

原文链接:点此转跳
来源:Empirical Software Engineering, 2019
一、背景及介绍
这篇论文的工作其实是之前他们所提出的一个模型——DeepCom(DeepCom的具体介绍可看我之前的一篇笔记:点此转跳)的升级版,新名字叫混合DeepCom,可以较好地学习代码的词汇和句法信息,从而提高注释生成的质量。
主要区别如下:
DeepComeHybrid-DeepCom输入仅AST源码+ASTAST遍历策略SBT(包含节点的type和value)SBT(仅包含type,因为源码已经包含了value信息)结构一个编码器,一个解码器,Attention两个编码器,一个解码器,Attentionout-of-vocabulary tokens的处理用节点的类型代替使用驼峰分词translate策略直接用最大概率的token一个个单词生成beam search
主要贡献
- 将代码注释生成任务转化为机器翻译任务。
- 针对Java方法的注释生成任务,搭建了一个基于序列的模型来学习代码的词汇和结构信息。为此提出了一种新的AST遍历方法(structure-based traversal,SBT)来更好地表示代码的结构信息。
- 使用驼峰分词法将许多用户定义的标识符分词,以此减少源代码中的out-of-vocabulary tokens。
二、模型结构及原理
整体结构
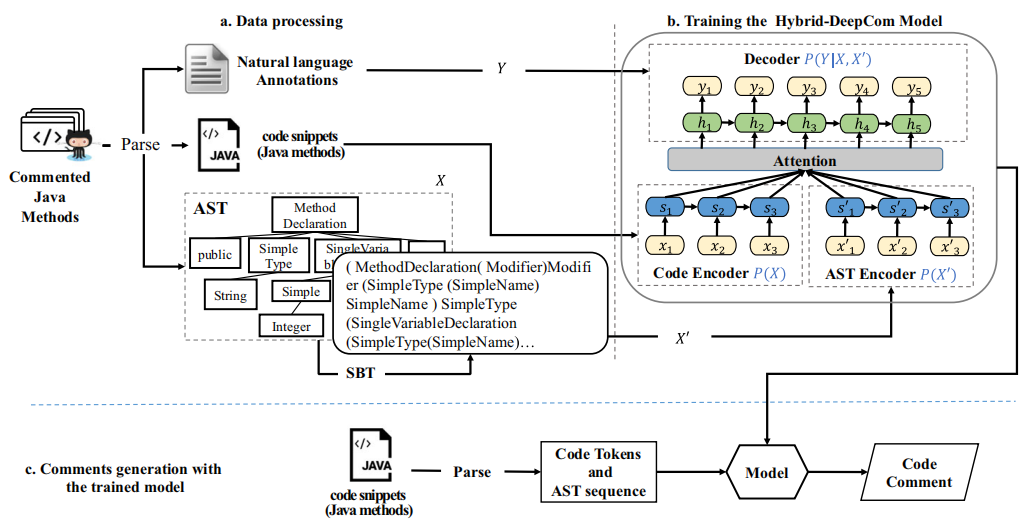

就是一个编码器的输入是SBT遍历后的AST序列,另一个编码器的输入是源码序列,每个编码器都采用Attention进一步加强语义向量C表征能力,两个编码器的语义向量C拼接后送入解码器解码,下图是更细节的结构图:
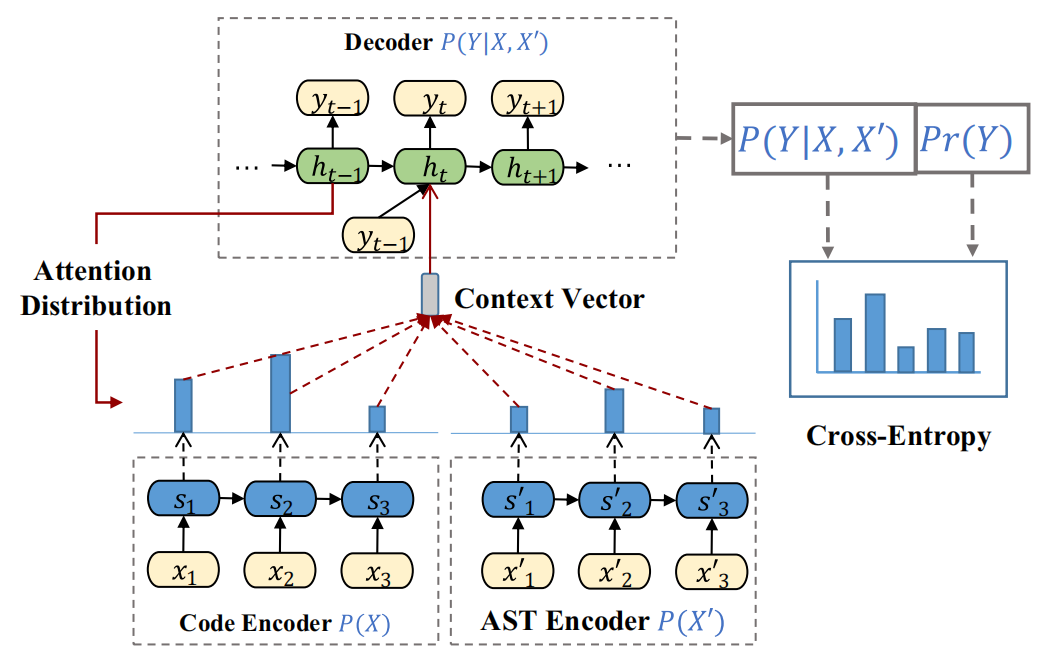
; Encoder
混合deepcom分别用两个编码器来源码和AST序列进行编码。一个编码器学习源码中的词汇信息,另一个编码器学习AST序列中的结构信息。这次论文编码器采用的是GRU,相对于原来的LSTM,也算是一个小改动吧。
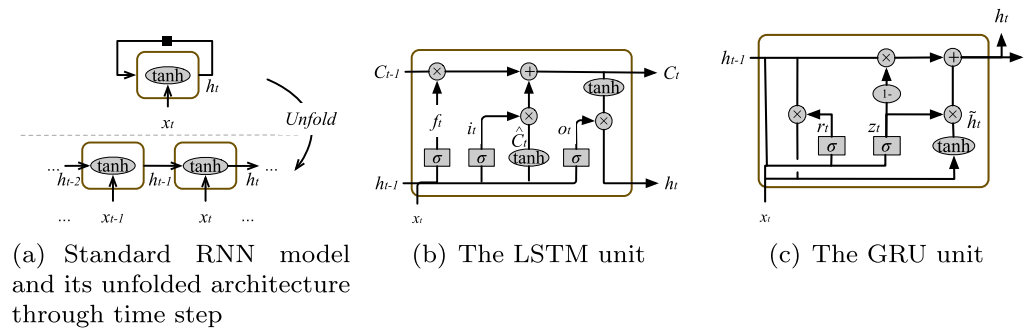
从上图可以发现,GRU其实就是LSTM的变体,减少了许多参数,训练速度更快。在每个时间步t,GRU读取序列的一个token xt,然后更新并记录当前的隐藏状态st,计算表达式如下:
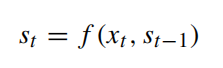
其中f是GRU单元的映射函数,将源语言中的一个单词xt和上一个隐藏状态st-1映射当前隐藏状态st。
Attention
没有加注意力机制的话,解码时用的都是固定的语义向量c。引入注意力机制后,固定的中间语义向量c换成了根据当前生成单词而不断变化的ci,由于混合DeepCom用到两个编码器,这里主要说一下怎么结合两个编码器的attention来计算ci,计算如下:
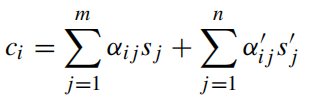
其实嘛,也就是简单相加,左右两边其实就是两个编码器的注意力。参数的意义如下:

权重的计算就是对eij进行softmax,eij是相关性得分,由输出的第i-1个隐藏状态和编码器的第j个隐藏状态的计算得出。
; Decoder
解码器用的也是GRU,没啥好说的,没什么改动,和之前一样,贴个公式吧,加深印象:

就是不断将前一个时刻的输出yi-1作为后一个时刻的输入,输出的是每个字符的概率值,g是概率映射函数,利用上一个时刻输出,当前隐藏状态和当前语义向量计算。
训练目标是最小化交叉熵误差:
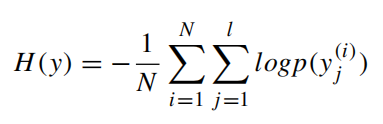
Beam Search
Beam Search是greedy Search的扩展,其返回是一个最有可能的输出序列的列表。在每个时间步长中,Beam Search会保留成本最小的k个令牌作为候选,其中k也叫 beam-width,一个简单的例子如下图,这里设置k=2,因此最后输出列表有两个候选序列。
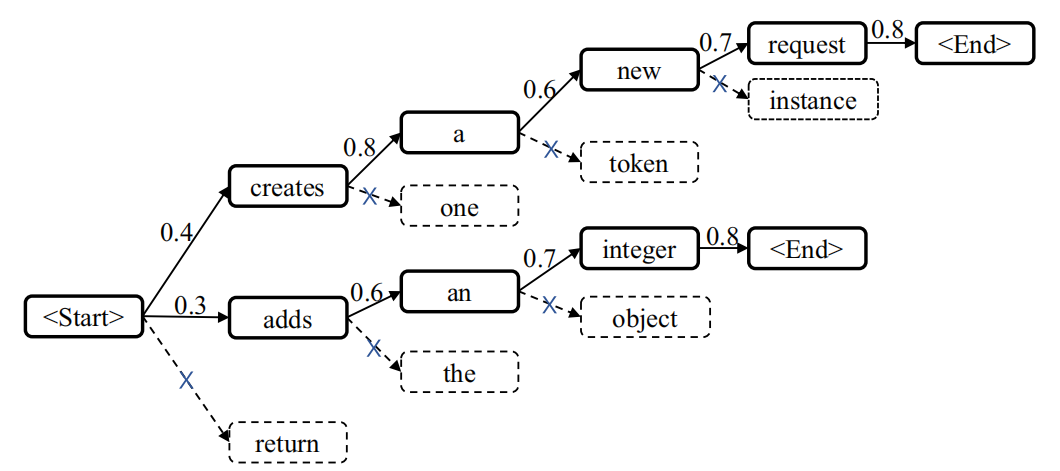
论文里根据Beam Search过程中生成的注释tokens的平均概率进行排序,选择Top1注释作为最终结果。
; SBT
与论文之前的DeepCom提出的基本没什么不同,只不过 一个细节是混合DeepCom对AST进行SBT的时候 只在序列添加AST节点的type,因为节点的类型反映了代码的结构信息。
Reduce Out-of-Vocabulary Tokens
代码除了固定的操作符和关键字外,还有大量用户定义的标识符,这些标识符对语言模型的词汇表有重要影响。如果直接将这些标识符添加进词汇表,其词汇量是非常大的。作者通过观察发现其实大多数标识符都是由几个单词组成的。这些词通常是常见的词,并经常被反复使用。因此,基于一个简单的思考,作者将标识符采用驼峰分词法将其划分为几个单词,以减少源代码中的Out-of-Vocabulary Tokens。经过这番操作,训练集中的tokens数量从542,680减少到47,939。
三、实验
数据集
数据集来自GitHub2015-2016年创建的Java仓库,保留10星以上的项目。
作者也是公布了他们的数据集:点此转跳
- 数据处理
作者首先从这些Java项目中提取Java方法及其相应的Javadoc,使用Javadoc的第一句话作为目标注释,因为根据Javadoc指南,第一句话通常是用来描述Java方法的功能。其次是对代码-注释对进行过滤:过滤掉只有一个单词的Javadac的代码-注释对;排除了setter, getter, constructor和test等注释简单的方法。最后得到了588,108种方法-注释对。
- 数据清洗
- 用@SmallTest、@LargeTest和@MediumTest标记来过滤Java方法。
- 过滤掉Java的重写方法,因为重写方法通常实现的是相同的功能,会导致不必要的重复。
- 过滤掉源码长度大于200的代码-注释对
-
过滤掉注释长度小于4和大于30的代码-注释对
-
词汇表的建立
- 所有单词转换为小写
- 数字和字符串分别用
- 源代码和AST序列的最大长度分别设置为200和500,最大注释长度设置为30,长度小的用
- 所有序列的开始和结尾添分别加
模型参数设置
模型搭建框架——tensorflow
优化器——SGD
模型——单层GRU,隐藏状态与词嵌入维度均为256
学习率——0.5,按0.99的衰减速率衰减
gradients norm——5
beam width——5
评价指标
作者用的评价指标真的过多过于复杂, 分为Information Retrieval (IR) metrics 和 Machine Translation (MT),这里就不罗列了,主要关注BLEU吧

; RQ1: How effective is Hybrid-DeepCom compared with the state-of-the-art baselines?
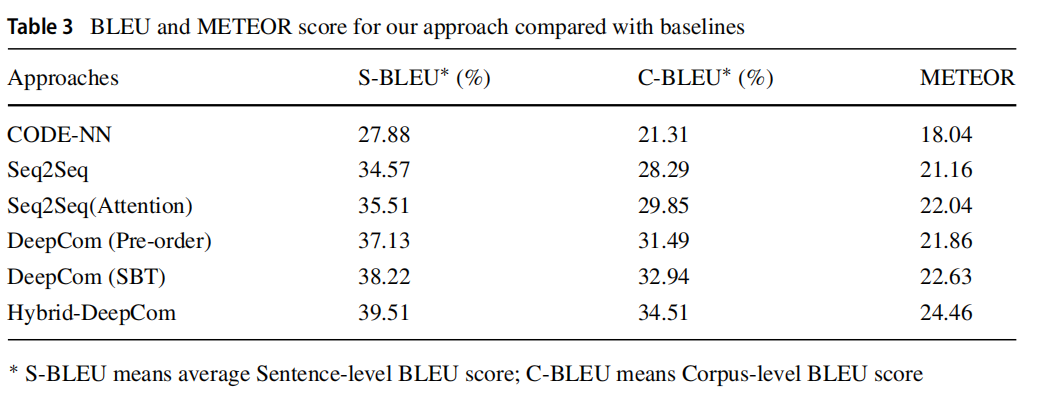
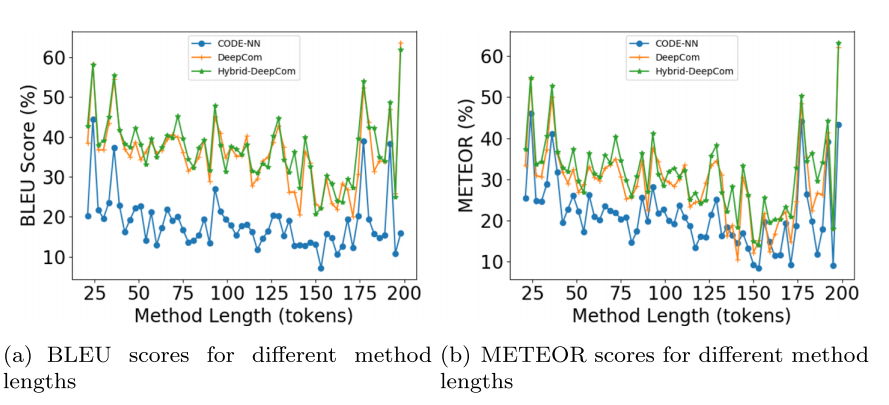
RQ2: What is the impact of source code and comments with different lengths on the performance of Hybrid-DeepCom?
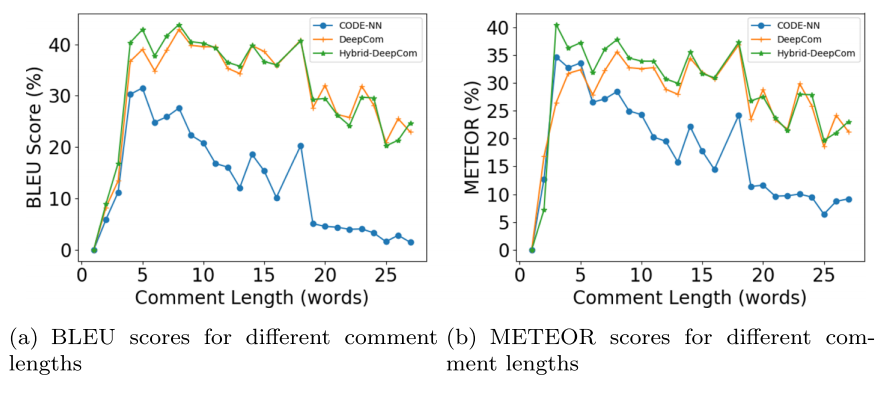
; RQ3: What is the impact of the vocabulary size on the performance of Hybrid-DeepCom?
横轴的比例是out of vocabulary的比例,camel表示将标识符用驼峰分割后的单词被词汇表完全包含。由于deepcom没用驼峰分割(直接用AST节点的type代替没见过的AST节点单词)因此他们没有这一项的计算。

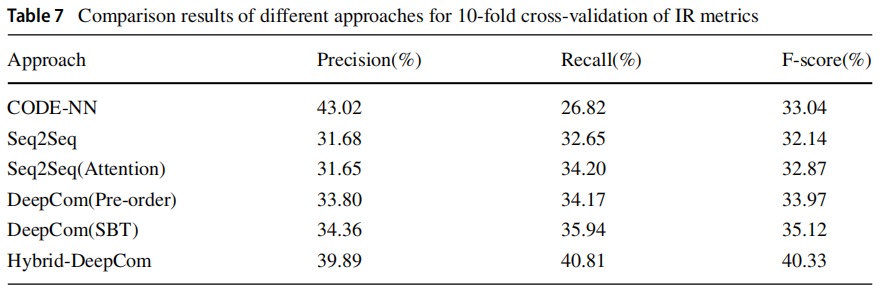
RQ4: How effective is Hybrid-DeepCom to generate comments for new projects?
采用10折交叉验证,最后记录平均结果。

; 四、讨论与结论
主要针对三方面:
(1) when Hybrid-DeepCom generates comments with high BLEU score?
(2) why the automatically generated comments receive low BLEU scores?
(3) why there are unknown words in the generated comments?
这些讨论都挺有意思的,具体可以看原文作者给出的解释。
Hybrid-DeepCom模型是比较简单的,基于基本的seq2seq模型,相对于DeepCom的提升还是可以的,个人认为比较亮眼的就是多个编码器的集合和注意力机制的结合方面,给我们一定的参考,并从特征提取方面思考,融合代码词汇和句法信息。如今transformer盛行,已有研究者相关工作展开了,用更高级的模型也是提升性能的另一种思路。
Original: https://blog.csdn.net/qq_42714262/article/details/121255161
Author: Hilbob
Title: 代码注释生成:《Deep code comment generation with hybrid lexical and syntactical information》论文笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531512/
转载文章受原作者版权保护。转载请注明原作者出处!