

概要
【零基础-1】PaddlePaddle学习Bert_ 一只博客-CSDN博客![]()
 https://blog.csdn.net/qq_42276781/article/details/121488335 ;
https://blog.csdn.net/qq_42276781/article/details/121488335 ;
Cell 3
调用bert模型用的tokenizer
tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained('bert-base-chinese')
inputs_1 = tokenizer('今天天气真好')
print(inputs_1)
inputs_2 = tokenizer('明天会下雨吗')
print(inputs_2)
调用bert预训练分词工具,这里的bert-base-chinese,结合论文来看应该是bert-base的中文版。

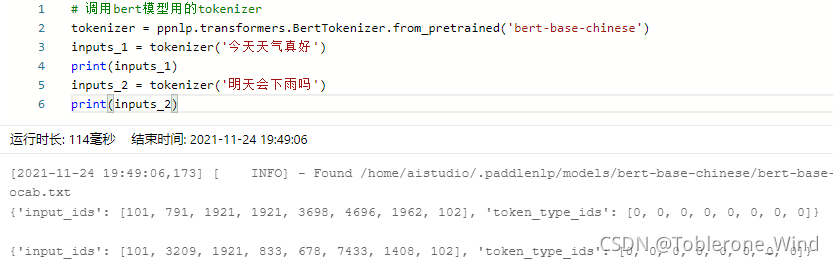
tokenizer的主要工作应该是文本向量化,即把中文句子中的每个字转换成与其对应的数字编码,使得机器可以理解。
从输出结果来看,第一个id一定是101,最后一个id一定是102,剩下的id分别与单个汉字对应。对照两个输出结果,可以发现”天”对应的数字编码为1921,是固定的,并不会因为输入而改变。
Cell 4
输出训练集的前 10 条样本
for idx, example in enumerate(train_ds):
if idx < 10:
print(example)
这里的enumerate是python的内置函数,用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中,详见
Python enumerate() 函数 | 菜鸟教程 (runoob.com)![]() https://www.runoob.com/python/python-func-enumerate.html ;这段代码就是输出训练集中的前10个样本,看看里面的内容。
https://www.runoob.com/python/python-func-enumerate.html ;这段代码就是输出训练集中的前10个样本,看看里面的内容。

可以发现训练集中的样本没有qid,文本是对某个事物的评价,label为1表示该文本是正向评价,0表示该为本是负向评价。
Cell 5
超参数
EPOCHS = 10 # 训练的轮数
BATCH_SIZE = 8 # 批大小
MAX_LEN = 300 # 文本最大长度
LR = 1e-5 # 学习率
WARMUP_STEPS = 100 # 热身步骤
T_TOTAL = 1000 # 总步骤
这里是定义了一些参数,具体有什么用途我也不是很清楚。
Cell 6
将文本内容转化成模型所需要的token id
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
"""
encoded_inputs = tokenizer(text=example["text"], max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
这段代码的理解可以对照下面这个文档链接
PaddleNLP Transformer API — PaddleNLP 文档![]() https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers.html?highlight=convert_example#id2 ;Builds model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. And creates a mask from the two sequences passed to be used in a sequence-pair classification task.
https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers.html?highlight=convert_example#id2 ;Builds model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. And creates a mask from the two sequences passed to be used in a sequence-pair classification task.
这段话大概是说,通过连接和添加特殊标记,从序列或序列对中构建模型for序列分类任务。并从传递的两个序列创建一个掩码,以用于序列对分类任务。
这里函数传入的tokenizer应该就是咱们在Cell 3里引入的tokenizer,max_seq_len就是分词器所能接收的最大句子长度,input_ids就是汉字对应的数字编码,token_type_ids暂时还不知的是什么意思。
is_test就是用来区分是否是测试集,如果不是就额外返回样本标签。
Original: https://blog.csdn.net/qq_42276781/article/details/121523268
Author: Toblerone_Wind
Title: 【零基础-2】PaddlePaddle学习Bert
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531634/
转载文章受原作者版权保护。转载请注明原作者出处!