

这部分内容主要研究语言模型及循环神经网络在语言模型中的应用。
目录
4、Recurrent Neural Networks (RNN)
1、 语言模型
语言模型(Language Modelling)研究的是根据已知序列推测下一个单词的问题,即假设已知 ,预测下一个词 的概率 的问题。其中, 可以是词表中的任意单词.这样做的系统称为 Language Model 语言模型。
,预测下一个词 的概率 的问题。其中, 可以是词表中的任意单词.这样做的系统称为 Language Model 语言模型。
根据条件概率的链式法则,我们也可以将其看做一系列词出现的概率问题

语言模型应用广泛,比如手机上打字可以智能预测下一个你要打的词是什么,或者谷歌搜索时自动填充问题等都属于语言模型的应用。语言模型是很多涉及到产生文字或预测文字概率的NLP问题的组成部分,如语音识别、手写文字识别、自动纠错、机器翻译等等。
2、 经典n-gram模型
n-gram模型的定义就是连续的n个单词组成的块。
例如对于 “the students opened their __ “这句话,我们学习一个 n-gram 语言模型。、
- unigrams: “the”, “students”, “opened”, “their”
- bigrams: “the students”, “students opened”, “opened their”
- trigrams: “the students opened”, “students opened their”
- 4-grams: “the students opened their”
该模型的核心思想是n-gram的概率应正比于其出现的频率,并且假设 仅仅依赖于它之前的n-1个单词,即

其中count是通过处理大量文本对相应的n-gram出现次数计数得到的。
具体含义如下图所示

- 如何得到n-gram和(n-1)-gram的概率?通过在一些大型文本语料库中计算它们(统计近似)
N-gram模型主要有两大问题:
- 稀疏问题 Sparsity Problem。随着n的增大,稀疏性更严重。
- 我们必须存储所有的n-gram对应的计数,随着n的增大,模型存储量也会增大。
这些限制了n的大小,但如果n过小,则我们无法体现稍微远一些的词语对当前词语的影响,这会极大的限制处理语言问题中很多需要依赖相对长程的上文来推测当前单词的任务的能力。
3、 Window-based DNN
Bengio et al提出了第一个大规模深度学习自然语言处理模型,只不过是用前 n 个单词的词向量来做同样的事情(上文建模)而已,其网络结构如下:

图中的softmax函数可以写成:(注意式子中各个权重矩阵的训练对象)

一个自然的将神经网络应用到语言模型中的思路是 window-based DNN,即将定长窗口中的word embedding连在一起,将其经过神经网络做对下一个单词的分类预测,其类的个数为语裤中的词汇量.如下图所示:

A fixed-window neural Language Model

使用和NER问题中同样网络结构

与n-gram模型相比较,DNN解决了稀疏问题与存储问题,不需要观察到所有的 n-grams。但它仍然存在一些问题:窗口大小固定,扩大窗口会使矩阵 变大,且 与 W 的不同列相乘,输入的处理 不对称,没有任何可共享的参数。
我们需要一个神经结构,可以处理任何长度的输入.
4、Recurrent Neural Networks (RNN)
4.1 RNN介绍
RNN结构通过不断的应用同一个矩阵W可实现参数的有效共享,并且没有固定窗口的限制。其核心想法:重复使用 相同 的权重矩阵 W。
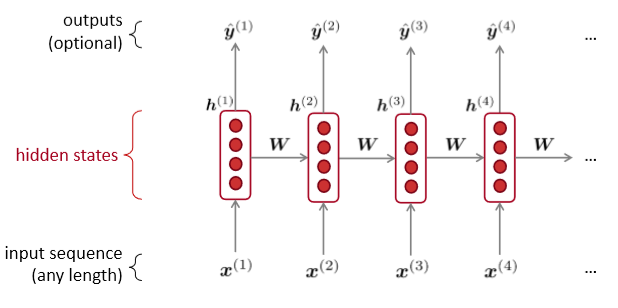
传统的翻译模型只能以有限窗口大小的前 n 个单词作为条件进行语言模型建模,循环神经网络与其不同,RNN 有能力以语料库中所有前面的单词为条件进行语言模型建模。下图展示的 RNN 的架构,其中矩形框是在一个时间步的一个隐藏层 t。
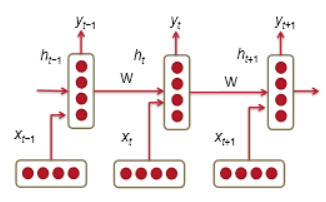
其中每个这样的隐藏层都有若干个神经元,每个神经元对输入向量用一个线性矩阵运算然后通过非线性变化(例如 tanh 函数)得到输出。在每一个时间步,隐藏层都有两个输入:前一个时间步的隐藏层
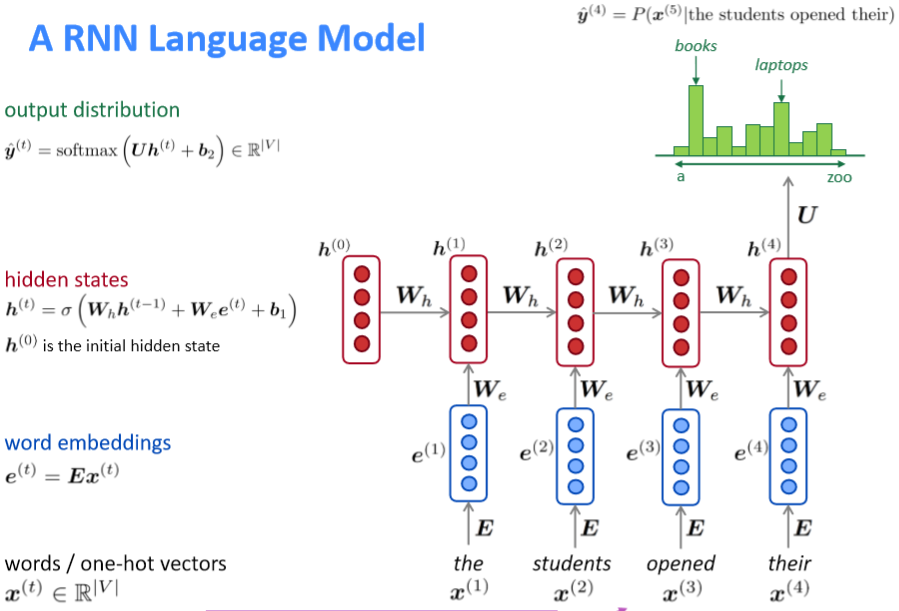
和当前时间步的输入 ,前一个时间步的隐藏层 通过和权重矩阵 相乘和当前时间步的输入 和权重矩阵 相乘得到当前时间步的隐藏层 ,然后再将 和权重矩阵 相乘,接着对整个词表通过 softmax 计算得到下一个单词的预测结果 ,如下面公式所示:

每个神经元的输入和输出如下图所示:


在每一个时间步使用相同的权重
以下是网络中每个参数相关的详细信息:
- :含有 T 个单词的语料库对应的词向量。

- ∈ :在时间步 t 的输入词向量。



- σ:非线性函数(这里是 sigmoid 函数)。

RNN的优点:
- 可以处理任意长度的输入序列
对于较长的输入序列长度,模型大小不会增加
- 步骤t的计算(理论上)可以使用来自多个步骤的信息。
- 对输入的每个时间步都应用相同的权重,因此在处理输入时具有对称性
RNN的缺点:
- 计算很慢——因为它是顺序的,所以不能并行化
- 在实践中,由于渐变消失和爆炸等问题,很难从许多步骤返回信息
4.2 RNN Loss and Perplexity
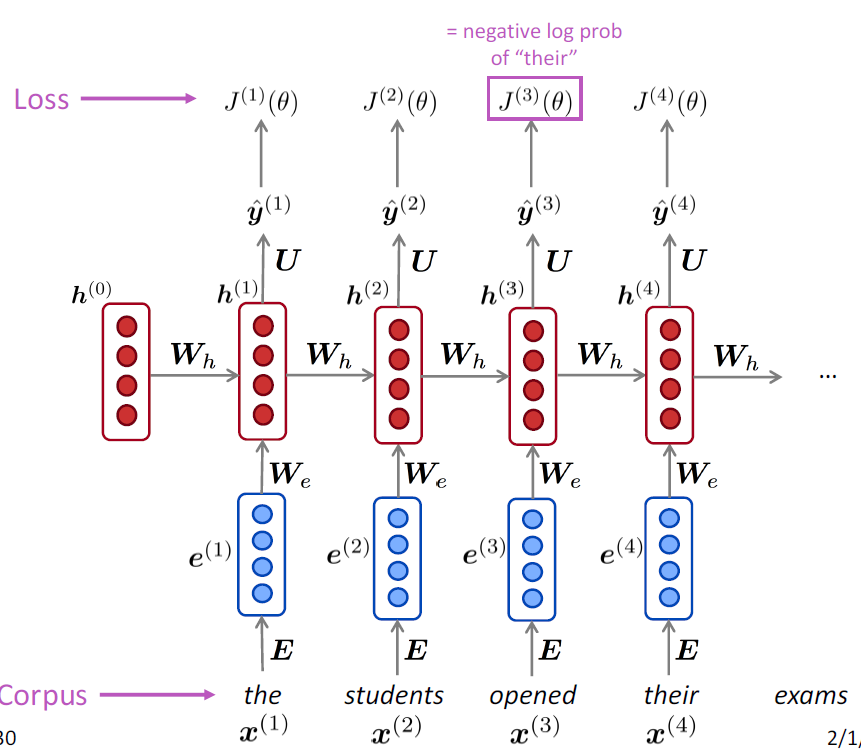
RNN 的损失函数一般是交叉上误差。

在大小为 T 的语料库上的交叉熵误差的计算如下:

语言模型的评估指标是perplexity,即我们文本库的概率的倒数,也可以表示为损失函数的指数形式,所以perplexity越小表示我们的语言模型越好。


如果以2为底数会得到”perplexity困惑度”,代表模型下结论时的困惑程度,越小越好:





4.3 梯度消失
句子1:”Jane walked into the room. John walked in too. Jane said hi to ___”
句子2:”Jane walked into the room. John walked in too. It was late in the day, and everyone was walking home after a long day at work. Jane said hi to ___”
我们可以轻松地在两个空中填入”John”这个答案,但RNN却很难做对第二个。这是因为在前向传播的时候,前面的x反复乘上W,导致对后面的影响很小。反向传播时也是如此。整个序列的预测误差是之前每个时刻的误差之和:

而每个时刻 t 的误差又是之前每个时刻的误差之和,应用链式法则:

此处的
指的是在[k,t]时间区域上应用链式法则:

由于h∈
,每个 就是h的雅克比矩阵(导数矩阵):

将这几个式子写在一起,得到:

这个式子最中间的部分最值得关注,因为它是一个连乘的形式,长度为时间区域的长度。记
和 分别为矩阵和向量的范数(L2),则上述雅克比矩阵的范数满足:

由于使用了sigmoid激活函数,所以
的矩阵范数最大只能为1,所以链式法则利用上式t−k次后得到一个更松弛的上界:
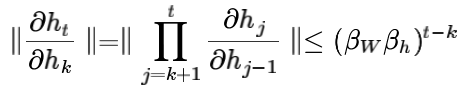
指数项 显著地大于或小于1的时候,经过足够多的t−k次乘法之后就会趋近于0或无穷大。小于1更常见,会导致很长时间之前的词语无法影响对当前词语的预测。而大于1时,浮点数运算会产生溢出(NaN),一般可以很快发现。这叫做梯度爆炸。小于1,或者下溢出并不产生异常,难以发现,但会显著降低模型对较远单词的记忆效果,这叫做梯度消失。
import numpy as np
import matplotlib.pyplot as plt
#sigmoid函数
def sigmoid(x):
x=1/(1+np.exp(-x))
return x
#sigmoid导函数
def sigmoid_grad(x):
return x*(1-x)
#Relu激活函数
def relu(x):
return np.maximum(0,x)
def three_layer_net(NONLINEARITY,X,y,model,step_size,reg):
#参数初始化
h=model['h']
h2=model['h2']
W1=model['W1']
W2 = model['W2']
W3 = model['W3']
b1=model['b1']
b2 = model['b2']
b3 = model['b3']
num_examples=X.shape[0]
plot_array_1=[]
plot_array_2=[]
for i in range(50000):
#前向传播
if NONLINEARITY=='RELU':
hidden_layer=relu(np.dot(X,W1)+b1)
hidden_layer2=relu(np.dot(hidden_layer,W2)+b2)
scores=np.dot(hidden_layer2,W3)+b3
elif NONLINEARITY == 'SIGM':
hidden_layer = sigmoid(np.dot(X, W1) + b1)
hidden_layer2 = sigmoid(np.dot(hidden_layer, W2) + b2)
scores = np.dot(hidden_layer2, W3) + b3
exp_scores=np.exp(scores)
probs=exp_scores/np.sum(exp_scores,axis=1,keepdims=True)#softmax概率化得分[N*K]
#计算损失
correct_logprobs=-np.log(probs[range(num_examples),y])#整体的交叉熵损失
data_loss=np.sum(correct_logprobs)/num_examples #平均交叉熵损失
reg_loss=0.5*reg*np.sum(W1*W1)+0.5*reg*np.sum(W2*W2)+0.5*reg*np.sum(W3*W3)#正则化损失,W1*W1表示哈达玛积
loss=data_loss+reg_loss
if i%1000==0:
print("iteration %d: loss %f"%(i,loss))
#计算scores的梯度
dscores=probs
dscores[range(num_examples),y]-=1 #此处为交叉熵损失函数的求导结果,详细过程请看:https://blog.csdn.net/qian99/article/details/78046329
dscores/=num_examples
#反向传播过程
dW3=(hidden_layer2.T).dot(dscores)
db3=np.sum(dscores,axis=0,keepdims=True)
if NONLINEARITY == 'RELU':
# 采用RELU激活函数的反向传播过程
dhidden2 = np.dot(dscores, W3.T)
dhidden2[hidden_layer2 <= 0 1 2 0]="0" dw2="np.dot(hidden_layer.T," dhidden2) plot_array_2.append(np.sum(np.abs(dw2)) np.sum(np.abs(dw2.shape))) db2="np.sum(dhidden2," axis="0)" dhidden="np.dot(dhidden2," w2.t) dhidden[hidden_layer <="0]" = elif nonlinearity="=" 'sigm': # 采用sigm激活函数的反向传播过程 dhidden2="dscores.dot(W3.T)" * sigmoid_grad(hidden_layer2) sigmoid_grad(hidden_layer) dw1="np.dot(X.T," dhidden) plot_array_1.append(np.sum(np.abs(dw1)) np.sum(np.abs(dw1.shape)))#第一层的平均梯度记录下来 db1="np.sum(dhidden," 加入正则化得到的梯度 dw3 +="reg" w3 w2 w1 记录梯度 grads="{}" grads['w1']="dW1" grads['w2']="dW2" grads['w3']="dW3" grads['b1']="db1" grads['b2']="db2" grads['b3']="db3" 更新梯度 b1 b2 b3 db3 评估模型的准确度 if 'relu': hidden_layer="relu(np.dot(X," w1) b1) hidden_layer2="relu(np.dot(hidden_layer," w2) b2) scores="np.dot(hidden_layer2," w3) predicted_class="np.argmax(scores," print('training accuracy: %.2f' % (np.mean(predicted_class="=" y))) 返回梯度和参数 return plot_array_1, plot_array_2, w1, w2, w3, b1, b2, __name__="='__main__':" plt.rcparams['figure.figsize']="(10.0,8.0)#设置画布的默认大小" plt.rcparams['image.interpolation']="nearest" #设置插值的风格 plt.rcparams['image.cmap']="gray" #设置画布的颜色 np.random.seed(0)#保证后面seed(0)生成的随机数相同 n="100" #每一个类别的数量 d="2" #维度 k="3" #类别数 h="50" h2="50" x="np.zeros((N*K,D))" num_train_examples="X.shape[0]" y="np.zeros(N*K,dtype='uint8')" for j in range(k): ix="range(N*j,N*(j+1))" r="np.linspace(0.0,1,N)" 半径 t="np.linspace(j*4,(j+1)*4,N)+np.random.randn(N)*0.2" theta x[ix]="np.c_[r*np.sin(t),r*np.cos(t)]#" 按行拼接两个矩阵 y[ix]="j" fig="plt.figure()" plt.scatter(x[:,0],x[:,1],c="y,s=40,cmap=plt.cm.Spectral)#画点,c代表颜色,s代表点的大小" plt.xlim([-1,1])#设置横坐标的范围大小 plt.ylim([-1,1])#设置纵坐标的范围大小 plt.show() #初始化模型参数 model="{}" model['h']="h" hidden layer 大小 model['h2']="h2#" model['w1']="0.1" np.random.randn(d,h) model['b1']="np.zeros((1,h))" model['w2']="0.1" np.random.randn(h,h2) model['b2']="np.zeros((1,h2))" model['w3']="0.1" np.random.randn(h2,k) model['b3']="np.zeros((1,K))" activation_function="RELU" #选择激活函数 sigm relu (plot_array_1, b3)="three_layer_net(Activation_Function," x, y, model,step_size="1e-1," reg="1e-3)" #模型采用两种激活函数时,分别画出模型梯度的变化趋势 plt.plot(np.array(plot_array_1)) plt.plot(np.array(plot_array_2)) plt.title('sum of magnitudes gradients -- neurons') plt.legend((activation_function+" first layer", activation_function+" second layer")) code></=>
代码来自博客:【CS224n】笔记8 RNN和语言模型_20%橙小鱼的博客-CSDN博客
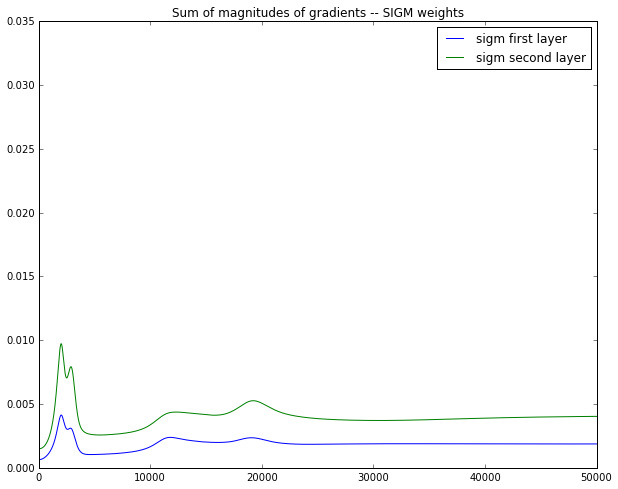
演示梯度消失,对于如下数据:

学习非线性的决策边界:

用经典的三层网络结构,得到蓝色的第一层梯度的长度和绿色的第二层梯度的长度,可视化:
sigmoid激活函数下:
ReLU激活函数下:

在这个例子的反向传播中,相邻两层梯度是近乎减半地减小。
4.4 梯度爆炸
与梯度消失类似,由于存在矩阵W的指数项,如果其本征值大于1,则随着时间越远该梯度指数级增大,这又造成了另一问题exploding gradient梯度爆炸,这就会造成当我们步进更新时,步进过大而越过了极值点,一个简单的解决方案是gradient clipping,即如果梯度大于某一阈值,则在SGD新一步更新时按比例缩小梯度值,即我们仍然向梯度下降的方向行进但是其步长缩小,其伪代码如下:

不进行clipping与进行clipping的学习过程对比如下

可见左图中由于没有进行clipping,步进长度过大,导致损失函数更新到一个不理想的区域,而右图中进行clipping后每次步进减小,能更有效的达到极值点区域。
梯度爆炸问题我们可以通过简单的gradient clipping来解决,那对于梯度消失问题呢?其基本思路是我们设置一些存储单元来更有效的进行长程信息的存储,LSTM与GRU都是基于此基本思想设计的( 详见6 LSTM与GRU)。
4.5 防止梯度爆炸
一种暴力的方法是,当梯度的长度大于某个阈值的时候,将其缩放到某个阈值。虽然在数学上非常丑陋,但实践效果挺好。
其直观解释是,在一个只有一个隐藏节点的网络中,损失函数和权值w偏置b构成error surface,其中有一堵墙:

每次迭代梯度本来是正常的,一次一小步,但遇到这堵墙之后突然梯度爆炸到非常大,可能指向一个莫名其妙的地方(实线长箭头)。但缩放之后,能够把这种误导控制在可接受的范围内(虚线短箭头)。
但这种trick无法推广到梯度消失,因为你不想设置一个最低值硬性规定之前的单词都相同重要地影响当前单词。
5、序列模型的应用
可以把每个词分类到NER、实体级别的情感分析(饭菜味道不错,但环境不太卫生)、意见表达。
其中,意见挖掘任务就是将每个词语归类为:
- DSE:直接主观描述(明确表达观点等)
- ESE:间接主观描述(间接地表达情感等)
语料标注采用经典的BIO标注:

实现这个任务的朴素网络结构就是一个裸的RNN:

但是这个网络无法利用当前词语的下文辅助分类决策,解决方法是使用一些更复杂的RNN变种。
Bidirectional RNNs

上图为双向RNN网络结构。
双向深度神经网络在每个时间步t,有两个隐藏层,一个用于从左到右传播,另一个用于从右到左传播。为了保留两个隐藏层,网络的权值和偏置参数消耗的内存空间是原来的两倍。最终结合两个方向RNN隐藏层的结果生成最终的分类结果。
建立双向RNN隐层及预测的数学公式如下

Deep Bidirectional RNNs
理解了上图之后,再加几个层,每个时刻不但接受上个时刻的特征向量,还接受来自下层的特征表示:

6、 LSTM与GRU
6.1 LSTM
LSTM, 全称Long Short Term Memory。其基本思路是除了hidden state _t
之外,引入cell state 来存储长程信息,LSTM可以通过控制gate来擦除,存储或写入cell state。
LSTM的公式如下:
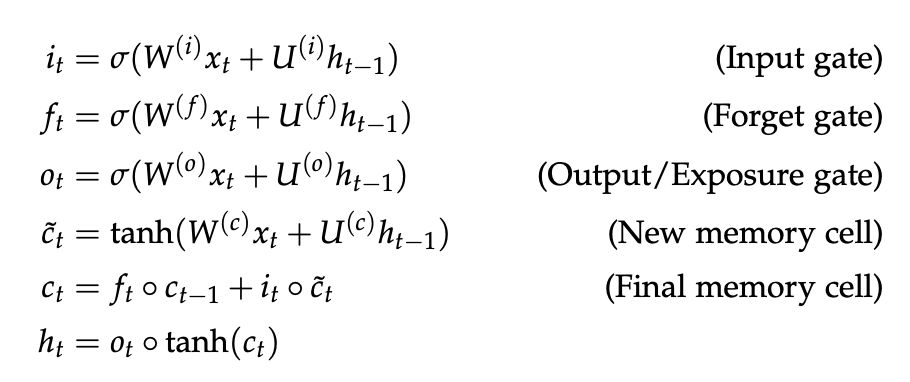
New Memory cell
通过将新的输入 与代表之前的context的hidden state 结合生成新的memory。
Input gate
决定了新的信息是否有保留的价值。
Forget gate
决定了之前的cell state有多少保留的价值。
Final memory cell
通过将forget gate与前memory cell作元素积得到了前memory cell需要传递下去的信息,并与input gate和新的memory cell的元素积求和。极端情况是forget gate值为1,则之前的memory cell的全部信息都会传递下去,使得梯度消失问题不复存在。
output gate
决定了memory cell 中有多少信息需要保存在hidden state中。
6.2 GRU
GRU(gated recurrent unit)可以看做是将LSTM中的forget gate和input gate合并成了一个update gate,即下式中的
,同时将cell state也合并到hidden state中。

Update Gate决定了前一时刻的hidden state有多少可以保留到下一时刻的hidden state。reset gate决定了在产生新的memory
时前一时刻hidden state有多少贡献。
虽然还存在RNN的很多其他变种,但是LSTM与RNN是最广泛应用的。最大的区别就是GRU有更少的参数,更便于计算,对于模型效果方面,两者类似。通常我们可以从LSTM开始,如果需要提升效率的话再准换成GRU。
6.3 延伸
梯度消失仅仅局限于RNN结构吗?实际上对于深度神经网络,尤其层数较多时,由于链式法则以及非线性函数的选择,梯度消失问题也会出现,导致底层的layer学习速度很慢,只不过由于RNN中由于不断的乘以相同的权重矩阵导致其梯度消失问题更显著。
对于非RNN的深度神经网络如前馈神经网络与卷积神经网络,为了解决梯度消失问题,通常可以引入更直接的联结使得梯度更容易传递。
例如在ResNet中,通过引入与前层输入一样的联结使得信息更有效的流动,这使得我们可以能够训练更深层的模型。这一联结被称作Residual Connection或Skip Connection。

更进一步的,在DenseNet中,我们可以将几层之间全部建立直接联结,形成dense connection。

Original: https://blog.csdn.net/qq_38587650/article/details/123893336
Author: 已退游,勿扰
Title: 【2019斯坦福CS224N笔记】(5)The probability of a sentence Recurrent Neural Networks and Language Models
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531494/
转载文章受原作者版权保护。转载请注明原作者出处!