

Paddle复现RetinaFace详细解析
RetinaFace前向推理
分析主要分以下部分:
1,网络主干结构
2,网络的后处理
3, 网络前向推理
1,网络的主干结构复现
网络结构图如下:
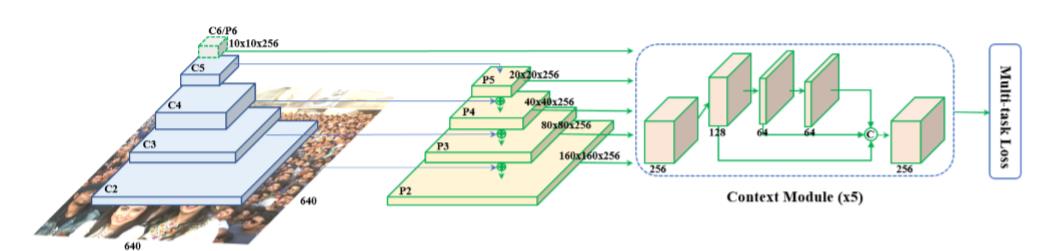

这里复现部分做了精简,5层FPN删减为3层,主干为mobilinet
In [10]
专干网络所用的模块
View dataset directory.
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
def conv_bn(inp, oup, stride = 1, leaky = 0):
return nn.Sequential(
nn.Conv2D(inp, oup, 3, stride, 1, bias_attr=False),
nn.BatchNorm2D(oup),
nn.LeakyReLU(negative_slope=leaky)
)
def conv_bn_no_relu(inp, oup, stride):
return nn.Sequential(
nn.Conv2D(inp, oup, 3, stride, 1, bias_attr=False),
nn.BatchNorm2D(oup),
)
def conv_bn1X1(inp, oup, stride, leaky=0):
return nn.Sequential(
nn.Conv2D(inp, oup, 1, stride, padding=0, bias_attr=False),
nn.BatchNorm2D(oup),
nn.LeakyReLU(negative_slope=leaky)
)
def conv_dw(inp, oup, stride, leaky=0.1):
return nn.Sequential(
nn.Conv2D(inp, inp, 3, stride, 1, groups=inp, bias_attr=False),
nn.BatchNorm2D(inp),
nn.LeakyReLU(negative_slope=leaky),
nn.Conv2D(inp, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
nn.LeakyReLU(negative_slope=leaky),
)
class SSH(nn.Layer):
def __init__(self, in_channel, out_channel):
super(SSH, self).__init__()
assert out_channel % 4 == 0
leaky = 0
if (out_channel
以上完成的是fpn,ssh等结构代码,修改后的MobileNetV1,前向传播完成以上部分,将得到三个输出,每个输出将再分别连接三个卷积得到分类,定位,关键点内容,实现如下:
In [11]
网络主干部分,前向推理
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class ClassHead(nn.Layer):
def __init__(self,inchannels=512,num_anchors=3):
super(ClassHead,self).__init__()
self.num_anchors = num_anchors
self.conv1x1 = nn.Conv2D(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.transpose([0,2,3,1])
return out.reshape([out.shape[0], -1, 2])
class BboxHead(nn.Layer):
def __init__(self,inchannels=512,num_anchors=3):
super(BboxHead,self).__init__()
self.conv1x1 = nn.Conv2D(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.transpose([0,2,3,1])
return out.reshape([out.shape[0], -1, 4])
class LandmarkHead(nn.Layer):
def __init__(self,inchannels=512,num_anchors=3):
super(LandmarkHead,self).__init__()
self.conv1x1 = nn.Conv2D(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.transpose([0,2,3,1])
return out.reshape([out.shape[0], -1, 10])
class RetinaFace(nn.Layer):
def __init__(self, cfg = None, phase = 'train'):
"""
:param cfg: Network related settings.
:param phase: train or test.
"""
super(RetinaFace,self).__init__()
self.phase = phase
backbone = None
if cfg['name'] == 'mobilenet0.25':
backbone = MobileNetV1()
if cfg['pretrain']:
checkpoint = paddle.load("./weights/mobilenetV1X0.25_pretrain.pdparams")
backbone.set_state_dict(checkpoint)
elif cfg['name'] == 'Resnet50':
import paddle.vision.models as models
backbone = models.resnet50(pretrained=cfg['pretrain'])
self.body = backbone
in_channels_stage2 = cfg['in_channel']
in_channels_list = [
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
]
out_channels = cfg['out_channel']
self.fpn = FPN(in_channels_list,out_channels)
self.ssh1 = SSH(out_channels, out_channels)
self.ssh2 = SSH(out_channels, out_channels)
self.ssh3 = SSH(out_channels, out_channels)
self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
def _make_class_head(self,fpn_num=3,inchannels=64,anchor_num=2):
classhead = nn.LayerList()
for i in range(fpn_num):
classhead.append(ClassHead(inchannels,anchor_num))
return classhead
def _make_bbox_head(self,fpn_num=3,inchannels=64,anchor_num=2):
bboxhead = nn.LayerList()
for i in range(fpn_num):
bboxhead.append(BboxHead(inchannels,anchor_num))
return bboxhead
def _make_landmark_head(self,fpn_num=3,inchannels=64,anchor_num=2):
landmarkhead = nn.LayerList()
for i in range(fpn_num):
landmarkhead.append(LandmarkHead(inchannels,anchor_num))
return landmarkhead
def forward(self,inputs):
out = self.body(inputs)
# FPN
fpn = self.fpn(out)
# SSH
feature1 = self.ssh1(fpn[0])
feature2 = self.ssh2(fpn[1])
feature3 = self.ssh3(fpn[2])
features = [feature1, feature2, feature3]
bbox_regressions = paddle.concat([self.BboxHead[i](feature) for i, feature in enumerate(features)], axis=1)
classifications = paddle.concat([self.ClassHead[i](feature) for i, feature in enumerate(features)],axis=1)
ldm_regressions = paddle.concat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], axis=1)
if self.phase == 'train':
output = (bbox_regressions, classifications, ldm_regressions)
else:
output = (bbox_regressions, F.softmax(classifications, axis=-1), ldm_regressions)
return output
cfg_mnet = {
'name': 'mobilenet0.25',
'min_sizes': [[16, 32], [64, 128], [256, 512]],
'steps': [8, 16, 32],
'variance': [0.1, 0.2],
'clip': False,
'loc_weight': 2.0,
'gpu_train': True,
'batch_size': 32,
'ngpu': 1,
'epoch': 250,
'decay1': 190,
'decay2': 220,
'image_size': 640,
'pretrain': True,
'return_layers': {'stage1': 1, 'stage2': 2, 'stage3': 3},
'in_channel': 32,
'out_channel': 64
}
##net = RetinaFace(cfg=cfg_mnet, phase = 'test')
#net.eval()
2,预选框生成与网络结果后处理
先生成anchors, 使用推理结果和anchors进行解码
In [12]
预选框生成, 如下方代码示例:
import paddle
from itertools import product as product
from math import ceil
class PriorBox(object):
def __init__(self, cfg, image_size=None, phase='train'):
super(PriorBox, self).__init__()
self.min_sizes = cfg['min_sizes']
self.steps = cfg['steps']
self.clip = cfg['clip']
self.image_size = image_size
self.feature_maps = [[ceil(self.image_size[0]/step), ceil(self.image_size[1]/step)] for step in self.steps]
self.name = "s"
def forward(self):
anchors = []
for k, f in enumerate(self.feature_maps):
min_sizes = self.min_sizes[k]
for i, j in product(range(f[0]), range(f[1])):
for min_size in min_sizes:
s_kx = min_size / self.image_size[1]
s_ky = min_size / self.image_size[0]
dense_cx = [x * self.steps[k] / self.image_size[1] for x in [j + 0.5]]
dense_cy = [y * self.steps[k] / self.image_size[0] for y in [i + 0.5]]
for cy, cx in product(dense_cy, dense_cx):
anchors += [cx, cy, s_kx, s_ky]
# back to torch land
output = paddle.to_tensor(anchors).reshape([-1, 4])
if self.clip:
output = output.clip(max=1, min=0)
return output
In [13]
同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import paddle
import numpy as np
def index_fill(input, index, update):
'''
achieve Tensor.index_fill method
only for this repo, it's not common use
'''
for i in range(len(index)):
input[index[i]] = update
return input
def point_form(boxes):
""" Convert prior_boxes to (xmin, ymin, xmax, ymax)
representation for comparison to point form ground truth data.
Args:
boxes: (tensor) center-size default boxes from priorbox layers.
Return:
boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
"""
return paddle.concat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
boxes[:, :2] + boxes[:, 2:]/2), 1) # xmax, ymax
def center_size(boxes):
""" Convert prior_boxes to (cx, cy, w, h)
representation for comparison to center-size form ground truth data.
Args:
boxes: (tensor) point_form boxes
Return:
boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
"""
return paddle.concat((boxes[:, 2:] + boxes[:, :2])/2, # cx, cy
boxes[:, 2:] - boxes[:, :2], 1) # w, h
def intersect(box_a, box_b):
""" We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b.
Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
"""
A = box_a.shape[0]
B = box_b.shape[0]
max_xy = paddle.minimum(box_a[:, 2:].unsqueeze(1).expand([A, B, 2]),
box_b[:, 2:].unsqueeze(0).expand([A, B, 2]))
min_xy = paddle.maximum(box_a[:, :2].unsqueeze(1).expand([A, B, 2]),
box_b[:, :2].unsqueeze(0).expand([A, B, 2]))
inter = paddle.clip(max_xy - min_xy, min=0)
return inter[:, :, 0] * inter[:, :, 1]
def jaccard(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes. The jaccard overlap
is simply the intersection over union of two boxes. Here we operate on
ground truth boxes and default boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
Return:
jaccard overlap: (tensor) Shape: [box_a.shape[0], box_b.shape[0]]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
def matrix_iou(a, b):
"""
return iou of a and b, numpy version for data augenmentation
"""
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
area_b = np.prod(b[:, 2:] - b[:, :2], axis=1)
return area_i / (area_a[:, np.newaxis] + area_b - area_i)
def matrix_iof(a, b):
"""
return iof of a and b, numpy version for data augenmentation
"""
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
return area_i / np.maximum(area_a[:, np.newaxis], 1)
def match(threshold, truths, priors, variances, labels, landms, loc_t, conf_t, landm_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, 4].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
landms: (tensor) Ground truth landms, Shape [num_obj, 10].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
landm_t: (tensor) Tensor to be filled w/ endcoded landm targets.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location 2)confidence 3)landm preds.
"""
# jaccard index
overlaps = jaccard(
truths,
point_form(priors)
)
# (Bipartite Matching)
# [1,num_objects] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True), overlaps.argmax(1, keepdim=True)
# ignore hard gt
valid_gt_idx = best_prior_overlap[:, 0] >= 0.2
best_prior_idx_filter = best_prior_idx.masked_select(valid_gt_idx.unsqueeze(1)).unsqueeze(1)
if best_prior_idx_filter.shape[0] = 0.01]
idx = idx[-top_k:] # indices of the top-k largest vals
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
# keep = paddle.Tensor()
count = 0
while idx.numel() > 0:
i = idx[-1] # index of current largest val
# keep.append(i)
keep[count] = i
count += 1
if idx.shape[0] == 1:
break
idx = idx[:-1] # remove kept element from view
# load bboxes of next highest vals
paddle.index_select(x1, 0, idx, out=xx1)
paddle.index_select(y1, 0, idx, out=yy1)
paddle.index_select(x2, 0, idx, out=xx2)
paddle.index_select(y2, 0, idx, out=yy2)
# store element-wise max with next highest score
xx1 = paddle.clip(xx1, min=x1[i])
yy1 = paddle.clip(yy1, min=y1[i])
xx2 = paddle.clip(xx2, max=x2[i])
yy2 = paddle.clip(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = paddle.clip(w, min=0.0)
h = paddle.clip(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
rem_areas = paddle.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]
IoU = inter/union # store result in iou
# keep only elements with an IoU
3,网络前向推理
In [14]
from __future__ import print_function
import argparse
import paddle
import numpy as np
import cv2
import time
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr 0, 'load NONE from pretrained checkpoint'
return True
def remove_prefix(state_dict, prefix):
''' Old style model is stored with all names of parameters sharing common prefix 'module.' '''
print('remove prefix \'{}\''.format(prefix))
f = lambda x: x.split(prefix, 1)[-1] if x.startswith(prefix) else x
return {f(key): value for key, value in state_dict.items()}
def load_model(model, pretrained_path):
print('Loading pretrained model from {}'.format(pretrained_path))
pretrained_dict = paddle.load(pretrained_path)
if "state_dict" in pretrained_dict.keys():
pretrained_dict = remove_prefix(pretrained_dict['state_dict'], 'module.')
else:
pretrained_dict = remove_prefix(pretrained_dict, 'module.')
check_keys(model, pretrained_dict)
model.set_state_dict(pretrained_dict)
return model
paddle.set_grad_enabled(False)
cfg = cfg_mnet
#args.network == "mobile0.25"
net and model
net = RetinaFace(cfg=cfg_mnet, phase = 'test')
net = load_model(net, 'test/mobilenet0.25_epoch_5.pdparams')
net.eval()
print('Finished loading model!')
print(net)
resize = 1
testing begin
image_path = "test.jpg"
img_raw = cv2.imread(image_path, cv2.IMREAD_COLOR)
img = np.float32(img_raw)
im_height, im_width, _ = img.shape
scale = paddle.to_tensor([img.shape[1], img.shape[0], img.shape[1], img.shape[0]])
img -= (104, 117, 123)
img /= (57.1,57.4,58.4)
img = img.transpose(2, 0, 1)
img = paddle.to_tensor(img).unsqueeze(0)
tic = time.time()
loc, conf, landms = net(img) # forward pass
print('net forward time: {:.4f}'.format(time.time() - tic))
priorbox = PriorBox(cfg, image_size=(im_height, im_width))
priors = priorbox.forward()
prior_data = priors
boxes = decode(loc.squeeze(0), prior_data, cfg['variance'])
boxes = boxes * scale / resize
boxes = boxes.cpu().numpy()
scores = conf.squeeze(0).cpu().numpy()[:, 1]
landms = decode_landm(landms.squeeze(0), prior_data, cfg['variance'])
scale1 = paddle.to_tensor([img.shape[3], img.shape[2], img.shape[3], img.shape[2],
img.shape[3], img.shape[2], img.shape[3], img.shape[2],
img.shape[3], img.shape[2]])
landms = landms * scale1 / resize
landms = landms.cpu().numpy()
ignore low scores
inds = np.where(scores > args.confidence_threshold)[0]
boxes = boxes[inds]
landms = landms[inds]
scores = scores[inds]
keep top-K before NMS
order = scores.argsort()[::-1][:args.top_k]
boxes = boxes[order]
landms = landms[order]
scores = scores[order]
do NMS
dets = np.hstack((boxes, scores[:, np.newaxis])).astype(np.float32, copy=False)
keep = py_cpu_nms(dets, args.nms_threshold)
keep = nms(dets, args.nms_threshold,force_cpu=args.cpu)
dets = dets[keep, :]
landms = landms[keep]
keep top-K faster NMS
dets = dets[:args.keep_top_k, :]
landms = landms[:args.keep_top_k, :]
dets = np.concatenate((dets, landms), axis=1)
show image
if args.save_image:
for b in dets:
if b[4] < args.vis_thres:
continue
text = "{:.4f}".format(b[4])
b = list(map(int, b))
cv2.rectangle(img_raw, (b[0], b[1]), (b[2], b[3]), (0, 0, 255), 2)
cx = b[0]
cy = b[1] + 12
cv2.putText(img_raw, text, (cx, cy),
cv2.FONT_HERSHEY_DUPLEX, 0.5, (255, 255, 255))
# landms
cv2.circle(img_raw, (b[5], b[6]), 1, (0, 0, 255), 4)
cv2.circle(img_raw, (b[7], b[8]), 1, (0, 255, 255), 4)
cv2.circle(img_raw, (b[9], b[10]), 1, (255, 0, 255), 4)
cv2.circle(img_raw, (b[11], b[12]), 1, (0, 255, 0), 4)
cv2.circle(img_raw, (b[13], b[14]), 1, (255, 0, 0), 4)
# save image
name = "test_out.jpg"
cv2.imwrite(name, img_raw)
Loading pretrained model from test/mobilenet0.25_epoch_5.pdparams
remove prefix 'module.'
Missing keys:0
Unused checkpoint keys:0
Used keys:255
Finished loading model!
net forward time: 0.0325
RetinaFace反向传播
主要包括:
4,网络损失函数
5,训练数据组织
6,训练设置,迭代
4,网络损失函数
正向传播需要对网络的输出结果进行解码,训练需要根据预选框和真实结果进行编码
In [15]
#网络损失函数
def index_fill(input, index, update):
'''
achieve Tensor.index_fill method
only for this repo, it's not common use
'''
for i in range(len(index)):
input[index[i]] = update
return input
def point_form(boxes):
""" Convert prior_boxes to (xmin, ymin, xmax, ymax)
representation for comparison to point form ground truth data.
Args:
boxes: (tensor) center-size default boxes from priorbox layers.
Return:
boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
"""
return paddle.concat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
boxes[:, :2] + boxes[:, 2:]/2), 1) # xmax, ymax
def center_size(boxes):
""" Convert prior_boxes to (cx, cy, w, h)
representation for comparison to center-size form ground truth data.
Args:
boxes: (tensor) point_form boxes
Return:
boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
"""
return paddle.concat((boxes[:, 2:] + boxes[:, :2])/2, # cx, cy
boxes[:, 2:] - boxes[:, :2], 1) # w, h
def intersect(box_a, box_b):
""" We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b.
Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
"""
A = box_a.shape[0]
B = box_b.shape[0]
max_xy = paddle.minimum(box_a[:, 2:].unsqueeze(1).expand([A, B, 2]),
box_b[:, 2:].unsqueeze(0).expand([A, B, 2]))
min_xy = paddle.maximum(box_a[:, :2].unsqueeze(1).expand([A, B, 2]),
box_b[:, :2].unsqueeze(0).expand([A, B, 2]))
inter = paddle.clip(max_xy - min_xy, min=0)
return inter[:, :, 0] * inter[:, :, 1]
def jaccard(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes. The jaccard overlap
is simply the intersection over union of two boxes. Here we operate on
ground truth boxes and default boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
Return:
jaccard overlap: (tensor) Shape: [box_a.shape[0], box_b.shape[0]]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
def matrix_iou(a, b):
"""
return iou of a and b, numpy version for data augenmentation
"""
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
area_b = np.prod(b[:, 2:] - b[:, :2], axis=1)
return area_i / (area_a[:, np.newaxis] + area_b - area_i)
def matrix_iof(a, b):
"""
return iof of a and b, numpy version for data augenmentation
"""
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
return area_i / np.maximum(area_a[:, np.newaxis], 1)
def match(threshold, truths, priors, variances, labels, landms, loc_t, conf_t, landm_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, 4].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
landms: (tensor) Ground truth landms, Shape [num_obj, 10].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
landm_t: (tensor) Tensor to be filled w/ endcoded landm targets.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location 2)confidence 3)landm preds.
"""
# jaccard index
overlaps = jaccard(
truths,
point_form(priors)
)
# (Bipartite Matching)
# [1,num_objects] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True), overlaps.argmax(1, keepdim=True)
# ignore hard gt
valid_gt_idx = best_prior_overlap[:, 0] >= 0.2
best_prior_idx_filter = best_prior_idx.masked_select(valid_gt_idx.unsqueeze(1)).unsqueeze(1)
if best_prior_idx_filter.shape[0]
对人脸框和人脸关键点进行编码之后,可以计算损失:
In [16]
GPU = cfg['gpu_train']
class MultiBoxLoss(nn.Layer):
"""SSD Weighted Loss Function
Compute Targets:
1) Produce Confidence Target Indices by matching ground truth boxes
with (default) 'priorboxes' that have jaccard index > threshold parameter
(default threshold: 0.5).
2) Produce localization target by 'encoding' variance into offsets of ground
truth boxes and their matched 'priorboxes'.
3) Hard negative mining to filter the excessive number of negative examples
that comes with using a large number of default bounding boxes.
(default negative:positive ratio 3:1)
Objective Loss:
L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
weighted by α which is set to 1 by cross val.
Args:
c: class confidences,
l: predicted boxes,
g: ground truth boxes
N: number of matched default boxes
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
"""
def __init__(self, num_classes, overlap_thresh, prior_for_matching, bkg_label, neg_mining, neg_pos, neg_overlap, encode_target):
super(MultiBoxLoss, self).__init__()
self.num_classes = num_classes
self.threshold = overlap_thresh
self.background_label = bkg_label
self.encode_target = encode_target
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.variance = [0.1, 0.2]
def forward(self, predictions, priors, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: paddle.shape(batch_size,num_priors,num_classes)
loc shape: paddle.shape(batch_size,num_priors,4)
priors shape: paddle.shape(num_priors,4)
ground_truth (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, landm_data = predictions
priors = priors
num = loc_data.shape[0]
num_priors = (priors.shape[0])
# match priors (default boxes) and ground truth boxes
loc_t = paddle.randn([num, num_priors, 4])
landm_t = paddle.randn([num, num_priors, 10])
conf_t = paddle.zeros([num, num_priors], dtype='int32')
for idx in range(num):
truths = targets[idx][:, :4]
labels = targets[idx][:, -1]
landms = targets[idx][:, 4:14]
defaults = priors
match(self.threshold, truths, defaults, self.variance, labels, landms, loc_t, conf_t, landm_t, idx)
# landm Loss (Smooth L1)
# Shape: [batch,num_priors,10]
pos1 = conf_t > 0
num_pos_landm = pos1.astype('int64').sum(1, keepdim=True)
N1 = max(num_pos_landm.sum().astype('float32'), 1)
pos_idx1 = pos1.unsqueeze(pos1.dim()).expand_as(landm_data)
landm_p = landm_data.masked_select(pos_idx1).reshape([-1, 10])
landm_t = landm_t.masked_select(pos_idx1).reshape([-1, 10])
loss_landm = F.smooth_l1_loss(landm_p, landm_t, reduction='sum')
pos = conf_t != 0
conf_t_temp = conf_t.numpy()
conf_t_temp[pos.numpy()] = 1
conf_t = paddle.to_tensor(conf_t_temp)
# conf_t[pos] = 1
# conf_t = conf_t.add(pos.astype('int64'))
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data.masked_select(pos_idx).reshape([-1, 4])
loc_t = loc_t.masked_select(pos_idx).reshape([-1, 4])
loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.reshape([-1, self.num_classes])
loss_c = log_sum_exp(batch_conf) - batch_conf.multiply(paddle.nn.functional.one_hot(conf_t.reshape([-1, 1]), 2).squeeze(1)).sum(1).unsqueeze(1)
# Hard Negative Mining
# loss_c[pos.reshape([-1, 1])] = 0 # filter out pos boxes for now
loss_c = loss_c * (pos.reshape([-1, 1])==0).astype('float32')
loss_c = loss_c.reshape([num, -1])
loss_idx = loss_c.argsort(1, descending=True)
idx_rank = loss_idx.argsort(1)
num_pos = pos.astype('int64').sum(1, keepdim=True)
num_neg = paddle.clip(self.negpos_ratio*num_pos, max=pos.shape[1]-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data.masked_select((pos_idx.logical_or(neg_idx)).astype('float32') > 0).reshape([-1,self.num_classes])
targets_weighted = conf_t.masked_select((pos.logical_or(neg)).astype('float32') > 0)
loss_c = F.cross_entropy(conf_p, targets_weighted.astype('int64'), reduction='sum')
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = max(num_pos.sum().astype('float32'), 1)
loss_l /= N
loss_c /= N
loss_landm /= N1
return loss_l, loss_c, loss_landm
请点击此处查看本环境基本用法.
Please click herefor more detailed instructions.
5,训练数据组织
构建加载训练数据函数,数据增强,构建数据生成器
In [17]
#构建加载训练数据函数
from paddle.io import Dataset
from paddle.io import BatchSampler, DistributedBatchSampler, RandomSampler, SequenceSampler, DataLoader
class WiderFaceDetection(Dataset):
def __init__(self, txt_path, preproc=None):
self.preproc = preproc
self.imgs_path = []
self.words = []
f = open(txt_path,'r')
lines = f.readlines()
isFirst = True
labels = []
for line in lines:
line = line.rstrip()
if line.startswith('#'):
if isFirst is True:
isFirst = False
else:
labels_copy = labels.copy()
self.words.append(labels_copy)
labels.clear()
path = line[2:]
path = txt_path.replace('label.txt','images/') + path
self.imgs_path.append(path)
else:
line = line.split(' ')
label = [float(x) for x in line]
labels.append(label)
self.words.append(labels)
def __len__(self):
return len(self.imgs_path)
def __getitem__(self, index):
img = cv2.imread(self.imgs_path[index])
height, width, _ = img.shape
labels = self.words[index]
annotations = np.zeros((0, 15))
if len(labels) == 0:
return annotations
for idx, label in enumerate(labels):
annotation = np.zeros((1, 15))
# bbox
annotation[0, 0] = label[0] # x1
annotation[0, 1] = label[1] # y1
annotation[0, 2] = label[0] + label[2] # x2
annotation[0, 3] = label[1] + label[3] # y2
# landmarks
annotation[0, 4] = label[4] # l0_x
annotation[0, 5] = label[5] # l0_y
annotation[0, 6] = label[7] # l1_x
annotation[0, 7] = label[8] # l1_y
annotation[0, 8] = label[10] # l2_x
annotation[0, 9] = label[11] # l2_y
annotation[0, 10] = label[13] # l3_x
annotation[0, 11] = label[14] # l3_y
annotation[0, 12] = label[16] # l4_x
annotation[0, 13] = label[17] # l4_y
if (annotation[0, 4] self.num_iterations:
break
yield batch
def __len__(self):
return self.num_iterations
#数据增强
def _crop(image, boxes, labels, landm, img_dim):
height, width, _ = image.shape
pad_image_flag = True
for _ in range(250):
"""
if random.uniform(0, 1) = 1)
if not flag.any():
continue
centers = (boxes[:, :2] + boxes[:, 2:]) / 2
mask_a = np.logical_and(roi[:2] < centers, centers < roi[2:]).all(axis=1)
boxes_t = boxes[mask_a].copy()
labels_t = labels[mask_a].copy()
landms_t = landm[mask_a].copy()
landms_t = landms_t.reshape([-1, 5, 2])
if boxes_t.shape[0] == 0:
continue
image_t = image[roi[1]:roi[3], roi[0]:roi[2]]
boxes_t[:, :2] = np.maximum(boxes_t[:, :2], roi[:2])
boxes_t[:, :2] -= roi[:2]
boxes_t[:, 2:] = np.minimum(boxes_t[:, 2:], roi[2:])
boxes_t[:, 2:] -= roi[:2]
# landm
landms_t[:, :, :2] = landms_t[:, :, :2] - roi[:2]
landms_t[:, :, :2] = np.maximum(landms_t[:, :, :2], np.array([0, 0]))
landms_t[:, :, :2] = np.minimum(landms_t[:, :, :2], roi[2:] - roi[:2])
landms_t = landms_t.reshape([-1, 10])
# make sure that the cropped image contains at least one face > 16 pixel at training image scale
b_w_t = (boxes_t[:, 2] - boxes_t[:, 0] + 1) / w * img_dim
b_h_t = (boxes_t[:, 3] - boxes_t[:, 1] + 1) / h * img_dim
mask_b = np.minimum(b_w_t, b_h_t) > 0.0
boxes_t = boxes_t[mask_b]
labels_t = labels_t[mask_b]
landms_t = landms_t[mask_b]
if boxes_t.shape[0] == 0:
continue
pad_image_flag = False
return image_t, boxes_t, labels_t, landms_t, pad_image_flag
return image, boxes, labels, landm, pad_image_flag
def _distort(image):
def _convert(image, alpha=1, beta=0):
tmp = image.astype(float) * alpha + beta
tmp[tmp < 0] = 0
tmp[tmp > 255] = 255
image[:] = tmp
image = image.copy()
if random.randrange(2):
#brightness distortion
if random.randrange(2):
_convert(image, beta=random.uniform(-32, 32))
#contrast distortion
if random.randrange(2):
_convert(image, alpha=random.uniform(0.5, 1.5))
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
#saturation distortion
if random.randrange(2):
_convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
#hue distortion
if random.randrange(2):
tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
tmp %= 180
image[:, :, 0] = tmp
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
else:
#brightness distortion
if random.randrange(2):
_convert(image, beta=random.uniform(-32, 32))
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
#saturation distortion
if random.randrange(2):
_convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
#hue distortion
if random.randrange(2):
tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
tmp %= 180
image[:, :, 0] = tmp
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
#contrast distortion
if random.randrange(2):
_convert(image, alpha=random.uniform(0.5, 1.5))
return image
def _expand(image, boxes, fill, p):
if random.randrange(2):
return image, boxes
height, width, depth = image.shape
scale = random.uniform(1, p)
w = int(scale * width)
h = int(scale * height)
left = random.randint(0, w - width)
top = random.randint(0, h - height)
boxes_t = boxes.copy()
boxes_t[:, :2] += (left, top)
boxes_t[:, 2:] += (left, top)
expand_image = np.empty(
(h, w, depth),
dtype=image.dtype)
expand_image[:, :] = fill
expand_image[top:top + height, left:left + width] = image
image = expand_image
return image, boxes_t
def _mirror(image, boxes, landms):
_, width, _ = image.shape
if random.randrange(2):
image = image[:, ::-1]
boxes = boxes.copy()
boxes[:, 0::2] = width - boxes[:, 2::-2]
# landm
landms = landms.copy()
landms = landms.reshape([-1, 5, 2])
landms[:, :, 0] = width - landms[:, :, 0]
tmp = landms[:, 1, :].copy()
landms[:, 1, :] = landms[:, 0, :]
landms[:, 0, :] = tmp
tmp1 = landms[:, 4, :].copy()
landms[:, 4, :] = landms[:, 3, :]
landms[:, 3, :] = tmp1
landms = landms.reshape([-1, 10])
return image, boxes, landms
def _pad_to_square(image, rgb_mean, pad_image_flag):
if not pad_image_flag:
return image
height, width, _ = image.shape
long_side = max(width, height)
image_t = np.empty((long_side, long_side, 3), dtype=image.dtype)
image_t[:, :] = rgb_mean
image_t[0:0 + height, 0:0 + width] = image
return image_t
def _resize_subtract_mean(image, insize, rgb_mean, rgb_std):
interp_methods = [cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_NEAREST, cv2.INTER_LANCZOS4]
interp_method = interp_methods[random.randrange(5)]
image = cv2.resize(image, (insize, insize), interpolation=interp_method)
image = image.astype(np.float32)
image -= rgb_mean
image /= rgb_std
return image.transpose(2, 0, 1)
class preproc(object):
def __init__(self, img_dim, rgb_means, rgb_stds):
self.img_dim = img_dim
self.rgb_means = rgb_means
self.rgb_stds = rgb_stds
def __call__(self, image, targets):
assert targets.shape[0] > 0, "this image does not have gt"
boxes = targets[:, :4].copy()
labels = targets[:, -1].copy()
landm = targets[:, 4:-1].copy()
image_t, boxes_t, labels_t, landm_t, pad_image_flag = _crop(image, boxes, labels, landm, self.img_dim)
image_t = _distort(image_t)
image_t = _pad_to_square(image_t, self.rgb_means, pad_image_flag)
image_t, boxes_t, landm_t = _mirror(image_t, boxes_t, landm_t)
height, width, _ = image_t.shape
image_t = _resize_subtract_mean(image_t, self.img_dim, self.rgb_means, self.rgb_stds)
boxes_t[:, 0::2] /= width
boxes_t[:, 1::2] /= height
landm_t[:, 0::2] /= width
landm_t[:, 1::2] /= height
labels_t = np.expand_dims(labels_t, 1)
targets_t = np.hstack((boxes_t, landm_t, labels_t))
return image_t, targets_t
6,训练参数设置,迭代
加载数据,构建网络,构建损失函数,训练迭代次数,学习率,优化器设置
In [9]
from __future__ import print_function
import os
import paddle
import paddle.optimizer as optim
import time
import datetime
import math
import random
parser = argparse.ArgumentParser(description='Retinaface Training')
parser.add_argument('--training_dataset', default='data/widerface/train/label.txt', help='Training dataset directory')
parser.add_argument('--network', default='mobile0.25', help='Backbone network mobile0.25 or resnet50')
parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float, help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, help='momentum')
parser.add_argument('--resume_net', default=None, help='resume net for retraining')
parser.add_argument('--resume_epoch', default=0, type=int, help='resume iter for retraining')
parser.add_argument('--weight_decay', default=5e-4, type=float, help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float, help='Gamma update for SGD')
parser.add_argument('--save_folder', default='./test/', help='Location to save checkpoint models')
args = parser.parse_known_args()[0]
rgb_mean = (104, 117, 123) # bgr order
rgb_std = (57.1,57.4,58.4)
num_classes = 2
img_dim = cfg['image_size']
num_gpu = cfg['ngpu']
batch_size = cfg['batch_size']
max_epoch = cfg['epoch']
gpu_train = cfg['gpu_train']
num_workers = args.num_workers
momentum = args.momentum
weight_decay = args.weight_decay
initial_lr = args.lr
gamma = args.gamma
training_dataset = args.training_dataset
save_folder = args.save_folder
net = RetinaFace(cfg=cfg)
print("Printing net...")
print(net)
if args.resume_net is not None:
print('Loading resume network...')
state_dict = paddle.load(args.resume_net)
# create new OrderedDict that does not contain module.
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict.items():
head = k[:7]
if head == 'module.':
name = k[7:] # remove module.
else:
name = k
new_state_dict[name] = v
net.set_state_dict(new_state_dict)
if num_gpu > 1 and gpu_train:
net = paddle.DataParallel(net)
optimizer = optim.Momentum(parameters=net.parameters(), learning_rate=initial_lr, momentum=momentum, weight_decay=weight_decay)
criterion = MultiBoxLoss(num_classes, 0.35, True, 0, True, 7, 0.35, False)
priorbox = PriorBox(cfg, image_size=(img_dim, img_dim))
with paddle.no_grad():
priors = priorbox.forward()
def train():
net.train()
epoch = 0 + args.resume_epoch
print('Loading Dataset...')
dataset = WiderFaceDetection(training_dataset, preproc(img_dim, rgb_mean, rgb_std))
epoch_size = math.ceil(len(dataset) / batch_size)
stepvalues = (cfg['decay1'] * epoch_size, cfg['decay2'] * epoch_size)
step_index = 0
if args.resume_epoch > 0:
start_iter = args.resume_epoch * epoch_size
else:
start_iter = 0
max_iter = max_epoch * epoch_size - start_iter
batch_iterator = make_dataloader(dataset, shuffle=True, batchsize=batch_size, distributed=False, num_workers=0, num_iters=max_iter, start_iter=0, collate_fn=detection_collate)
iteration = start_iter
for images, labels in batch_iterator:
if iteration % epoch_size == 0:
if (epoch % 5 == 0 and epoch > 0) or (epoch % 5 == 0 and epoch > cfg['decay1']):
paddle.save(net.state_dict(), save_folder + cfg['name']+ '_epoch_' + str(epoch) + '.pdparams')
epoch += 1
load_t0 = time.time()
if iteration in stepvalues:
step_index += 1
lr = adjust_learning_rate(optimizer, gamma, epoch, step_index, iteration, epoch_size)
# forward
out = net(images)
# backprop
loss_l, loss_c, loss_landm = criterion(out, priors, [anno for anno in labels])
loss = cfg['loc_weight'] * loss_l + loss_c + loss_landm
loss.backward()
optimizer.step()
optimizer.clear_gradients()
load_t1 = time.time()
batch_time = load_t1 - load_t0
eta = int(batch_time * (max_iter - iteration))
print('Epoch:{}/{} || Epochiter: {}/{} || Iter: {}/{} || Loc: {:.4f} Cla: {:.4f} Landm: {:.4f} || LR: {:.8f} || Batchtime: {:.4f} s || ETA: {}'
.format(epoch, max_epoch, (iteration % epoch_size) + 1,
epoch_size, iteration + 1, max_iter, loss_l.item(), loss_c.item(), loss_landm.item(), lr, batch_time, str(datetime.timedelta(seconds=eta))))
iteration += 1
paddle.save(net.state_dict(), save_folder + cfg['name'] + '_Final.pdparams')
def adjust_learning_rate(optimizer, gamma, epoch, step_index, iteration, epoch_size):
"""Sets the learning rate
# Adapted from PyTorch Imagenet example:
"""
warmup_epoch = -1
if epoch
Loading Dataset...
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:9: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use arr[tuple(seq)] instead of arr[seq]. In the future this will be interpreted as an array index, arr[np.array(seq)], which will result either in an error or a different result.
if __name__ == '__main__':
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:152: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use arr[tuple(seq)] instead of arr[seq]. In the future this will be interpreted as an array index, arr[np.array(seq)], which will result either in an error or a different result.
Epoch:1/250 || Epochiter: 1/403 || Iter: 1/100750 || Loc: 5.5039 Cla: 18.9180 Landm: 21.8879 || LR: 0.00100000 || Batchtime: 0.8275 s || ETA: 23:09:30
Epoch:1/250 || Epochiter: 2/403 || Iter: 2/100750 || Loc: 5.5344 Cla: 18.5185 Landm: 21.6857 || LR: 0.00100000 || Batchtime: 0.5799 s || ETA: 16:13:40
Epoch:1/250 || Epochiter: 3/403 || Iter: 3/100750 || Loc: 5.1545 Cla: 16.1501 Landm: 20.6097 || LR: 0.00100000 || Batchtime: 0.3594 s || ETA: 10:03:30
Epoch:1/250 || Epochiter: 4/403 || Iter: 4/100750 || Loc: 5.1112 Cla: 14.2228 Landm: 20.8187 || LR: 0.00100000 || Batchtime: 0.4798 s || ETA: 13:25:35
Epoch:1/250 || Epochiter: 5/403 || Iter: 5/100750 || Loc: 4.9339 Cla: 12.7024 Landm: 20.1817 || LR: 0.00100000 || Batchtime: 0.3922 s || ETA: 10:58:28
Epoch:1/250 || Epochiter: 6/403 || Iter: 6/100750 || Loc: 4.9495 Cla: 12.1982 Landm: 21.1817 || LR: 0.00100000 || Batchtime: 0.4395 s || ETA: 12:17:59
Epoch:1/250 || Epochiter: 7/403 || Iter: 7/100750 || Loc: 4.8757 Cla: 11.8493 Landm: 19.9921 || LR: 0.00100000 || Batchtime: 0.3520 s || ETA: 9:51:00
Epoch:1/250 || Epochiter: 8/403 || Iter: 8/100750 || Loc: 4.7777 Cla: 10.8863 Landm: 20.3447 || LR: 0.00100000 || Batchtime: 0.4070 s || ETA: 11:23:19
Epoch:1/250 || Epochiter: 9/403 || Iter: 9/100750 || Loc: 4.7849 Cla: 8.2906 Landm: 19.6271 || LR: 0.00100000 || Batchtime: 0.5299 s || ETA: 14:49:42
Epoch:1/250 || Epochiter: 10/403 || Iter: 10/100750 || Loc: 4.4964 Cla: 9.6688 Landm: 20.5572 || LR: 0.00100000 || Batchtime: 0.4078 s || ETA: 11:24:44
Epoch:1/250 || Epochiter: 11/403 || Iter: 11/100750 || Loc: 4.8028 Cla: 8.2961 Landm: 19.0736 || LR: 0.00100000 || Batchtime: 0.4680 s || ETA: 13:05:47
Epoch:1/250 || Epochiter: 12/403 || Iter: 12/100750 || Loc: 4.4659 Cla: 8.8183 Landm: 19.5600 || LR: 0.00100000 || Batchtime: 0.4338 s || ETA: 12:08:17
Epoch:1/250 || Epochiter: 13/403 || Iter: 13/100750 || Loc: 4.7572 Cla: 7.3842 Landm: 19.5515 || LR: 0.00100000 || Batchtime: 0.3566 s || ETA: 9:58:45
Epoch:1/250 || Epochiter: 14/403 || Iter: 14/100750 || Loc: 4.4520 Cla: 7.4838 Landm: 19.3934 || LR: 0.00100000 || Batchtime: 0.4300 s || ETA: 12:01:54
Epoch:1/250 || Epochiter: 15/403 || Iter: 15/100750 || Loc: 4.4183 Cla: 7.6439 Landm: 19.8088 || LR: 0.00100000 || Batchtime: 0.3954 s || ETA: 11:03:46
Epoch:1/250 || Epochiter: 16/403 || Iter: 16/100750 || Loc: 4.5246 Cla: 6.6345 Landm: 19.4181 || LR: 0.00100000 || Batchtime: 0.3990 s || ETA: 11:09:51
Epoch:1/250 || Epochiter: 17/403 || Iter: 17/100750 || Loc: 4.5214 Cla: 5.8815 Landm: 18.9220 || LR: 0.00100000 || Batchtime: 0.3920 s || ETA: 10:58:05
Epoch:1/250 || Epochiter: 18/403 || Iter: 18/100750 || Loc: 4.4529 Cla: 6.2802 Landm: 18.9054 || LR: 0.00100000 || Batchtime: 0.4728 s || ETA: 13:13:41
Epoch:1/250 || Epochiter: 19/403 || Iter: 19/100750 || Loc: 4.3458 Cla: 5.9653 Landm: 19.6959 || LR: 0.00100000 || Batchtime: 0.3720 s || ETA: 10:24:32
Epoch:1/250 || Epochiter: 20/403 || Iter: 20/100750 || Loc: 4.3320 Cla: 5.3611 Landm: 18.2379 || LR: 0.00100000 || Batchtime: 0.4461 s || ETA: 12:28:56
Epoch:1/250 || Epochiter: 21/403 || Iter: 21/100750 || Loc: 4.2572 Cla: 5.0751 Landm: 19.0970 || LR: 0.00100000 || Batchtime: 0.4399 s || ETA: 12:18:28
Epoch:1/250 || Epochiter: 22/403 || Iter: 22/100750 || Loc: 4.3705 Cla: 4.8014 Landm: 17.8947 || LR: 0.00100000 || Batchtime: 0.6961 s || ETA: 19:28:33
Epoch:1/250 || Epochiter: 23/403 || Iter: 23/100750 || Loc: 4.2417 Cla: 4.6365 Landm: 18.2330 || LR: 0.00100000 || Batchtime: 0.5477 s || ETA: 15:19:28
Epoch:1/250 || Epochiter: 24/403 || Iter: 24/100750 || Loc: 3.9981 Cla: 4.8140 Landm: 17.9373 || LR: 0.00100000 || Batchtime: 0.4679 s || ETA: 13:05:25
Epoch:1/250 || Epochiter: 25/403 || Iter: 25/100750 || Loc: 4.2646 Cla: 4.2984 Landm: 19.7434 || LR: 0.00100000 || Batchtime: 0.3951 s || ETA: 11:03:14
Epoch:1/250 || Epochiter: 26/403 || Iter: 26/100750 || Loc: 4.3223 Cla: 4.3522 Landm: 18.5542 || LR: 0.00100000 || Batchtime: 0.4015 s || ETA: 11:14:05
Epoch:1/250 || Epochiter: 27/403 || Iter: 27/100750 || Loc: 4.1652 Cla: 4.4780 Landm: 17.2275 || LR: 0.00100000 || Batchtime: 0.3671 s || ETA: 10:16:20
Epoch:1/250 || Epochiter: 28/403 || Iter: 28/100750 || Loc: 4.1778 Cla: 4.2569 Landm: 17.9795 || LR: 0.00100000 || Batchtime: 0.3724 s || ETA: 10:25:06
Epoch:1/250 || Epochiter: 29/403 || Iter: 29/100750 || Loc: 4.2219 Cla: 4.1784 Landm: 18.4573 || LR: 0.00100000 || Batchtime: 0.3764 s || ETA: 10:31:52
Epoch:1/250 || Epochiter: 30/403 || Iter: 30/100750 || Loc: 3.8601 Cla: 4.1411 Landm: 17.5710 || LR: 0.00100000 || Batchtime: 0.4443 s || ETA: 12:25:55
Epoch:1/250 || Epochiter: 31/403 || Iter: 31/100750 || Loc: 4.1699 Cla: 3.9541 Landm: 17.5772 || LR: 0.00100000 || Batchtime: 0.4302 s || ETA: 12:02:06
Epoch:1/250 || Epochiter: 32/403 || Iter: 32/100750 || Loc: 3.9781 Cla: 3.9588 Landm: 17.0395 || LR: 0.00100000 || Batchtime: 0.4304 s || ETA: 12:02:33
Epoch:1/250 || Epochiter: 33/403 || Iter: 33/100750 || Loc: 4.0470 Cla: 3.8377 Landm: 17.3675 || LR: 0.00100000 || Batchtime: 0.4221 s || ETA: 11:48:36
Epoch:1/250 || Epochiter: 34/403 || Iter: 34/100750 || Loc: 3.8755 Cla: 3.9044 Landm: 17.1435 || LR: 0.00100000 || Batchtime: 0.4630 s || ETA: 12:57:07
Epoch:1/250 || Epochiter: 35/403 || Iter: 35/100750 || Loc: 3.7425 Cla: 3.8776 Landm: 16.4029 || LR: 0.00100000 || Batchtime: 0.3946 s || ETA: 11:02:25
Epoch:1/250 || Epochiter: 36/403 || Iter: 36/100750 || Loc: 3.9764 Cla: 3.9707 Landm: 16.8414 || LR: 0.00100000 || Batchtime: 0.5842 s || ETA: 16:20:40
Epoch:1/250 || Epochiter: 37/403 || Iter: 37/100750 || Loc: 3.7441 Cla: 3.8408 Landm: 17.6619 || LR: 0.00100000 || Batchtime: 0.4351 s || ETA: 12:10:19
Epoch:1/250 || Epochiter: 38/403 || Iter: 38/100750 || Loc: 3.9364 Cla: 3.7047 Landm: 18.6355 || LR: 0.00100000 || Batchtime: 0.3682 s || ETA: 10:18:01
Epoch:1/250 || Epochiter: 39/403 || Iter: 39/100750 || Loc: 3.7350 Cla: 3.8814 Landm: 16.8114 || LR: 0.00100000 || Batchtime: 0.3889 s || ETA: 10:52:45
Epoch:1/250 || Epochiter: 40/403 || Iter: 40/100750 || Loc: 3.5163 Cla: 3.8605 Landm: 16.5092 || LR: 0.00100000 || Batchtime: 0.4335 s || ETA: 12:07:37
Epoch:1/250 || Epochiter: 41/403 || Iter: 41/100750 || Loc: 3.7482 Cla: 3.6833 Landm: 16.7456 || LR: 0.00100000 || Batchtime: 0.4363 s || ETA: 12:12:24
Epoch:1/250 || Epochiter: 42/403 || Iter: 42/100750 || Loc: 3.6396 Cla: 3.6600 Landm: 16.9524 || LR: 0.00100000 || Batchtime: 0.3985 s || ETA: 11:08:51
Epoch:1/250 || Epochiter: 43/403 || Iter: 43/100750 || Loc: 3.6277 Cla: 3.5343 Landm: 15.3870 || LR: 0.00100000 || Batchtime: 0.4476 s || ETA: 12:31:15
Epoch:1/250 || Epochiter: 44/403 || Iter: 44/100750 || Loc: 3.6305 Cla: 3.8723 Landm: 15.8916 || LR: 0.00100000 || Batchtime: 0.3889 s || ETA: 10:52:42
Epoch:1/250 || Epochiter: 45/403 || Iter: 45/100750 || Loc: 3.4999 Cla: 3.7035 Landm: 16.0365 || LR: 0.00100000 || Batchtime: 0.3781 s || ETA: 10:34:32
Epoch:1/250 || Epochiter: 46/403 || Iter: 46/100750 || Loc: 3.5424 Cla: 3.6261 Landm: 16.0393 || LR: 0.00100000 || Batchtime: 0.4740 s || ETA: 13:15:38
Epoch:1/250 || Epochiter: 47/403 || Iter: 47/100750 || Loc: 3.7910 Cla: 3.6140 Landm: 16.3321 || LR: 0.00100000 || Batchtime: 0.3976 s || ETA: 11:07:20
Epoch:1/250 || Epochiter: 48/403 || Iter: 48/100750 || Loc: 3.5407 Cla: 3.6659 Landm: 15.9662 || LR: 0.00100000 || Batchtime: 0.3946 s || ETA: 11:02:21
Epoch:1/250 || Epochiter: 49/403 || Iter: 49/100750 || Loc: 3.2723 Cla: 3.5321 Landm: 15.0109 || LR: 0.00100000 || Batchtime: 0.4122 s || ETA: 11:31:50
Epoch:1/250 || Epochiter: 50/403 || Iter: 50/100750 || Loc: 3.6369 Cla: 3.6536 Landm: 16.7837 || LR: 0.00100000 || Batchtime: 0.3930 s || ETA: 10:59:35
Epoch:1/250 || Epochiter: 51/403 || Iter: 51/100750 || Loc: 3.2572 Cla: 3.5005 Landm: 16.94
在AI Studio可直接运行,欢迎Fork Paddle复现RetinaFace详细解析 – 飞桨AI Studio – 人工智能学习与实训社区
Original: https://blog.csdn.net/qq_34106574/article/details/121427978
Author: AI小白龙
Title: 【人脸检测】Paddle复现RetinaFace详细解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531664/
转载文章受原作者版权保护。转载请注明原作者出处!