

CogLTX: Applying BERT to Long Texts
Ming Ding, Chang Zhou, Hongxia Yang, and Jie Tang. 2020. CogLTX: Applying BERT to Long Texts. InAdvances in Neural Information Processing Systems, Vol. 33.
12792–12804
Abstract
由于二次增加的内存和时间消耗,BERT无法处理长文本。解决这个问题的最自然的方法,如通过滑动窗口分割文本或简化Transformer,都会受到长期关注不足或需要定制CUDA内核。BERT中的最大长度限制提醒我们容量有限(5∼9)人类的工作记忆——那么人类是如何识别长文本的呢?基于Baddeley[2]的认知理论,提出的COGLTX框架通过训练一个学习模型来识别关键句子,将它们连接起来进行推理,并通过排练和衰退实现多步骤推理。由于相关性注释通常不可用,我们建议使用干预来创建监督。作为一种通用算法,CogLTX在各种下游任务上的性能优于SOTA模型,或获得与SOTA模型类似的结果,这些任务的内存开销与文本长度无关。
1 Introduction
由BERT[12]首创的预训练语言模型已成为许多NLP任务的灵丹妙药,如问答[38]和文本分类[22]。研究人员和工程师按照标准的微调范式轻松构建最先进的应用程序,但最终可能会失望地发现一些文本长度超过了BERT的长度限制(通常为512个标记)。这种情况在标准化基准测试中可能很少见,例如SQuAD[38]和GLUE[47],但在更复杂的任务[53]或真实的文本数据中非常常见。
对于长文本,一个简单的解决方案是滑动窗口[50],由BERT处理连续的512个标记跨度。这种方法牺牲了远程标记相互”注意”的可能性,这成为BERT在复杂任务中显示其有效性的瓶颈(例如图1)。 由于问题根源于Transformers[46] 的o (L2)时间和空间复杂性(L是的文本长度),另一种研究试图简化transformers的结构[20,37,8,42],但目前成功应用于BERT的研究很少[35,4]。</p>
<p><img alt="CogLTX Applying BERT to Long Texts" src="https://johngo-pic.oss-cn-beijing.aliyuncs.com/articles/20230526/717019efd80045b3a5aaad4273821a24.png" /></p>
<p>图1:HotpotQA的一个例子(干扰设置,串联)。回答问题的关键句子是第一句和最后一句,彼此之间有512多个标记。在滑动窗口方法中,它们从来不会出现在同一个输入窗口中,因此我们无法回答这个问题。</p>
<p><img alt="CogLTX Applying BERT to Long Texts" src="https://johngo-pic.oss-cn-beijing.aliyuncs.com/articles/20230526/eada1c3cfa2f4634beb908a4074cb85d.png" /></p>
<p>图2:BERT任务主要类型的CogLTX推断。MemRecall是从长文本X中提取关键文本块SZ的过程。塞恩齐斯派了一个名叫"推理者"的BERT去完成这项具体任务。一个(c)任务被转换为多个(b)任务。BERT输入w.r.t.zis用z+表示。</p>
<p>BERT的最大长度限制自然提醒我们,工作记忆[2]的容量有限,这是一个人类认知系统,存储用于逻辑推理和决策的信息。实验[27,9,31]已经表明,工作记忆只能储存5分钟∼阅读过程中的9个项目/单词,那么人类是如何理解长文本的呢?</p>
<p>"中央执行机构——负责协调(多模态)信息的(工作记忆)系统的核心",以及"能够选择和操作控制过程和策略的能力有限的注意力系统的功能",正如巴德利[2]在其1992年的经典著作中指出的那样。后来的研究详细说明,工作记忆中的内容会随着时间的推移而改变[5],除非是通过排练[3]来保存的,即注意并刷新大脑中的信息。然后,通过检索竞争[52],用长期记忆中的相关项目不断更新被忽略的信息,为工作记忆中的推理收集足够的信息。</p>
<p>BERT和工作记忆之间的类比启发我们使用CogLTX框架来识别像人类一样的长文本。CogLTX背后的基本理念相当简洁——通过关键句子的串联进行推理(图2)——而紧凑的设计则需要弥合机器和人类推理过程之间的差距。</p>
<p>CogLTX中的关键步骤是MemRecall,这是一个通过将文本块视为独立记忆来识别相关文本块的过程。MemRecall在检索竞争、排练和衰退方面模仿工作记忆,促进多步骤推理。另一个名为Judge的BERT被引入到块的相关性评分中,并与原始BERT推理器一起进行训练。此外,CogLTX还可以通过干预将面向任务的标签转换为相关注释,以进行培训判断。</p>
<p>我们的实验表明,CogLTX在四项任务上的表现优于或达到了与最先进的结果相当的性能,包括NewsQA[44]、HotpotQA[53]、20NewsGroups[22]和Alibaba,无论文本长度如何,其内存消耗都是恒定的。</p>
<h3><a name="2_background_36">;</a> 2 Background</h3>
<p><strong>长文本的挑战</strong>。对于长文本来说,直接和表面上的障碍是预训练的最大位置嵌入通常是512 在 BERT上[12]。然而,即使提供了更大位置的嵌入,内存消耗也是负担不起的,因为所有激活都存储在训练期间用于反向传播。例如,1500个令牌文本需要大约14个。即使批处理大小为1,6GB内存也会很大,超过普通GPU的容量(例如,RTX 2080ti的容量为11GB)。此外,O(L2)空间复杂度意味着随着文本长度的增加而快速增加。
相关工作。如图1所示,滑动窗口方法缺乏远程关注。以前的工作[49,33]试图通过平均池、最大池或额外的MLP或LSTM来聚合每个窗口的结果;但这些方法在远程交互和需要(512`2·L/512)=O(512L)空间时仍然很弱,实际上,这仍然太大,无法在RTX 2080ti上的2500个令牌文本上训练一个大的BERT,批量大小为1。此外,这些后期聚合方法主要优化分类,而其他任务,例如广度提取、哈维尔BERT输出,需要O(L`2)空间进行自我注意聚合。
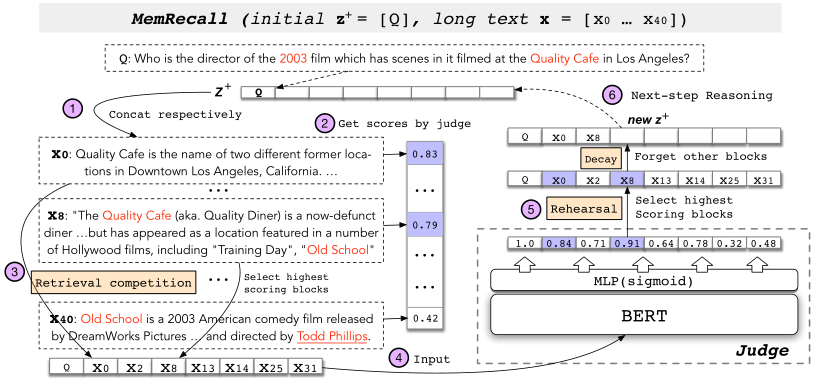

图3:问答的MemRecall示例。长文本轴被分成块[x0…x40]。在第一步中,X0和X8在排练后保留在Z中。x8中的”老派”将有助于在下一步检索答案块x40。详见附录。
在为长文本改编Transformer的研究中,许多研究只是压缩或重复使用前面步骤的结果,不能应用于BERT,例如Transformer XL[8]和Compression Transformer[37]。Reformer使用对位置敏感的哈希来引起基于内容的组注意,但它对GPU不友好,仍然需要验证其使用情况。BlockBERT[35]切断不重要的注意力头,将BERT从512标记放大到1024标记。最近的里程碑Longferer[4]定制了CUDA内核,以支持特殊令牌上的窗口关注和全局关注。然而,由于数据集的大小大多是longformer的4×窗口大小,因此后者的有效性还没有得到充分的研究。”轻量级BERTs”的方向很有希望,但与CogLTX正交,这意味着它们可以结合CogLTX来处理更长的文本,因此本文不再对它们进行比较或讨论。详细调查见[25]
3 Method
3.1 CogLTX 方法论
CogLTX的基本假设是”对于大多数NLP任务,文本存储中的几个关键句子足以满足完成任务所需的信息”。更具体地说,我们假设存在一个由长文本x中的一些句子组成的短文本z,令人满意。
reasoner(x+) ≈ reasoner(z+) , 其中,x+和z+是推理器BERTw.r.t.的输入文本x和z,如图2所示。
我们将每个长文本拆分为块[x0…xT−1] 通过动态规划(见附录),将块长度限制在最大B,在我们的实现中,如果BERT长度限制L=512,则B=63。键短文本z应该由X中的一些块组成,即z=[xz0…xzn−1] ,令人满意的Len(z)≤Landz0
Original: https://blog.csdn.net/qq_45627332/article/details/124064596
Author: 12Struggle
Title: CogLTX Applying BERT to Long Texts
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531500/
转载文章受原作者版权保护。转载请注明原作者出处!