

本文主要对李宏毅机器学习的课程进行了简单的总结。首先是解释了self-attention自注意力机制的原理,还有multi-head attention多头注意力机制、masked multi-head attention掩膜多头注意力机制,自注意力机制和CNN、RNN的区别。其次是解释了Transformer的原理,包括encoder、decoder的流程。最后介绍了AT、NAT的区别,copy mechanism,guided mechanism,beam search等。
1. Self-attention
on-hot encoding 词汇量太大,导致一个向量特别长
word embedding 意义相近的词在空间坐标系中位置相近,大大减小了向量维度。
输入是一组向量,输出有三种情况:
- 每一个输入的向量都能输出一个标签
- 整个模型只输出一个标签
- 输出的标签数量由模型决定(seq-to-seq:对话、翻译、问答等)
Self-attention:自注意力机制,考虑句子上下文,而且可以并行输出
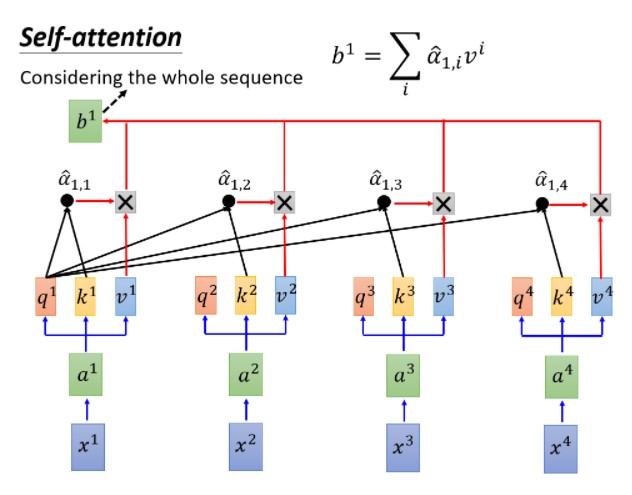

其中,q1=wq×a1,k1=wk×a1,v1=wv×a1,wq,wk,wv是需要模型学习的参数
a11=k1×q1,a12=k2×q1,a13=k3×q1,a14=k4×q1,
b1=v1×a11+v2×a12+v3×a13+v4×a14
Multi-Head attention:多头注意力机制
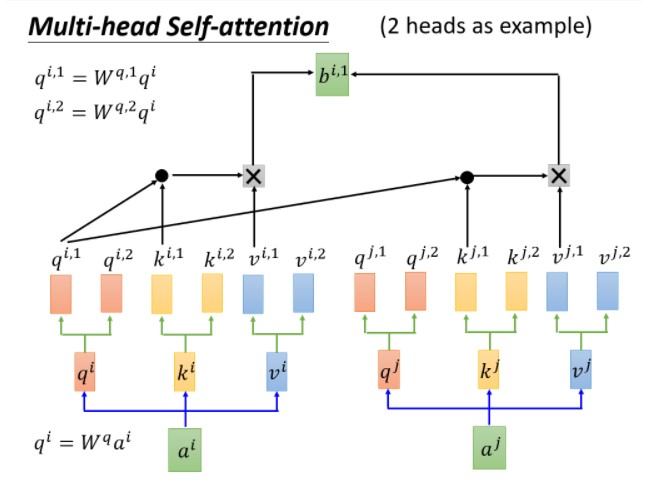
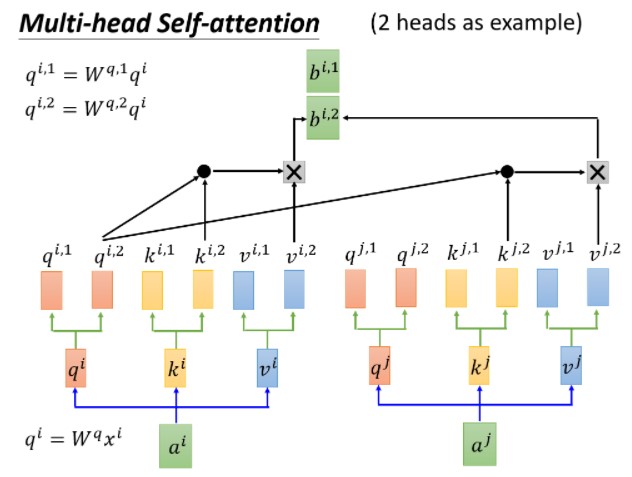
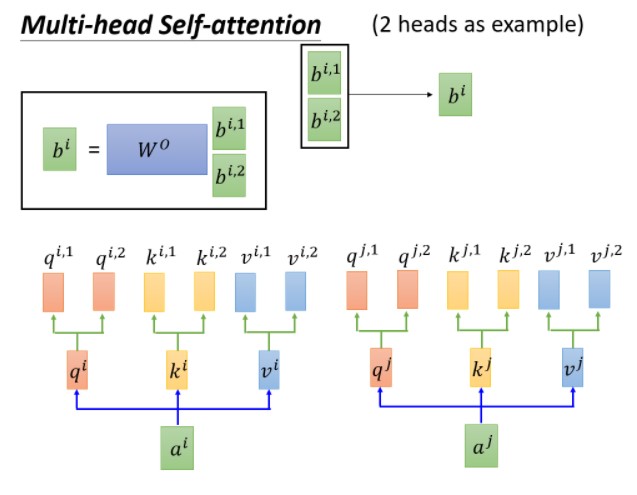
这次使用了两份wq,wk,wv,以实现不同类型的相关性。获得b11,b12相连接。
虽然自注意力机制可以加入上下文信息,但是没有考虑句子中词汇的位置问题,一个动词在句首还是句尾无法体现出不同。所以有了 Positional Encoding机制,为每一个ai加上一个位置向量ei再输入到自注意力模块,其他和自注意力机制没有区别。
对于 speech的self-attention,因为一段语音太长,可能没办法全部考虑,所以出现了truncated self-attention,只考虑当前token的一小段上下文,而非全部语音,也能提升模型准确度。
对于 图像处理的self-attention,输入的一个向量就是红绿蓝三个通道的像素组成的向量,那么输入向量的数目就是height*width。
self-attention和CNN的区别:
CNN是简化版的self-attention,因为CNN只计算感受野的像素;
self-attention是复杂版的CNN,自动学习哪些像素向量与当前向量有关,相当于自己学习感受野。
CNN适用于小数据量;self-attention适用于大数据量。
self-attention与RNN的区别:
RNN很难考虑上下文信息,且只能依次输出;
self-attention可以考虑到上下文信息,能够并行输出。
; 2. Transformer
TTS:Text-to-Speech文字转语音
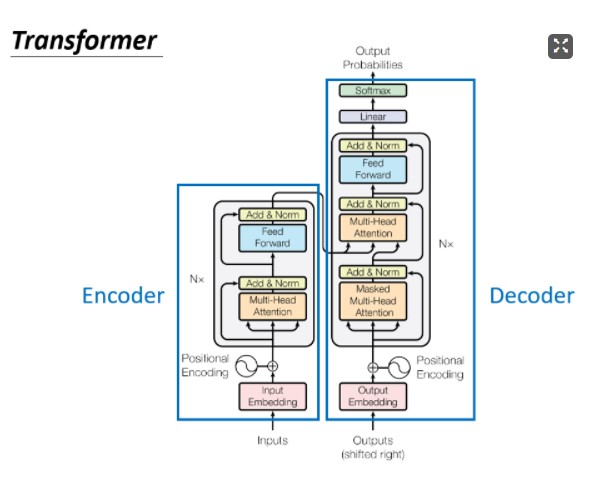
encoder:
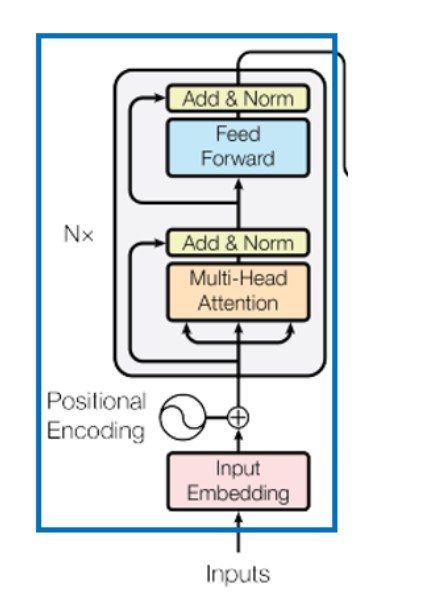
- 对于输入的一组向量,可以先应用位置编码添加位置信息;
- 指向multi-head attention的三个箭头分别表示q,k,v,输入到多头注意力模块获得隐藏层输出b,将原输入加上b进行残差连接(residual connection),也就是图中的Add;
- 获得的和向量进行归一化,公式xi = (xi-mean)/deviation,减去均值除以方差;
- 之后进入前馈网络,获得输出;
- 将3的输出加上前馈网络的输出,再次残差连接;
- 再次归一化,至此encoder的流程结束。
decoder:

decoder的输出是one-hot编码,可能输出多少字,输出的每一个向量就有多长。假如说可能从一千个汉字中输出,那么输出向量的维度就是一千。数值代表了输出该字的概率。
decoder不是并行输出的,上一轮的输出会和之前所有轮的输入一起作为输入。
注意第一个多头注意力机制使用了masked多头注意力机制,也就是说不会再考虑当前向量后面的向量,只考虑前文信息和当前向量的相关性。为什么呢,因为decoder不能并行输出,只能一个一个输出,所以它根本看不到后文信息。
- 将Begin先输入,添加位置信息;
- 指向masked multi-head attention的三个箭头分别表示q,k,v,输入到掩膜多头注意力模块获得隐藏层输出b,将原输入加上b进行残差连接(residual connection),也就是图中的Add;
- 获得的和向量进行归一化,公式xi = (xi-mean)/deviation,减去均值除以方差;
- 由encoder的输出提供k,v,由decoder的3的输出提供q,进行multi-head attention,再加上3的输出进行残差连接以及归一化,这个过程叫做cross attention;
- 之后和encoder的4-5-6相同;
- 最后进入一个线性神经元隐藏层,以及softmax分类层获得输出向量;
- 获得了第一个输出字之后,重新丢进decoder,和之前的begin一起。那么这次3输出的q就是第一个输出字和begin进行掩膜多头注意力机制获得的q,再重新进行之后的流程。
以上是autoregressive decoder—— AT decoder的结构,下面介绍一下它和non-autoregressive decoder—— NAT decoder的 区别:

- NAT是并行输出的,直接丢进去一排begin就好
- NAT比较容易自主决定输出向量的数目
● 一个做法是,另外learn一个 Classifier,这个Classifier,它吃encoder的output,然后输出一个数字,比如说是4,然后NAT的decoder就会吃到4个begin的token, 然后NAT decoder就会产生4个中文的字符。这个数字代表decoder应该要输出的长度。
● 另一种可能做法就是,给它一堆begin的token,假设说现在输出的句子的长度绝对不会超过 300 个字,假设一个上限。然后给它 300 个begin,就会输出 300 个字,再看看什么地方输出end,不管end右边的的输出。
模型训练的追求是 cross entropy越小越好,但是选择模型的要求是 BLEU分数越高越好。
teacher forcing:在训练模型时,不会将encoder的输出作为decoder的输入,而是将正确的输出作为decoder的输入。正确的输出叫做 ground truth。
测试的时候,会将encoder的输出作为decoder的输入。这就引出了 mismatch,也叫 exposure bias,在训练的时候,会有意添加几个错误的输出作为decoder的输入,叫做 scheduled asmpling,以免模型准确率太低。
copy mechanism:模型不认识的一段文字,会直接复制作为输出,比如人名。
guided attention:在训练任务时,要按照输入的顺序进行输出,不会先看后面的话去输出第一个字。
beam search:每次选取前K个概率最高的输出作为下一轮的输入。
Original: https://blog.csdn.net/qq_45792472/article/details/121382378
Author: KathyW_
Title: 【自然语言处理】self-attention和Transformer的详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531540/
转载文章受原作者版权保护。转载请注明原作者出处!