( X attention ) X_{\text{attention}} = \text{LayerNorm}\left( X_{\text{attention}} \right)X attention =LayerNorm (X attention )
4)FeedForward
使用两层线性映射并用激活函数(ReLU)激活。
FFN ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = max\left( 0,xW_{1} + b_{1} \right)W_{2} + b_{2}FFN (x )=ma x (0 ,x W 1 +b 1 )W 2 +b 2
即:
FFN ( X attention ) = L i n e a r ( Activate ( Linear ( X attention ) ) ) \text{FFN}(X_{\text{attention}}) = Linear\left( \text{Activate}\left( \text{Linear}\left( X_{\text{attention}} \right) \right) \right)FFN (X attention )=L in e a r (Activate (Linear (X attention )))
5)重复3:
FFN ( X attention ) = FFN ( X attention ) + X attention \text{FFN}(X_{\text{attention}}) = \text{FFN}(X_{\text{attention}}) + X_{\text{attention}}FFN (X attention )=FFN (X attention )+X attention
FFN ( X attention ) = L a y e r N o r m ( FFN ( X attention ) ) \text{FFN}(X_{\text{attention}}) = LayerNorm\left( \text{FFN}(X_{\text{attention}}) \right)FFN (X attention )=L a yer N or m (FFN (X attention ))
根据残差连接,该层的输入为上一子层的输出加FeedForward的输出。
6)这就是一个Transformer encoder的计算流程。FFN ( X attention ) \text{FFN}(X_{\text{attention}})FFN (X attention )将作为下一个encoder的输入重复2-5执行,直到N个encoder。
需要注意的一个细节就是Mask问题,当有多句话的时候,每个句子长度不一定一样,以最长的se q len \text{se}q_{\text{len}}se q len 为准,不够长的句子一般用0来补充到最大长度,这个过程叫做padding。但这样进行softmax时,就会产生问题。因为softmax函数在对元素为0时,e 0 = 1 e^{0} = 1 e 0 =1,依然是有值的。但是这个值并无实际意义,这会浪费资源,增加运算量。作者使用masking,即将padding部分置为− ∞ – \infty −∞,这样使得e − ∞ = 1 e^{- \infty} = 1 e −∞=1,经过上式的masking使无效区域经过softmax计算之后还几乎为0,就避免了无效区域参与计算。在Transformer中有两种masking,一种是上述的padding masking,另外一种为sequence masking,在decoder中介绍。
Transformer的decoder部分
decoder部分与encoder基本上类似。不同之处在于在decoder中增加了一个masked Muti-Head attention子层,也就是每一个decoder有三个子层。
输入
Decoder中的输入分为两类,一种是训练时的输入,一种是预测时的输入。在训练的时候,为了parallel的训练,decoder的输入是整句句子。训练时的输入就是已经对准备好对应的target数据。例如翻译任务,Encoder输入”Tom chase Jerry”,Decoder输入”汤姆追逐杰瑞”。
预测时的输入,在每时每刻有两个输入:a)来自encoder stack的输出K、V,在每个时刻都会输入到每个decoder中的muti-head attention层;b)上一时刻decoder输出结果。0时刻为起始符的embedding。
masked multi-head self-attention
这一层生成decoder输入的每一个word对应的representation作为query,这个query在”multi-head attention”中与encoder输出的Keys和Values做运算,就能知道哪些源语言的hidden state对当前词比较重要,然后输出原来sentence一个新的representation。
在上文提到,transformer中有两个mask,一个是padding mask,另一个是sequence mask。这里的mask就是指padding mask+sequence mask。在训练的时候为了并行输入,decoder会输入整个句子。这里需要对当前词之后的词进行mask,使得decoder不能看见未来的信息。如果不进行mask,那么预测输出的时候是根据整个句子的信息进行预测的,也就是看到了后面的词语信息,这显然是有问题的。
Muti-Head Attention
Decoder在这一子层接收来自encoder的K,V和上一子层的Q。
最后的输出Linear&Softmax
输入的句子首先经过embedding,然后加上positional encoding,在经过encoder-decoder,最终会到达一个全连接层,将decoder stack输出的结果映射为一个logits向量。这个向量非常大非常大,假如输出的单词库有n个单词,则那logits向量就有n个单元格。每一格对应一个单词的分数。最后使用softmax函数将其转化为概率,值最大的那一个即为该时间步的输出。
实验
在WMT 2014英德翻译任务中,transformer (big) (表2中的transformer(big))比之前报道的最佳模型高出2.0个BLEU以上,获得了28.4的最新BLEU分数。基础模型也超过了所有以前发布的模型,只花费了其他模型的一小部分训练成本。
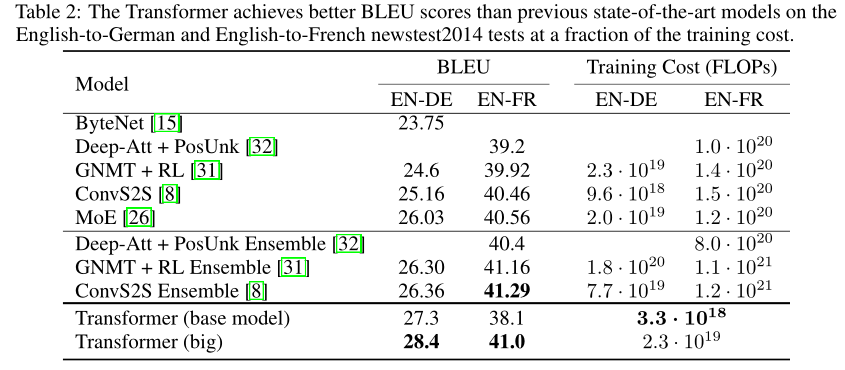
在WMT 2014英法翻译任务中,transformer big模型获得了41.0的BLEU分数,超过了之前发布的所有模型,而训练成本不到之前最先进模型的四分之一。
Original: https://blog.csdn.net/BodyCsoulN/article/details/121496877
Author: BodyCsoulN
Title: 【论文笔记】Attention is all you need
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531706/
转载文章受原作者版权保护。转载请注明原作者出处!