

自回归语言模型(Autoregressive LM)
在ELMO/BERT出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。
自编码语言模型(Autoencoder LM)
自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
这种DAE LM的优缺点正好和自回归LM反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点是啥呢?主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。DAE吗,就要引入噪音,[Mask]
标记就是引入噪音的手段,这个正常。
ELMo的出现开创了一种上下文相关的文本表示方法,很好地处理了一词多义问题,并在多个典型任务上有了显著的效果提升。
其后,GPT和BERT等预训练语言模型相继被提出,自此便进入了动态预训练技术的时代。尤其是BERT的出现,横扫了自然语言处理领域的多个典型任务,极大地推动了自然语言处理领域的发展,成为预训练史上一个重要的里程碑模型。此后,基于BERT的改进模型、XLNet等大量新式预训练语言模型涌出,预训练技术在自然语言处理领域蓬勃发展。
在预训练模型的基础上,针对下游任务进行微调,已成为自然语言处理领域的一个新范式。
预训练语言模型
预训练语言模型的核心在于关键范式的转变:从只初始化模型的第一层,转向了预训练一个多层网络结构。
传统的词向量方法只使用预训练好的静态文本表示,初始化下游任务模型的第一层,而下游任务模型的其余网络结构仍然需要从头开始训练。这是一种以效率优先而牺牲表达力的浅层方法,无法捕捉到那些也许更有用的深层信息;更重要的是,其本质上是一种静态的方式,无法消除词语歧义。
预训练语言模型是预训练一个多层网络结构,用以初始化下游任务模型的多层网络结构,可以同时学到浅层信息和深层信息。预训练语言模型是一种动态的文本表示方法,会根据当前上下文对文本表征进行动态调整,经过调整后的文本表征更能表达词语在该上下文中的具体含义,能有效处理一词多义的问题。
ELMo
ELMo使用两层带残差的双向LSTM来训练语言模型,此外,ELMo借鉴了Jozefowicz等的做法,针对英文形态学上的特点,在预训练模型的输入层和输出层使用了字符级的CNN结构。这种结构大幅减小了词表的规模,很好地解决了未登录词的问题;卷积操作也可以捕获一些英文中的形态学信息;同时,训练双向的LSTM,不仅考虑了上文信息,也融合了下文信息。
ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM,这个跟模型具体怎么实现有关系。ELMO是做了两个方向(从左到右以及从右到左两个方向的语言模型),但是是分别有两个方向的自回归LM,然后把LSTM的两个方向的隐节点状态拼接到一起,来体现双向语言模型这个事情的。所以其实是两个自回归语言模型的拼接,本质上仍然是自回归语言模型。
自回归语言模型有优点有缺点,缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息,当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。它的优点,其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。
而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
GPT模型
单向语言模型
GPT模型使用生成式方法来训练语言模型。该工作中的解码器在逐字生成翻译的过程中屏蔽了后 续的词语序列,天然适合语言建模,因此GPT采用了Transformer中的解码器结构,并没有使用一个完整的Transformer来构建网络。GPT模型堆叠了12个Transformer子层,并用语言建模的目标函数来进行优化和训练。
BERT模型
基于Transformer的双向预训练语言模型,通过Masked-LM这个特别的预训练方式达到了真双向语言模型的效果。能够同时利用上文和下文,所以信息利用充分。
XLNet
二、预训练模型使用方法
微调fine tune
- 1 特征提取
我们可以将预训练模型当做特征提取装置来使用。具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。
- 2 采用预训练模型的结构
我们还可以采用预训练模型的结构,但先将所有的权重随机化,然后依据自己的数据集进行训练。
- 3 训练特定层,冻结其他层
另一种使用预训练模型的方法是对它进行部分的训练。具体的做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
数据集大小和相似度不同时 使用预训练模型的方法
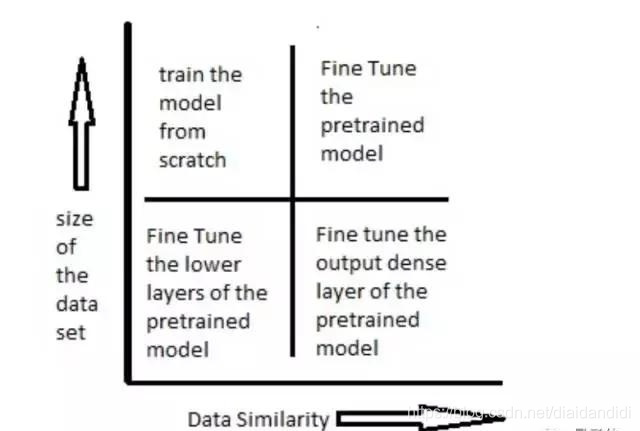

- 场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我们只需要将输出层改制成符合问题情境下的结构就好。
我们使用预处理模型作为模式提取器。
比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。
在这个例子中,我们需要做的就是把dense layer和最终softmax layer的输出从1000个类别改为2个类别。
- 场景二:数据集小,数据相似度不高
在这种情况下,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。
因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。
- 场景三:数据集大,数据相似度不高
在这种情况下,因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。
因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
- 场景四:数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效。最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
参考文献
[1]李舟军,范宇,吴贤杰.面向自然语言处理的预训练技术研究综述[J].计算机科学,2020,47(03):162-173.
2.XLNet:运行机制及和Bert的异同比较https://zhuanlan.zhihu.com/p/70257427
Original: https://blog.csdn.net/weixin_43251493/article/details/119219825
Author: 白十月
Title: 预训练模型简介和使用方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531692/
转载文章受原作者版权保护。转载请注明原作者出处!