

目录
transformer中的mask有两种作用:
其一:去除掉各种padding在训练过程中的影响。
其二,将输入进行遮盖,避免decoder看到后面要预测的东西。(只用在decoder中)
1.Encoder中的mask 的作用属于第一种
在encoder中,输入的是一batch的句子,为了进行batch训练,句子结尾进行了padding(P)。在输入encoder中训练的过程中,先进性多头自注意计算。在这个过程中 1)进行(q*K^T)/d_model^1/2. 2)然后要对得到的权重矩阵进行mask 3)再将结果进行softmax,去除掉不必要padding的影响 4)然后才和V矩阵相乘。
Encoder中的mask矩阵获取
def get_attn_pad_mask(enc_inputs, enc_inputs): ### 用来生产三个注意矩阵
# print(seq_q) ### encoder_inputs (是叠加了位置编码之后的embedding)
batch_size, len_q = seq_q.size() ### [1,5] seq_q: [batch_size,sen_len]
batch_size, len_k = seq_k.size() # eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k ###expand()函数,将tensor变形为括号内的维度。expand到的维度 将第一行的数据重复就行了
得到的mask矩阵如下
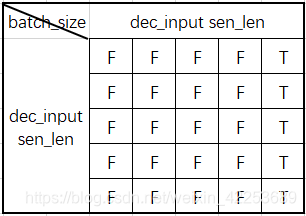

多头自注意计算
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores) ### 这里attn_mask每一行的末尾是补充的padding(P),由eq(0)函数判断输出是True,.为了不让填充对结果产生影响,这里先将各种填充(开始符或者结尾补齐的填充)mask成最小值
context = torch.matmul(attn, V) ### mask后在进行softmax,本来填充的地方就变成了0
return context, attn
将attn_mask矩阵中元素为T(True)的位置 对应的注意力矩阵scores矩阵中的位置元素置为极小值-1e9,在进行softmax,即可避免padding的影响
2.decoder中的mask。
有两个,作用也涵盖了mask的两种作用。decoder有三层,多头自注意层,多头编码-解码层,和前馈神经网络层
其一:在多头自注意层中,Q、K、V矩阵都来自于decoder的输入
针对decoder的输入 不仅要去除padding的影响,同时为了防止decoder看到未来的信息,要对输入做一个上三角mask
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) ### 得到的是mask掉句末padding的mask矩阵
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) ### 得到的是mask掉Encoder当前输入之后的信息的mask矩阵
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) ### 叠加上面两个mask的作用
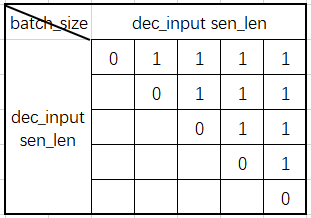
得到的三个矩阵分别如下
dec_self_attn_pad_mask:得到的是mask掉句末padding的mask矩阵
dec_self_attn_subsequent_mask:得到的是mask掉Encoder当前输入之后的信息的mask矩阵
dec_self_attn_mask: 叠加上面两个mask的作用
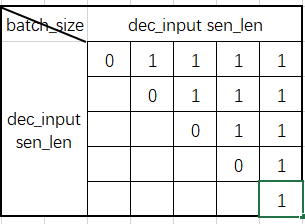
将计算得到的注意力矩阵进行mask,对1的元素位置填充极小值,然后softmax,去除padding的影响并将decoder当前输入 后面的信息进行遮盖。
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
其二:在多头编码-解码层中,Q矩阵来自于解码器的自注意层,而K、和V矩阵来自于Encoder的output,所以Encoder中的padding部分在编码-解码层中也要mask掉。
又因为encoder的输入和输出的sen_len 是一样的
有下得到mask,
def get_attn_pad_mask(enc_inputs, enc_inputs): ### 用来生产三个注意矩阵
# print(seq_q) ### encoder_inputs (是叠加了位置编码之后的embedding)
batch_size, len_q = seq_q.size() ### [1,5] seq_q: [batch_size,sen_len]
batch_size, len_k = seq_k.size() # eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k ###expand()函数,将tensor变形为括号内的维度。expand到的维度 将第一行的数据重复就行了
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
维度为[batch_size , dec_inputs_sen_len , enc_inputs_sen_len]
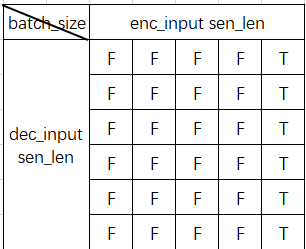
进行mask,消除encoder_input中padding位置的影响。
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
参考:
https://zhuanlan.zhihu.com/p/139595546
https://www.cnblogs.com/neopenx/p/4806006.html
Original: https://blog.csdn.net/weixin_42253689/article/details/113838263
Author: 咖乐布小部
Title: Transformer 中的mask
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531476/
转载文章受原作者版权保护。转载请注明原作者出处!