

任务三:基于注意力机制的文本匹配
输入两个句子判断,判断它们之间的关系。参考ESIM(可以只用LSTM,忽略Tree-LSTM),用双向的注意力机制实现。
- 参考
- 《神经网络与深度学习》 第7章
- Reasoning about Entailment with Neural Attention https://arxiv.org/pdf/1509.06664v1.pdf
- Enhanced LSTM for Natural Language Inference https://arxiv.org/pdf/1609.06038v3.pdf
- 数据集:https://nlp.stanford.edu/projects/snli/
- 实现要求:Pytorch
- 知识点:
- 注意力机制
- token2token attetnion
- 时间:两周
任务三和四相当于让我们复现论文,这个过程多少有点艰难(万事开头难)
经历了八个小时的debug之后终于跑通了整个代码…
但是跑通那一刻真的很快乐哈哈哈,虽然不知道效果怎么样
总之训练速度特别慢,1660ti属实顶不住几十万的数据量
话不多说,直接开始分析ESIM
0x0 Hybrid Neural Inference Models
We present here our natural language inference networks which are composed of the following major components: input encoding, local inference modeling, and inference composition.
整个ESIM模型的 结构图:
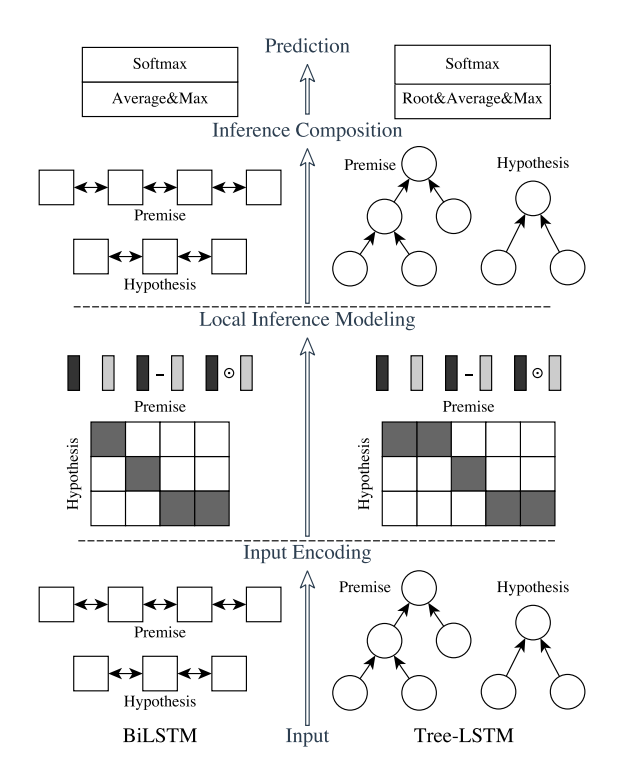

; 0x1 Input Encoding
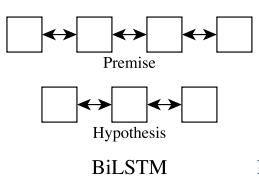
首先使用 双向LSTM来 encode我们的 premise和 hypothesis
Here BiLSTM learns to representa word (e.g., ai) and its context.
经过BiLSTM的编码之后得到 a_bar和 b_bar
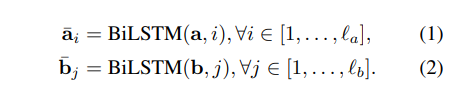
BiLSTM
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size=128, dropout_rate=0.1, layer_num=1):
super(BiLSTM, self).__init__()
self.hidden_size = hidden_size
if layer_num == 1:
self.bilstm = nn.LSTM(input_size, hidden_size // 2, layer_num, batch_first=True, bidirectional=True)
else:
self.bilstm = nn.LSTM(input_size, hidden_size // 2, layer_num, batch_first=True, dropout=dropout_rate,
bidirectional=True)
self.init_weights()
def init_weights(self):
for p in self.bilstm.parameters():
if p.dim() > 1:
nn.init.normal_(p)
p.data.mul_(0.01)
else:
p.data.zero_()
p.data[self.hidden_size // 2: self.hidden_size] = 1
def forward(self, x, lens):
'''
:param x: (batch, seq_len, input_size)
:param lens: (batch, )
:return: (batch, seq_len, hidden_size)
'''
ordered_lens, index = lens.sort(descending=True)
ordered_x = x[index]
packed_x = nn.utils.rnn.pack_padded_sequence(ordered_x, ordered_lens.cpu(), batch_first=True)
packed_output, _ = self.bilstm(packed_x)
output, _ = nn.utils.rnn.pad_packed_sequence(packed_output, batch_first=True)
recover_index = index.argsort()
recover_output = output[recover_index]
return recover_output
Input_Encoding
class Input_Encoding(nn.Module):
def __init__(self, num_features, hidden_size, embedding_size, vectors,
num_layers=1, batch_first=True, drop_out=0.5):
super(Input_Encoding, self).__init__()
self.num_features = num_features
self.num_hidden = hidden_size
self.embedding_size = embedding_size
self.num_layers = num_layers
self.dropout = nn.Dropout(drop_out)
self.embedding = nn.Embedding.from_pretrained(vectors).cuda()
self.bilstm = BiLSTM(embedding_size, hidden_size, drop_out, num_layers)
def forward(self, x, lens):
x = self.embedding(x)
x = self.dropout(x)
x = self.bilstm(x, lens)
return x
0x2 Local Inference Modeling
Modeling local inference needs to employ some forms of hard or soft alignment to associate the relevant subcomponents between a premise and a hypothesis. This includes early methods motivated from the alignment in conventional automatic machine translation (MacCartney, 2009).In neural network models, this is often achieved with soft attention.
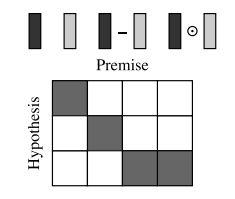
; Locality of inference
接下来用软性注意力机制,使用点积模型:
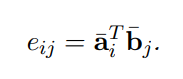
Local inference collected over sequences
众所周知,注意力机制其实就是一个加权表示
对局句子a和句子b,每一个token做attention,e这个矩阵,e i j e_{ij}e i j 代表a的第i个token和b的第j个token之间的点积
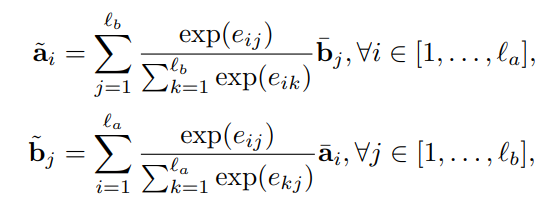

; Enhancement of local inference information
In our models, we further enhance the local inference information collected. We compute the
difference and the element-wise product for the tuple
使用一个玄学拼接
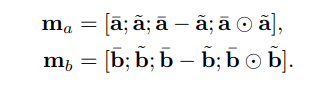
Local_Inference_Modeling
class Local_Inference_Modeling(nn.Module):
def __init__(self):
super(Local_Inference_Modeling, self).__init__()
self.softmax_1 = nn.Softmax(dim=1).to(device)
self.softmax_2 = nn.Softmax(dim=2).to(device)
def forward(self, a_, b_):
'''
:param a_: (batch, seq_len_A, hidden_size)
:param b_: (batch, seq_len_B, hidden_size)
:return: (batch, seq_len_A, hidden_size * 4), (batch, seq_len_B, hidden_size * 4)
'''
e = torch.matmul(a_, b_.transpose(1, 2)).to(device)
a_tilde = (self.softmax_2(e)).bmm(b_)
b_tilde = (self.softmax_1(e).transpose(1, 2)).bmm(a_)
m_a = torch.cat([a_, a_tilde, a_ - a_tilde, a_ * a_tilde], dim=-1)
m_b = torch.cat([b_, b_tilde, b_ - b_tilde, b_ * b_tilde], dim=-1)
return m_a, m_b
0x3 Inference Composition
To determine the overall inference relationship between a premise and hypothesis, we explore a composition layer to compose the enhanced local inference information ma and mb. We perform the
composition sequentially or in its parse context
using BiLSTM and tree-LSTM, respectively.
; The composition layer
跟第一部分一样的编码方式:
v a , i = B i L S T M ( m a , i ) , ∀ i ∈ [ 1 , . . . , l a ] {v_a,i} = BiLSTM(m_a,i),\forall i\in[1,…,l_a]v a ,i =B i L S T M (m a ,i ),∀i ∈[1 ,…,l a ]
v b , i = B i L S T M ( m b , j ) , ∀ j ∈ [ 1 , . . . , l b ] {v_b,i} = BiLSTM(m_b,j),\forall j\in[1,…,l_b]v b ,i =B i L S T M (m b ,j ),∀j ∈[1 ,…,l b ]
然后:
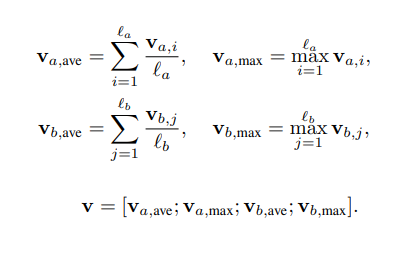
class Inference_Composition(nn.Module):
def __init__(self, num_features, m_size, hidden_size, num_layers, embedding_size, batch_first=True, drop_out=0.5):
super(Inference_Composition,self).__init__()
self.linear = nn.Linear(4 * hidden_size, hidden_size).to(device)
self.bilstm = BiLSTM(hidden_size, hidden_size, drop_out, num_layers).to(device)
self.drop_out = nn.Dropout(drop_out).to(device)
def forward(self, x, lens):
"""
:param x: (batch, seq_len, hidden_size * 4)
:param lens: (seq_len, )
:return: (batch, seq_len, hidden_size)
"""
x = self.linear(x)
x = self.drop_out(x)
x = self.bilstm(x, lens)
return x
0x4 Final Prediction
We then put v into a final multilayer perceptron (MLP) classifier. The MLP has a hidden layer with
tanh activation and softmax output layer in our experiments. The entire model (all three components
described above) is trained end-to-end. For training, we use multi-class cross-entropy loss.

这一部分没写公式,就是一个双层的全连接:
这里的pooling就是将每个token的hidden_size压缩到1,即每个token此时只有一个特征
class Prediction(nn.Module):
def __init__(self, v_size, mid_size, num_classes=4, drop_out=0.5):
super(Prediction, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(v_size, mid_size), nn.Tanh(),
nn.Linear(mid_size, num_classes)
).to(device)
def forward(self, a, b):
"""
:param a: (batch, seq_len_A, hidden_size)
:param b: (batch, seq_len_B, hidden_size)
:return: (batch, num_classes)
"""
v_a_avg = F.avg_pool1d(a, a.size(2)).squeeze(-1)
v_a_max = F.max_pool1d(a, a.size(2)).squeeze(-1)
v_b_avg = F.avg_pool1d(b, b.size(2)).squeeze(-1)
v_b_max = F.max_pool1d(b, b.size(2)).squeeze(-1)
out_put = torch.cat((v_a_avg, v_a_max, v_b_avg, v_b_max), dim=-1)
return self.mlp(out_put)
0x5 Overall inference models
Our model can be based only on the sequential networks by removing all tree components and we call it Enhanced Sequential Inference Model (ESIM) (see the left part of Figure 1). We will show that ESIM outperforms all previous results. We will also encode parse information with tree LSTMs in multiple layers as described (see the right side of Figure 1). We train this model and incorporate it into ESIM by averaging the predicted probabilities to get the final label for a premise-hypothesis pair. We will show that parsing information complements very well with ESIM and further improves the performance, and we call the final model Hybrid Inference Model(HIM).
class ESIM(nn.Module):
def __init__(self, num_features, hidden_size, embedding_size, num_classes=4, vectors=None,
num_layers=1, batch_first=True, drop_out=0.5, freeze=False):
super(ESIM, self).__init__()
self.embedding_size = embedding_size
self.input_encoding = Input_Encoding(num_features, hidden_size, embedding_size, vectors,
num_layers=1, batch_first=True, drop_out=0.5)
self.local_inference = Local_Inference_Modeling()
self.inference_composition = Inference_Composition(num_features, 4 * hidden_size, hidden_size,
num_layers, embedding_size=embedding_size,
batch_first=True, drop_out=0.5)
self.prediction = Prediction(4 * hidden_size, hidden_size, num_classes, drop_out)
def forward(self, a, len_a, b, len_b):
a_bar = self.input_encoding(a, len_a)
b_bar = self.input_encoding(b, len_b)
m_a, m_b = self.local_inference(a_bar, b_bar)
v_a = self.inference_composition(m_a, len_a)
v_b = self.inference_composition(m_b, len_b)
out_put = self.prediction(v_a, v_b)
return out_put
0x6 Experimental Setup
Data
from torchtext.legacy.data import Iterator, BucketIterator
from torchtext.legacy import data
import torch
def data_loader(batch_size=32, device="cuda", data_path='data', vectors=None):
TEXT = data.Field(batch_first=True, include_lengths=True, lower=True)
LABEL = data.LabelField(batch_first=True)
TREE = None
fields = {'sentence1': ('premise', TEXT),
'sentence2': ('hypothesis', TEXT),
'gold_label': ('label', LABEL)}
train_data, dev_data, test_data = data.TabularDataset.splits(
path = data_path,
train='snli_1.0_train.jsonl',
validation='snli_1.0_dev.jsonl',
test='snli_1.0_test.jsonl',
format ='json',
fields = fields,
filter_pred=lambda ex: ex.label != '-'
)
TEXT.build_vocab(train_data, vectors=vectors, unk_init=torch.Tensor.normal_)
LABEL.build_vocab(dev_data)
train_iter, dev_iter = BucketIterator.splits(
(train_data, dev_data),
batch_sizes=(batch_size, batch_size),
device=device,
sort_key=lambda x: len(x.premise) + len(x.hypothesis),
sort_within_batch=True,
repeat=False,
shuffle=True
)
test_iter = Iterator(
test_data,
batch_size=batch_size,
device=device,
sort=False,
sort_within_batch=False,
repeat=False,
shuffle=False
)
return train_iter, dev_iter, test_iter, TEXT, LABEL
Training
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.vocab import Vectors
from models import ESIM
from tqdm import tqdm
from utils import data_loader
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
batch_size = 36
hidden_size = 600
epochs = 10
drop_out = 0.5
num_layers = 1
learning_rate = 4e-4
patience = 5
clip = 10
embedding_size = 300
device = 'cuda'
vectors = Vectors('glove.6B.300d.txt', 'C:/Users/Mechrevo/Desktop/nlp-beginner/embedding')
data_path = 'data'
def train(train_iter, dev_iter, loss_func, optimizer, epochs, patience=5, clip=5):
for epoch in range(epochs):
model.train()
total_loss = 0
n = 0
train_correct = 0
train_error = 0
for batch in tqdm(train_iter):
premise, premise_lens = batch.premise
hypothesis, hypothesis_lens = batch.hypothesis
labels = batch.label
model.zero_grad()
output = model(premise, premise_lens, hypothesis, hypothesis_lens).to(device)
loss = loss_func(output, labels)
train_correct += (output.argmax(1) == labels).sum().item()
train_error += (output.argmax(1) != labels).sum().item()
total_loss += loss.item()
n += batch_size
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
if n % 3600 == 0:
print('epoch : {} step : {}, loss : {}, acc : {}'.format(epoch + 1, int(n / 3600), total_loss/n,
train_correct/(train_error+train_correct)))
tqdm.write("Epoch: {}, Train Average Loss: {}, Train Acc: {}" .format(epoch + 1, total_loss/n,
train_correct/(train_error+train_correct)))
model.eval()
with torch.no_grad():
n2 = 0
val_total_loss = 0
dev_correct = 0
dev_error = 0
for batch in tqdm(dev_iter):
premise, premise_lens = batch.premise
hypothesis, hypothesis_lens = batch.hypothesis
labels = batch.label
output = model(premise, premise_lens, hypothesis, hypothesis_lens).to(device)
loss = loss_func(output, labels)
dev_correct += (output.argmax(1) == labels).sum().item()
dev_error += (output.argmax(1) != labels).sum().item()
val_total_loss += loss
n2 += batch_size
tqdm.write("Epoch: {}, Validation Average Loss: {}, Validation Acc: {}".format(epoch + 1, val_total_loss/n2,
dev_correct/(dev_error+dev_correct)))
def test(test_iter, loss_func):
model.eval()
with torch.no_grad():
n = 0
test_total_loss = 0
test_correct = 0
test_error = 0
for batch in tqdm(test_iter):
premise, premise_lens = batch.premise
hypothesis, hypothesis_lens = batch.hypothesis
labels = batch.label
output = model(premise, premise_lens, hypothesis, hypothesis_lens).to(device)
loss = loss_func(output, labels)
test_correct += (output.argmax(1) == labels).sum().item()
test_error += (output.argmax(1) != labels).sum().item()
test_total_loss += loss
n += batch_size
print('Test Acc: {}, loss : {}'.format(test_correct/(test_error+test_correct), test_total_loss/n))
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
train_iter, dev_iter, test_iter, TEXT, LABEL = data_loader(batch_size, device, data_path, vectors)
model = ESIM(num_features=(TEXT.vocab), hidden_size=hidden_size, embedding_size=embedding_size,
num_classes=4, vectors=TEXT.vocab.vectors, num_layers=num_layers,
batch_first=True, drop_out=0.5, freeze=False).to(device)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_func = nn.CrossEntropyLoss()
train(train_iter, dev_iter, loss_func, optimizer, epochs, patience, clip)
test(test_iter, loss_func)
Original: https://blog.csdn.net/Raki_J/article/details/122075646
Author: 爱睡觉的Raki
Title: 复旦nlp实验室 nlp-beginner 任务三:基于注意力机制的文本匹配
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531482/
转载文章受原作者版权保护。转载请注明原作者出处!