

Paper地址: https://arxiv.org/abs/2203.08991
GitHub链接: amodaresi/AdapLeR
随着AI软硬件基础设施的日趋完善(包括算法框架、推理引擎、编译器与底层硬件等), 从算法或模型视角的性能优化,已经成为降低计算复杂度、节省资源成本的必不可少的技术手段。
前言
基于 生成式自监督训练(Generative Self-supervised Learning),预训练模型能够充分掌握语境相关的知识与信息,典型代表如BERT预训练任务MLM、ViT预训练任务MAE、推荐模型预训练任务Next-query Prediction等。 对于BERT模型而言,在充分的大规模预训练之后,针对特定的下游任务,凭借语境知识与少量Token信息,便足以完成NLP任务。因此,基于Sequence的Token表示冗余,可通过逐层消减Sequence length的方式、达成BERT推理加速。
基于BERT模型压缩技术(如剪枝、量化等),可实现BERT推理加速,本质而言实现了 模型结构精简(静态优化,推理时模型结构固定)。从另一个角度而言, 由于Sequence存在表示冗余,因此BERT模型中不同Layer的输出特征序列、可通过动态方式进行Sequence length的消减(Sample-driven length reduction),本质而言实现了 数据结构精简(动态优化,推理时数据结构随Sample变化)。 AdapLeR便是一种基于Sequence length reduction的动态优化策略,以实现BERT推理加速。
BERT/Transformer模型压缩与推理加速,更为详细的讨论可参考:
实现方法


如上图所示, AdapLeR在每个BERT layer设置了Contribution predictor (CP),用于估计第l个Layer输出特征的Per-token saliency (每个Token的重要性),以消减Less contributing tokens,从而实现Inference加速。由于[CLS] token起Pooler作用(代表整个Sequence的语义或表征),直接反映下游任务的精度表现,因此[CLS] token不会被消减(尽管CP预测得分可能较低)。且在Inference阶段(Batch size=1),相比于模型整体的推理耗时,CP的预测耗时可忽略。
AdapLeR的动态优化策略或动态推理方式,依赖于每个Layer的CP与Uniform-level阈值,执行方式如下:


class TFbertLRExpHead(tf.keras.layers.Layer):
def __init__(self, config: BertConfig, layer_no: int, **kwargs):
super().__init__(**kwargs)
self.pre_head = tf.keras.layers.Dense(
units=32,
kernel_initializer=get_initializer(config.initializer_range),
name=f"exp_head_pre_{layer_no+1}",
)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = get_tf_activation(config.hidden_act)
else:
self.intermediate_act_fn = config.hidden_act
self.head = tf.keras.layers.Dense(
units=1,
kernel_initializer=get_initializer(config.initializer_range),
name=f"exp_head_{layer_no+1}",
)
def call(self, hidden_states: tf.Tensor, effective_mask: tf.Tensor) -> tf.Tensor:
batch_size = tf.shape(effective_mask)[0]
# CLS token
new_mask = tf.concat([tf.ones((batch_size, 1)), effective_mask[:, 1:]], axis=1)
# First MLP layer
pre_head = self.pre_head(hidden_states)
pre_head = self.intermediate_act_fn(pre_head)
# Second MLP layer, softmax and per-token normalization
explanation_logits = tf.squeeze(self.head(pre_head), axis=-1)
explanations = tf.nn.softmax(explanation_logits, axis=-1) * new_mask
explanations = explanations / (tf.reduce_sum(explanations, axis=-1, keepdims=True) + 1e-15)
return explanations

explanations represent the contribution scores
dyna_lengths = tf.reduce_sum(acc_effective_mask, axis=-1) + 1 # for CLS
delta = tf.expand_dims(1./dyna_lengths * self.ETA[i], axis=-1)
retention_mask = tf.squeeze((1 - ((1 - explanations) * acc_effective_mask)) >= delta, axis=0)
effective_attention_mask = tf.boolean_mask(effective_attention_mask, retention_mask, axis=3)
hidden_states = tf.boolean_mask(hidden_states, retention_mask, axis=1)
为了实现 AdapLeR的动态推理,需要训练CP与
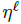 。具体训练方法如下:
。具体训练方法如下:
- 首先,在具体的下游任务上(如GLUE tasks、SQuaD等) 微调BERT预训练模型;
- 然后,收集每个样本(Text sequence)的显著性得分,即Output logits关于Input features的 Gradient-based saliencies:

with tf.GradientTape() as tape:
outputs = bert(inputs, training=training, output_hidden_states=True)
hidden_states = outputs.hidden_states
logits = outputs.logits
grads * features
grads = tape.batch_jacobian(logits, hidden_states[0])
saliency = grads * tf.expand_dims(hidden_states[0], axis=1)
Aggregate
if saliency_agg == "L2":
saliency = tf.norm(saliency, axis=-1)
elif saliency_agg == "mean":
saliency = tf.reduce_sum(saliency, axis=-1)
- 接下来,通过两个优化进程、分别训练更新CP与(训练期间,冻结BERT的Backone参数)。为了在训练过程中,有效反映Length reduction对梯度反传的影响,并适应Batch-wise training时不同Sample的Length reduction结构,AdapLeR引入了 Soft-removal function,以软化分布的Mask value消减Sequence length、并将其叠加到Attention mask。如下所示, Soft-mask根据Contribution score的取值、分成了两段区域:


- Contribution predictor (CP)的训练:
- 优化目标包括Task-specific loss与KL散度,KL散度表示CP预测输出、与前述收集的Gradient-based saliencies之间的差距:


训练期间,为了凸显[CLS] token的贡献,需要结合可训练变量
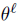 (该变量在CP训练期间不更新,并在训练期间一同更新)、 重新调制CP预测输出分布:
(该变量在CP训练期间不更新,并在训练期间一同更新)、 重新调制CP预测输出分布:

- 的训练 (与 一同训练):
- 优化目标包括Task-specific loss与Length loss,Length loss表示Effective mask (代码里表示为acc_effective_mask)取指数之后的累加:
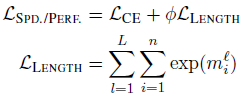
CP与(
,)的训练代码如下,二者分别按各自的优化目标予以更新:
labels = inputs[1]
inputs = inputs[0]
batch_size = tf.cast(tf.shape(inputs["input_ids"])[0], tf.float32)
Train classifier
with tf.GradientTape() as tape, tf.GradientTape(watch_accessed_variables=False) as tape2:
tape2.watch([self.bert.encoder.ETA, self.bert.encoder.THETA_PR])
outputs = bert(inputs, output_hidden_states=True, training=True, output_explanations=True, output_lengths=True)
loss = tf.reduce_sum(self.loss_fn(labels, outputs.logits, sample_weight=tf.gather(self.class_weights, labels))) / batch_size
weight_loss = tf.range(self.config.num_hidden_layers, 0, -1, dtype=tf.float32)
with tape2.stop_recording():
# the loss for CP
kl_losses = tf.stack(self.compute_head_lossV5(sal_inputs, outputs.explanations, inputs["attention_mask"], input_mode="simple"))
weighted_kl_losses = weight_loss * kl_losses
kl_loss = tf.reduce_sum(weighted_kl_losses)
effective_gamma = self.GAMMA
total_loss = loss + effective_gamma * kl_loss
divided_total_loss = total_loss / tf.cast(self._ACCUM_STEPS, tf.float32)
with tape.stop_recording():
# the loss for eta and theta
stacked_lengths = tf.stack(outputs.lengths)
length_loss = tf.reduce_sum(stacked_lengths, axis=0)
length_loss = tf.reduce_mean(length_loss, axis=0)
combined_loss = loss + self.PHI * length_loss
divided_combined_loss = combined_loss / tf.cast(self._ACCUM_STEPS, tf.float32)
Compute gradients for each optimize process
all_gradients = tape.gradient(divided_total_loss, self.trainable_variables)
zeta_grads = tape2.gradient(divided_combined_loss, [self.bert.encoder.ETA, self.bert.encoder.THETA_PR])
zeta_grads[1] = zeta_grads[1] / (self.bert.encoder.THETA + 1e-7)
if self._ACCUM_STEPS > 1:
self.gradient_accumulator(all_gradients)
self.speedup_gradient_accumulator(zeta_grads)
tf.cond(self.gradient_accumulator.step == self._ACCUM_STEPS, self.apply_gradients, self.dummy_apply_gradients)
else:
self.apply_gradients(all_gradients, zeta_grads)
self.bert.encoder.ETA.assign(tf.maximum(tf.minimum(tf.ones(12), self.bert.encoder.ETA), 1e-2 * tf.ones(12)))
实验结果
相比于模型结构精简(DistilBERT)、与其他Length reduction方法(PoWER-BERT、TR-BERT),AdapLeR在精度损失相接近的情况下,获得了更为显著的加速效果。

针对不同的下游任务、以及不同的输入样本,Sequence length的动态消减结构有所不同、且呈现出逐层消减的效果。

Original: https://blog.csdn.net/nature553863/article/details/123759084
Author: Law-Yao
Title: AdapLeR——基于Adaptive Length Reduction的BERT推理优化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531602/
转载文章受原作者版权保护。转载请注明原作者出处!